7.后端非线性优化
7.1 理论基础
7.1.1 bayes模型,因子图和最小二乘
这一部分主要是对
董靖博士在公开课《因子图的理论基础》上的回忆和总结。
(1)bayes模型
假设有黄色是机器人在不同时刻的位姿,蓝色是机器人观测到的路标点,红色是机器人对路标点的观测,绿色是机器人对自身运动的观测。
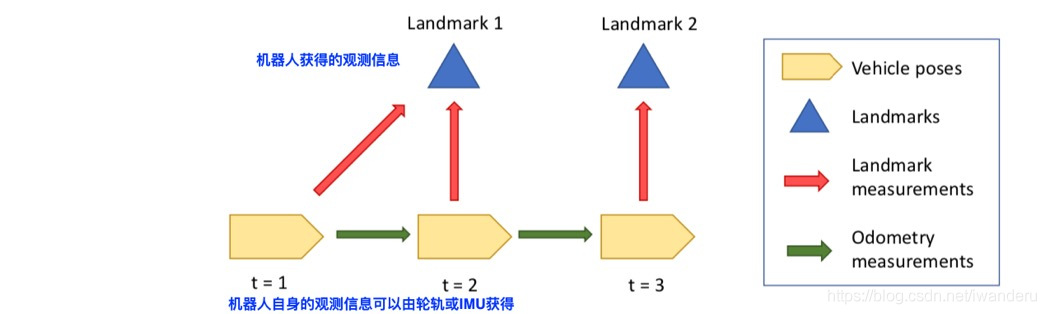
那么,这个过程可以用下面这个bayes-net来描述:
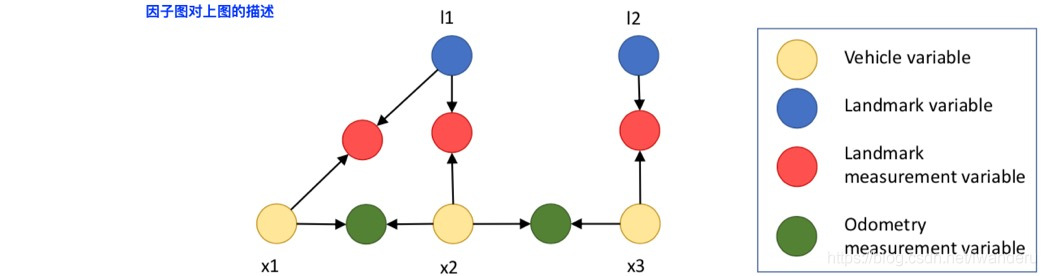
那么,可以有这样的定义:
黄色——机器人位姿——是状态量——X;
蓝色——路标点坐标——是状态量——X;
红色——机器人对路标点的观测——是观测量——Z;
绿色——机器人对自身运动的观测——是观测量——Z;
状态量X,对应着 待优化量,也就是g20里的vertex,ceres里的ParameterBlock;
观测量Z,对应着残差/因子,也就是g20里的edge,ceres里的ResidualBlock;
那么根据bayes法则,观测量Z和状态量X联合概率等于条件概率乘以边缘概率:
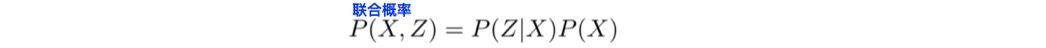
P(Z | X)是观测量Z对应的概率,也叫似然;
P(X, Z)是观测量Z和状态量X的联合概率;
P(X)是状态量的先验概率,比如说世界坐标系,这就是一个先验,假如说没有世界坐标系这个先验信息,那么系统整体性的漂移都能满足求解要求,那么就多了一个自由度的不可观。
而观测变量Z有一个特点,例如左一红圈,只跟状态变量x1和l1有关,而与路标点l2无关。其它的观测变量也有类似的特点,也就是
稀疏性和不相关性这两个特点,所以整体的观测P(Z | X)又可以以每一个单独的观测叠乘来获得。
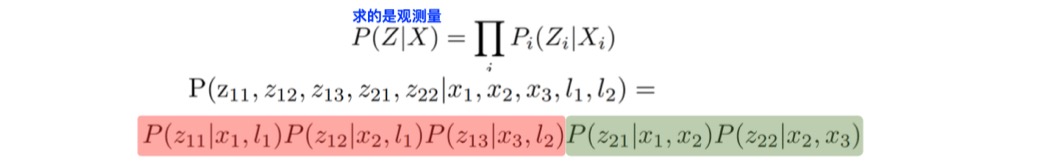 (2)因子图
