轻量级实时语义分割:Guided Upsampling Network for Real-Time Semantic Segmentation
- 介绍
- 网络设计
- Guided unsampling module
- 实验部分
- 总结
介绍
论文贡献
- 提出一个新颖的名为Guided Upsampling Network多分辨率网络架构,512x1024分辨率图像在GPU可达到33FPS的速度,且在cityscapes达到70.4%IoU.
- 用增量式的方式筛选出每一个选择的好处与坏处,让实验更容易重复。
- 设计了GUM(Guided Upsampling Module),有效地利用上采样过程中的高分辨率线索。
最近工作中值得注意的是SegNet,ENet,ICNet,ERFNet这些轻量级网络。其中ENet和ERFNet已经在上期博客中讲过。
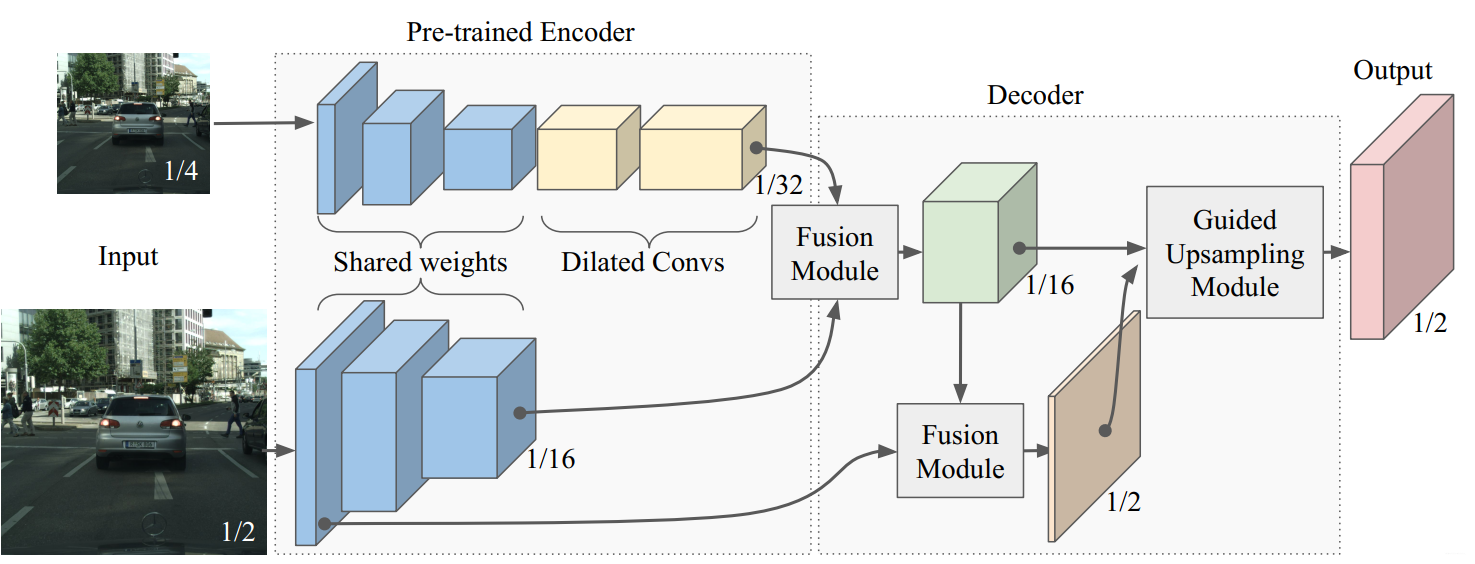
网络设计
作者采用一种增量式、递进式的研究方法,从一个baseline模型开始,不断地加一些处理方式并分析利弊。
一、Input downsampling
一个天真的方法就是采用下采样使处理速度加快,但容易丢失精度。作者采用DRN-D-22在imagenet的预训练模型为encoder并且使用简单的双线性插值化作为decoder。
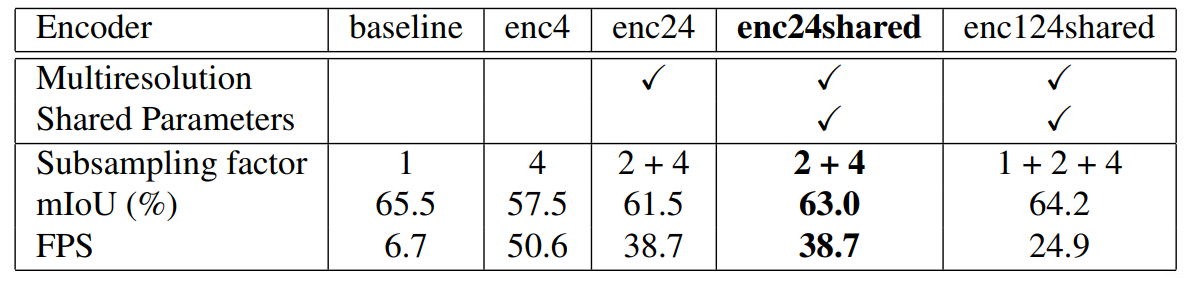
下图显示了baseline和使用下采样输入训练和评估,并加入不同的factor得到的结果。可见FPS从6.7到50.6但精度少了8%,这是难以接受的。