(2)因子图
首先要明确我们的求解目标是P(X | Z)最大时,也就是在观测Z的情况下,对应的X;
因为往往状态量X是不知道的,而在状态X下的观测Z,也就是P(Z | X)是知道的;
所以,需要找到待求量P(X | Z)和已知量P(Z | X)之间的关系:
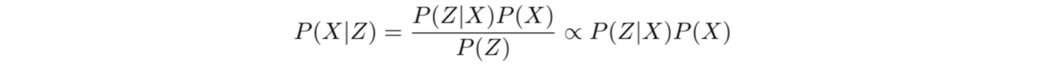
P(X | Z)等于上式中中间的式子,正比于右边的式子。
P(Z)是观测的先验信息,对应的是测量传感器的数学模型,例如相机,IMU,轮速器。
我们想找到这么一组状态量X,使得在当前观测Z的情况下,出现状态P(X | Z)的概率最大!
可以转换为求解,在当前状态下对应的观测P(Z | X)乘以一个状态量的先验P(X)!
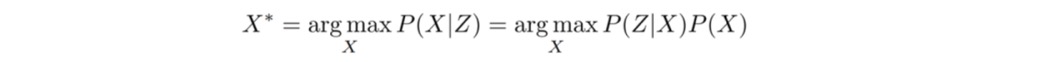
这就是传说中的,最大后验估计,转化为求似然乘以状态量的先验!
(3)因子的定义
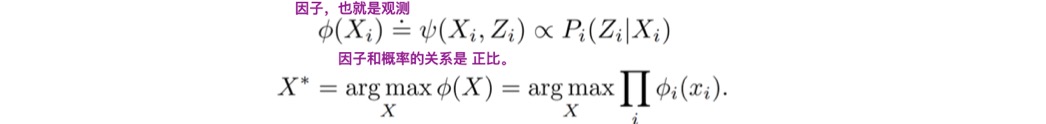
那么,
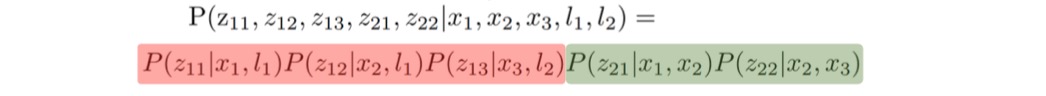
就可以转换为,
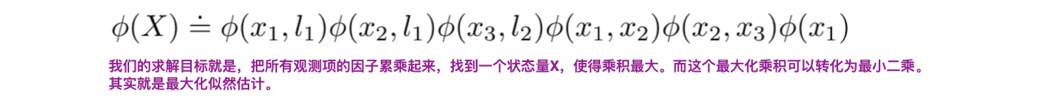
因子的定义如下:
 里面的f(xi)就是观测量的残差!也就是我们常说的IMU残差,重投影误差,先验误差等。
里面的f(xi)就是观测量的残差!也就是我们常说的IMU残差,重投影误差,先验误差等。
之所以用e的指数函数,因为传感器的测量噪声一般都满足gauss分布。
当因子连乘后,对应的最大似然估计就是最小二乘。
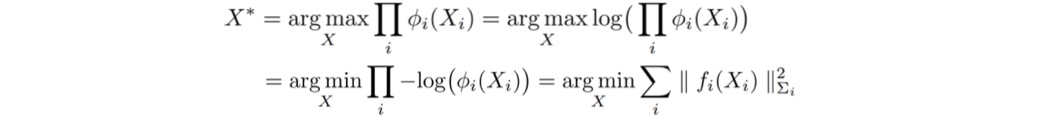 (3)残差,状态量,J,H的对应位置关系
(3)残差,状态量,J,H的对应位置关系
因子图它最方便的地方就是能一眼确定这是什么类型的残差,还能知道当前残差对哪个状态量X的J块是有值的,哪块是0的!
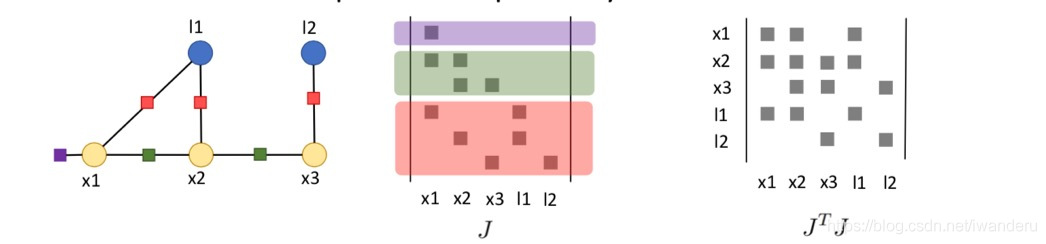
就比如说左一红色方框因子,我们能一眼知道是套用重投影误差模型,对应的J是什么公式早就有了;它连着x1和l1,说明只有这两个位置的J是有值的。
不过需要注意的是,
vins的因子图一般是下面这种形式的。同一个特征点是被2帧观测到的(重投影),而某一个IMU因子与相邻两帧的PVQ和bias相连的。
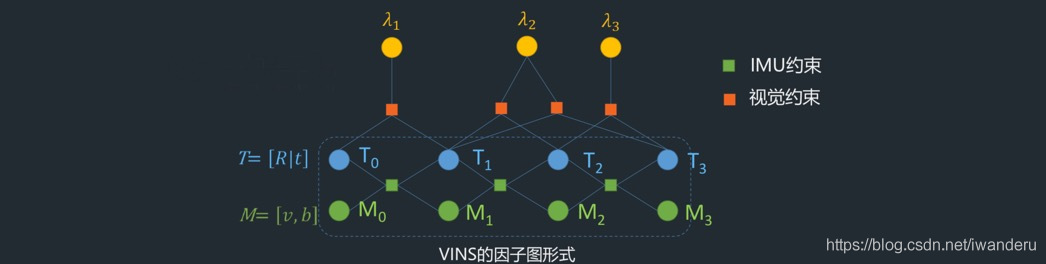
因此,往J大矩阵里面塞每一行非常方便!这也是g2o的逻辑,加状态量叫做加入vertex,加入一个残差,也就是J矩阵的一行,叫做加edge!
考虑到pose的数量远小于特征点的数量,在shur操作的时候一般会求pose部分的状态量,所以一般会把pose相关的edge放在J矩阵的上方。
7.1.2 后端模型
首先确定状态量X,
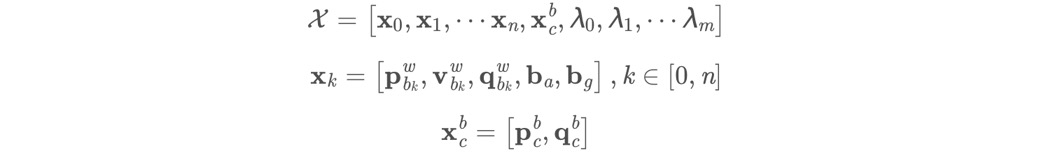
包括各帧的PVQ,bias,外参,特征点的逆深度。状态量的数量决定了H矩阵的维度和J矩阵的列数。PQ这两类状态是视觉和IMU都会优化的量。
目标函数为:
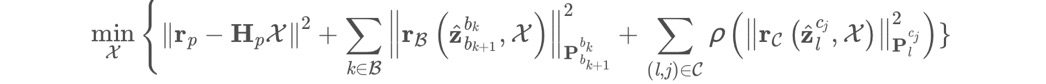
这三项分别为边缘化的先验信息、IMU的测量残差、视觉的重投影误差。这个目标函数就解释了vins系统为什么是紧耦合的系统,因为三个目标函数放在一起优化的!