 二、Multiresolution encoder
二、Multiresolution encoder
作者设计了一个多分辨率架构防止精度流失。encoder分为两个branchs:一个使用DRN-D-22(Dilated Residual NetWork 22 type D)除了最后两层的低分辨率branch。一个是在dilated 卷积之前,只有DRN-D-22的第一层的中分辨率branch。第一个branch主要目的在于解析更大的上下文特征,第二个branch目的则是解析更多局部特征帮助恢复decoeing细节。
作者对三个不同的encoder 配置做了实验,enc24表示处理之前所定义的sub-sampling factors 2和4(这里没搞明白),enc24shared则表示对两个分支进行权重共享。实验发现,shared权重的版本更好。作者认为通过减少网络参数的数量,分支之间的权值共享,引出了一种隐式的正则化形式。衡量精度与速度,最终作者采用了enc24shared作为下一步改进的baseline版本。
三、Fusion module
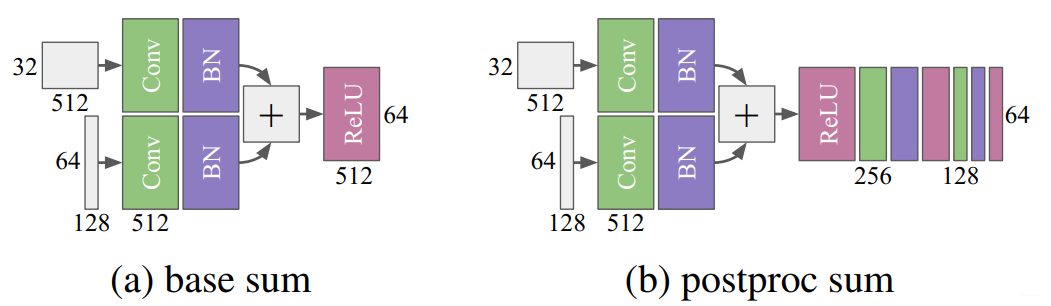
融合的第一步就是将encoder两个branchs结合起来。作者实验了add和concat两种融合策略。同时也试验了两种融合策略如下图所示。
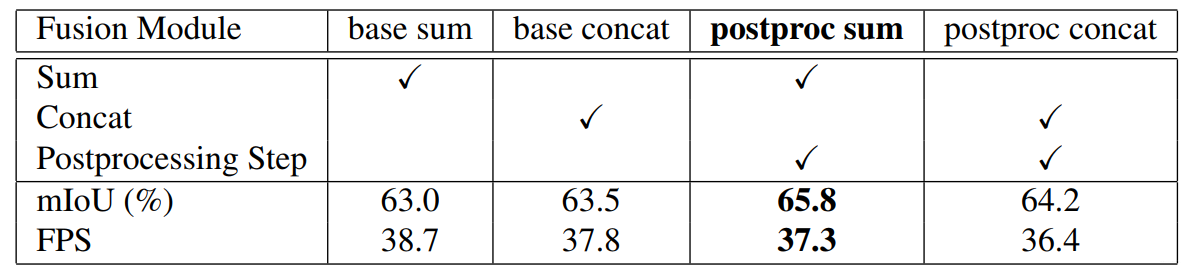
实验结果如下图所示:
四、数据增强
由于系统是在室外的场景跑的,有光线的干扰。于是作者先对光线进行了转换。
色彩抖动是指以随机顺序修改图像的亮度、饱和度和对比度。