对于这样的目标函数,可以构造一个下式所示的增量公式,迭代求解状态量X的最优解:
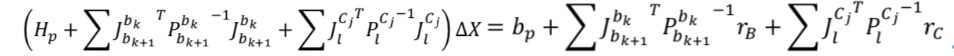
根据上一节内容,我们知道Jacobian和H是可以一行一行(若干行若干行)往里面加,接下来我们研究一下,怎么样往里面加。
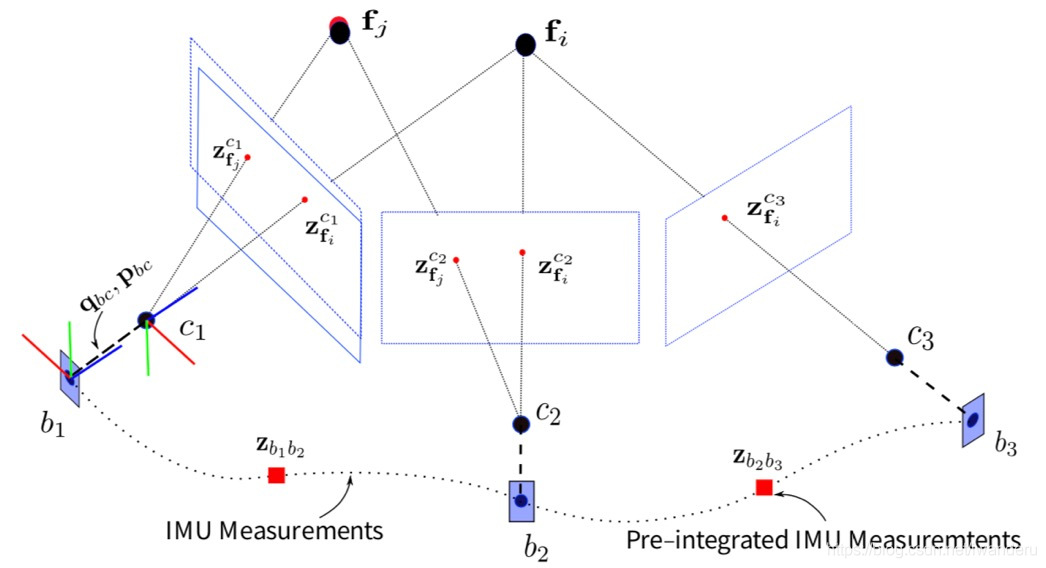
上面这个因子图非常经典地讲解了IMU约束和视觉约束。
(1)IMU约束部分
在4.1.1.IMU预积分部分,我们已经知道:
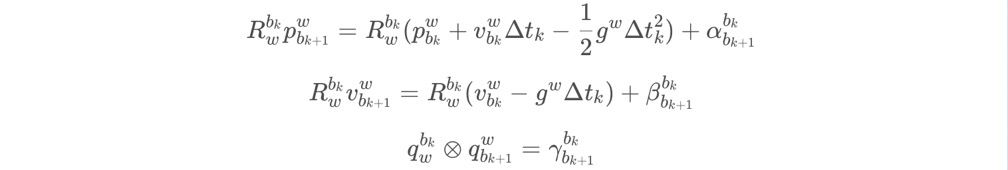
等号左边减去右边,就是IMU残差:
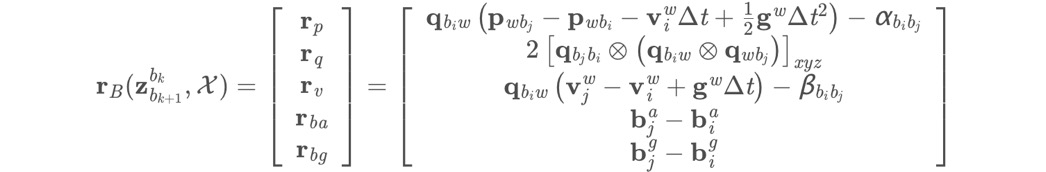
优化变量是相邻两帧 (第bk、bk+1时刻)p、q、v、ba、bg:
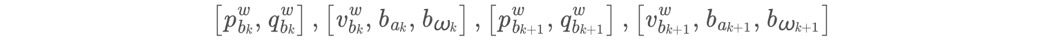
这一部分,残差是15维的,状态量是7+9+7+9维的,所以说,每增加一个IMU约束,总的Jacobian矩阵增加了15行,增加了7+9+7+9列!(需要注意的是,四元数是4维的,但是Localdemension是3维的)。
接下来,我们需要弄清楚,残差对状态量的Jacobian是什么,对应位置补充上这个J的矩阵块就行了,其他位置还是0。崔神的推到结果如下。
残差对bk时刻的PVQ的Jacobian:15*7
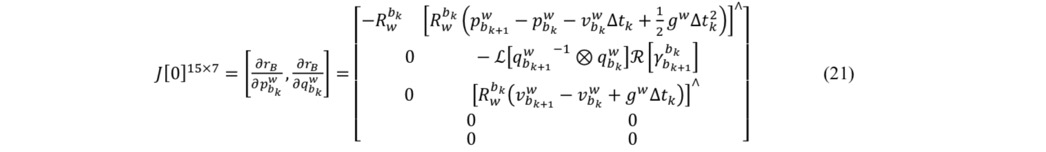
残差对bk时刻的的速度/bias的Jacobian:15*9
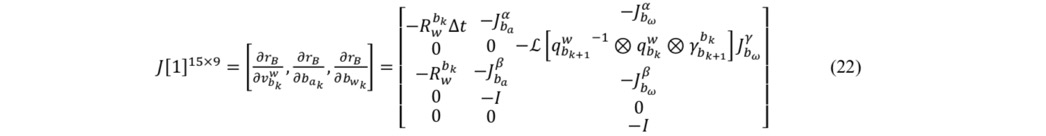
残差对bk+1时刻的PVQ的Jacobian:15*7
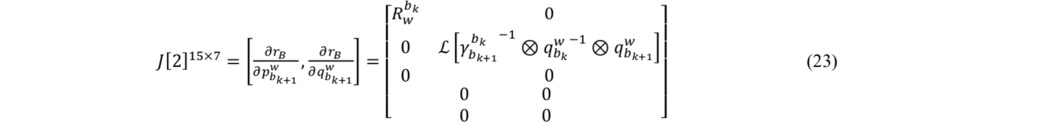
残差对bk+1时刻的的速度/bias的Jacobian:15*9

然后就是在构造对应的H矩阵块的时候,需要乘上信息矩阵,JT (Pk+1) J + uI,也就是4.2对应部分。
 (2)视觉约束部分
(2)视觉约束部分
这部分的残差就是重投影误差,注意是在归一化平面上表示的:
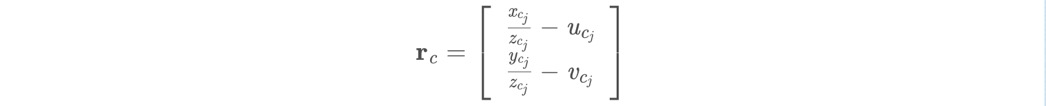
但是和纯视觉不同的地方是,待优化的状态量X中的旋转平移,都是IMU系到w系到,而不是camera系到w系的:
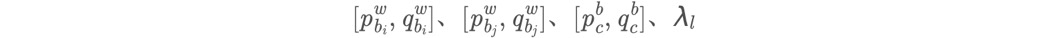
这里的状态量有两个特点:
待优化量和IMU约束部分的待优化量有重叠,再次体现了紧耦合;
和IMU不同的是,IMU每次优化的状态量是相邻两帧的,但是视觉优化的2帧不一定是相邻的,因此用i,j表示。
特征点在归一化相机坐标系与在相机坐标系下的坐标关系为:
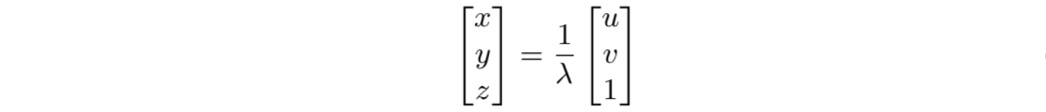
这块没有采用深度,而采用逆深度,因为逆深度满足高斯分布。
对于第 l 个路标点 P,将 P 从第一次观看到它的第 i 个相机坐标系,转换到当前的第 j 个相机坐标系下的像素坐标:
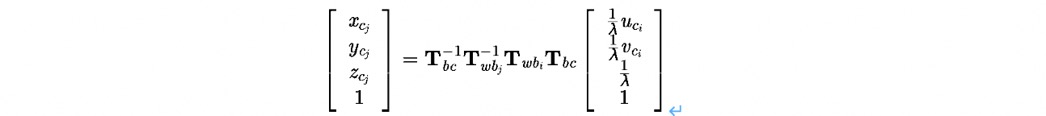