Lighting抖动是一种基于PCA的[13]噪声抖动,我们使用
σ = 0.1 \sigma= 0.1σ=0.1作为标准差来产生随机噪声。
同时也进行了几何转换:使用0.5到2之间的比例因子重新标定图像,借用[23]的值。

最终发现只有几何转换有效,故下一步使用其作为系统的一部分。
Guided unsampling module
很多语义分割算法没有预测完整的分辨率图,这些算法产生了低于输入的分辨率,且上采样往往采用无参数方法,如最近邻法或二元插值法。
使用这些方法的缺点在于接近对象边界的像素经常被分配到错误的类。如下左图,Predicted Map上面的像素点恰好处于物体边缘,直接上采样容易被分错。
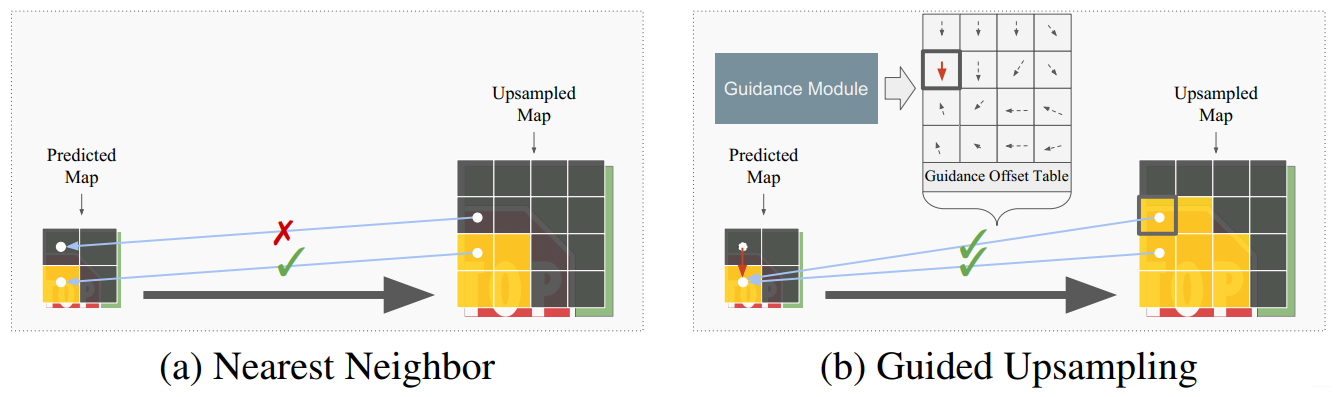
作者认为,通过独立预测每一个单个像素来生成语义地图是非常低效的。GUM背后的想法是
通过偏移向量的指导表来引导上采样操作,该指导表将采样引向正确的语义类。 一个引导模型预测的是一个
较高分辨率的指引偏移表。GUM执行最近邻上采样操作通过利用偏移表。
作者其实做了两件事情,一件事就是生成高分辨率的指引偏移表,另一件事就是使用指引偏移表进行上采样操作。
首先说说,如何使用指引偏移表进行上采样操作。
这里不得不提起15年NIPS上的一篇论文《Spatial Transformer Networks》。
STN(Spatial Transformer Networks)对feature map(包括输入图像)进行空间变换,输出一张纠正过的理想图像,再使用神经网络进行识别。
此处参考:
https://www.cnblogs.com/aoru45/p/11488935.html
https://www.cnblogs.com/liaohuiqiang/p/9226335.html
“如下图所示,输入模型的图像可能是摆着各种姿势,摆在不同位置的凉宫春日,我们希望STN把它纠正到图像的正中央,放大,占满整个屏幕,然后再丢进CNN去识别。”
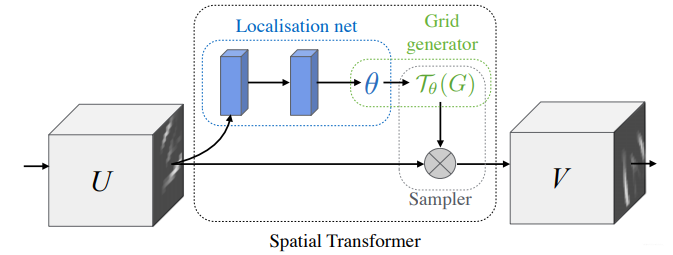
 STN网络框架
STN网络框架


 然后,我们再说说如何生成高分辨率的指引偏移表。
然后,我们再说说如何生成高分辨率的指引偏移表。
很简单,就是把生成偏移表当成是神经网络的一个分支,从而使整个网络的参数可以通过端到端的反向传播进行训练。
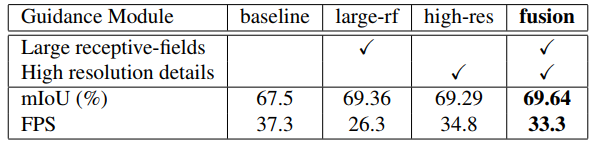
并对GM模块进行了三种不同设计:large-rf,high-res和fusion。并对他们进行验证,最后fusion模块实验效果更好,其由两个卷积-BN层与一个上采样层组成。
实验部分
作者在Titan Xp GPU上跑了如下结果。使用的是Cityscapes的数据集。
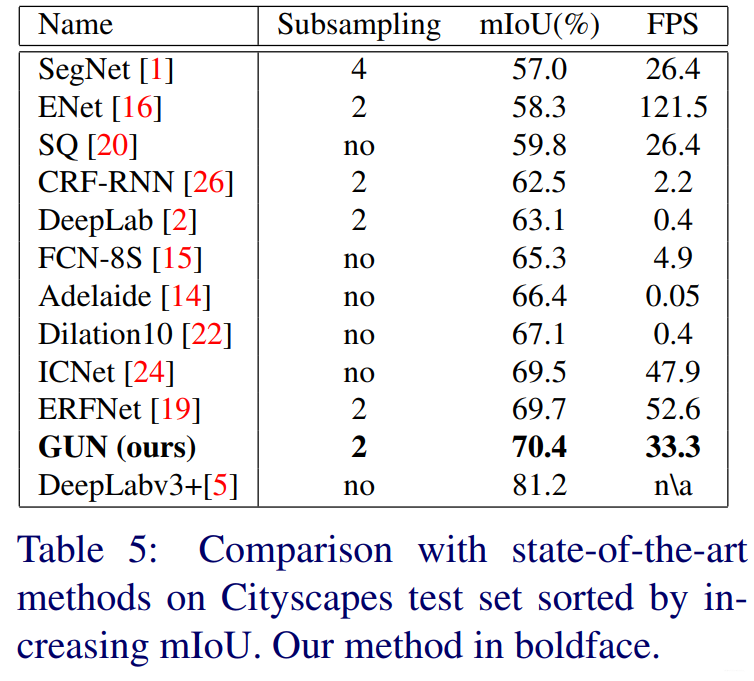
总结
总结一下GUN主要做的几件事情,首先使用两路高低分辨率图像进行特征学习(前一部分的卷积核是shared的),然后对两者使用sum+post-process方式进行融合,在这个过程也学习了一个上采样指引表(受STN思路启发),再上采样步骤时使用上采样指引表达到更好的效果。





评论(0)
您还未登录,请登录后发表或查看评论