这个转换过程,经历了从ci坐标系-> bi坐标系->w坐标系-> bj坐标系-> cj坐标系这个过程。
上面这个等式,也就是:
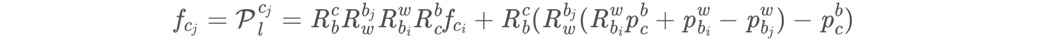
那么,在归一化平面上的重投影坐标就是fcj = [xcj/zcj, ycj/zcj],重投影误差就是开头的公式。
这一部分,残差是2维的,状态量是7+7+m维的,所以说,每增加一个视觉约束,总的Jacobian矩阵增加了2行,增加了7+7+m列!(需要注意的是,四元数是4维的,但是Localdemension是3维的)。
因为根据链式法则,对Jacobian的计算可以分成:
1)视觉残差对重投影3D点fcj求导。
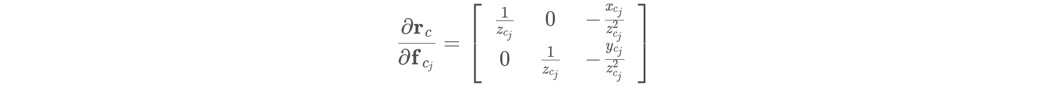
2) 再乘上fcj对各个优化变量求导。
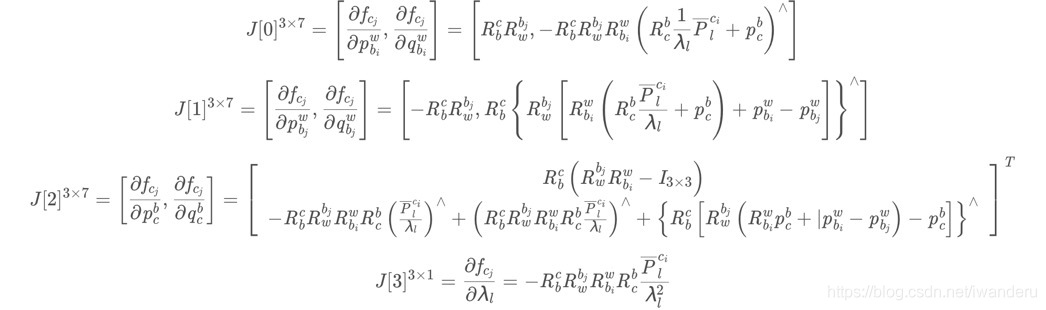
然后就是在构造对应的H矩阵块的时候,需要乘上信息矩阵,JT (Pk+1) J + uI,视觉约束的协方差与标定相机内参时的重投影误差有关。VINS在代码中sqrt_info取1.5个像素,对应到归一化相机平面还需除以焦距f,最后得到的信息矩阵:(这里真正的信息矩阵其实是sqrt_info的平方)
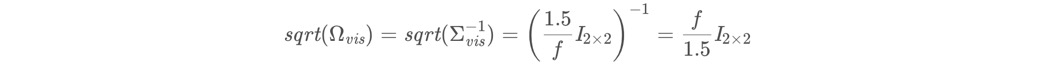 (3)先验约束部分
(3)先验约束部分
放在8.1节介绍。





评论(0)
您还未登录,请登录后发表或查看评论