排序学习一般被认为是
supervised learning中的一个特例,谈到
supervised learning其
loss function一般表示为如下形式:
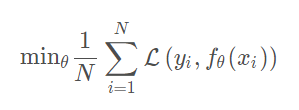
supervised learning中我们首先想到的是
Regression 和
Classification,其
loss function分别表示为如下形式:
Regression经常以
mean-square-error构建
loss function
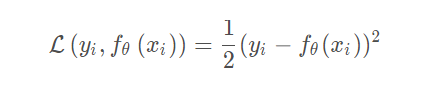
Classification常以
cross-entropy构建
loss function
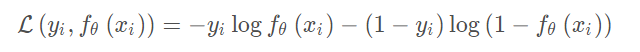
上述的
loss function都是建立在一个
instance个体本身上面,而不是一群
instance上面。
Learning to Rank Problem
而这个
Learning to Rank就比较有意思,输入是
a set of instances:
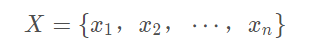
输出是
a rank list of these instances:
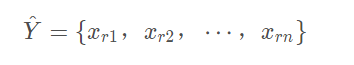
其中下标表示的是排序位置,比如
r 1 = 1,表示
x 1 排在第一个位置,
r 1 = 2 ,表示
x 2排在第一个位置。
真实标签就是
a correct ranking of these instances:
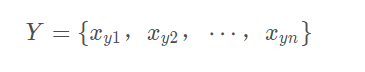
Learning to Rank就是在一系列
instances下面做
supervised learning
Information Retrieval
Information Retrieval更广泛的意思是说,我们有一个
user。他有一个
information need ,希望在
a collection of information items里面通过索引、排序等方法,然后返回一些相关的
items给用户。
A Typical Application: Web Search Engines
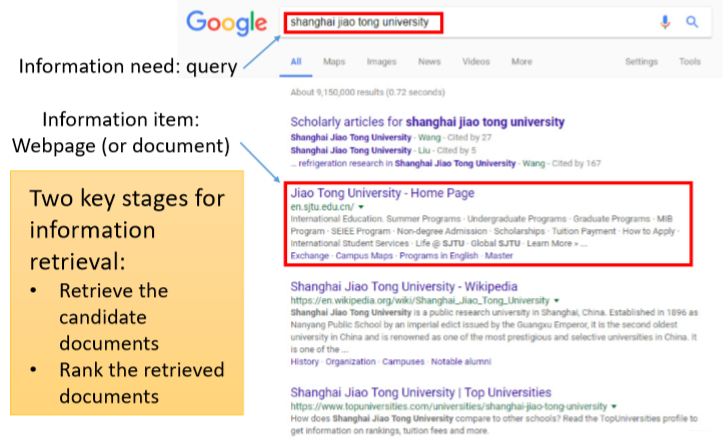
当我们每天在做检索的时候其实也在反馈,他们的
rank应该如何去做会更好一些。
在上述过程中有
Two key stages索引检索相关的候选文档和排序这些文档。
- Retrieve the candidate documents
- Rank the retrieved documents
而
Rank the retrieved documents我们可以用
Learning to Rank的方式来做。由于
Learning to Rank不可能对所有的
documents排序,因此有第一步索引。
- Overview Diagram of Information Retrieval
整个
Web Search Engines其大体的核心步骤可描述为下图所示:
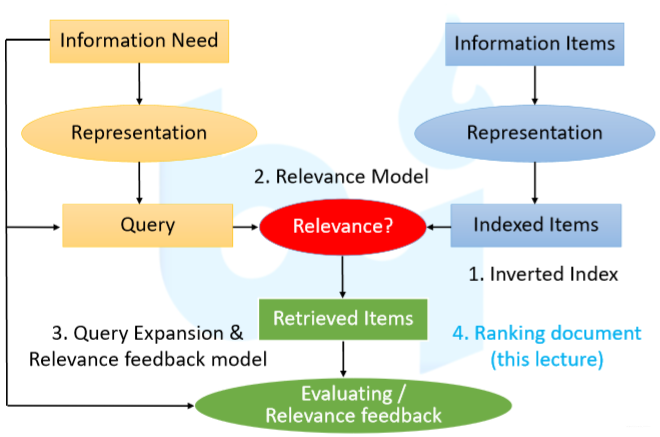
- Inverted Index
给一个文档,需要知道有哪些关键词
- Relevance Model
当用户输入一个
query之后,依据
Inverted Index我们可以找到一些候选集,
- Query Expansion & Relevance feedback model
这里所做的是对
Query的一个扩充,比如拿前十名的文档对关键词进行扩充,能够使得
Query更加全面,排序结果更加稳定,返回更好的
user的
information need。
- Ranking document
最后去做
Learning to Rank的这个
model,使得排序结果更好,更好的服务于用户。
Webpage Ranking
整个
learning to rank的
framework如下图所示:
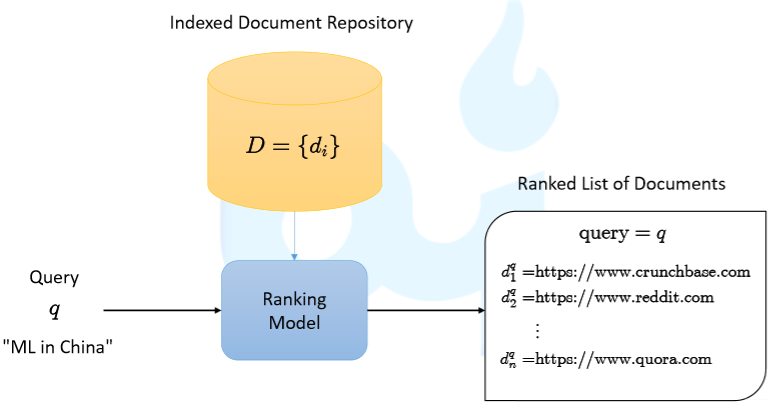
当
user输入
query时,第一步是获得
Retrieved Items,之后基于这个
Retrieved Items做
ranking model,然后输出
Ranked List of Documents。
Learning to Rank
Model Perspectiv
目前大部分
learning to rank的工作建模为两方面的问题,
query-document以
feature的形式建模出来。
- Each instance (e.g. query-document pair) is represented with a list of features
有时候的
query是非常离奇的,搜索引擎从来没有见过,因此我们需要将
query映射到
feature space上面。
这里主要是当给一个
query-document pair我们需要
Estimate the relevance,也就是一个打分函数
f θ f_{\theta}fθ:
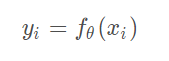
之后需要基于
the estimation去
Rank the documents。基于这个
rank与真正的
rank做
loss function,再
train就可以了。
总结一下在
Learning to Rank的
framework下面:
- 输入:features of query and documents 像Query, document, and combination features这些
- 输出:the documents ranked by a scoring function y i = f θ ( x i ) y_{i} = f_{\theta}(x_{i})yi=fθ(xi)
- 目标函数是一些
relevance of the ranking list,像Evaluation metrics: NDCG, MAP, MRR…这些。
- 训练数据:
the query-doc features and relevance ratings,数据格式如下图所示:

可以看出
query已经被转成了数字化的
feature了。这样的话即使没有见过这个
query,没有见过这个
documents,我们依然能够在
feature space上面去建模这个点。
在
Learning to Rank上面我们其实是学习
scoring function。
Learning to Rank Approaches
微软亚洲研究院副院长
Tie-Yan Liu在
2011的《
Learning to Rank for Information Retrieval》中将
Learning to Rank大致分为三类:
Pointwise、
Pairwise、
Listwise
Pointwise
- Predict the absolute relevance (e.g. RMSE)
Pointwise方法中对单个
instance打分,问题就变成了一个回归问题:
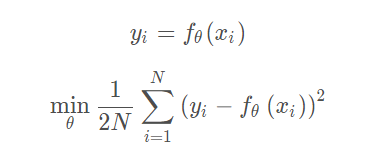
这是最简单的
Learning to Rank,这里有一个问题,
Point Accuracy !=
Ranking Accuracy。Same square error might lead to different rankings,如下图所示:
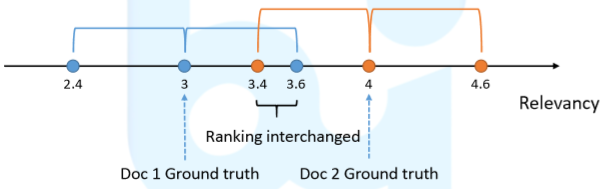
也就是说最后所作的优化并不是rank上的优化。
Pairwise
- Predict the ranking of a document pair (e.g. AUC)
对于排序问题,如果
scoring functionf θ f_{\theta}fθ改变一点点,那是很有可能导致你最终的排序结果不会发生改变。当
loss function建立在排序上面的话,那么你的
loss function对函数参数求导就会等于
0。
正是由于这个原因,我们无法对scoring function求导。解决办法如下图所示:



- Burges, Christopher JC, Robert Ragno, and Quoc Viet Le. "Learning to rank with nonsmoothcost functions."NIPS. Vol. 6. 2006
Pairwise Approaches也存在一些问题,如:
Each document pair is regarded with the same importance。但是很多时候,用户对前面几个页面的
rank是要更加关注一点,因此
Same pair-level error but different list-level error就需要注意。

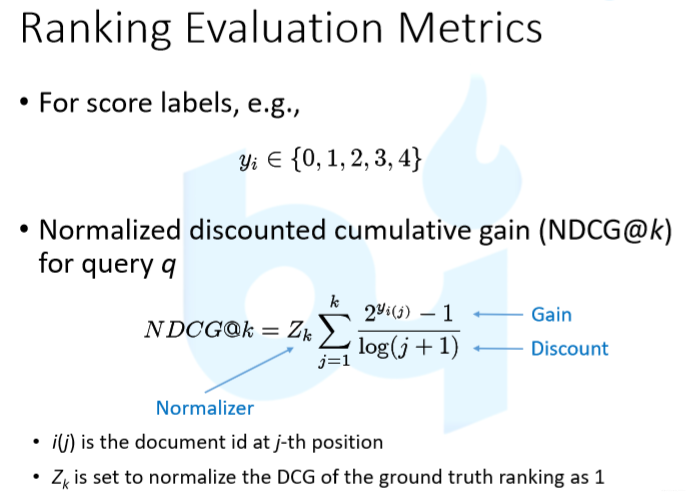

Listwise
- Predict the ranking of a document list (e.g. Cross Entropy)
Listwise Approaches
- Training loss is directly built based on the difference between the prediction list and the ground truth list
- Straightforward target •Directly optimize the ranking evaluation measures
- Complex model

- Cao, Zhe, et al. "Learning to rank: from pairwise approach to listwise approach."Proceedings of the 24th international conference on Machine learning. ACM, 2007.


- Burges, Christopher JC, Robert Ragno, and Quoc Viet Le. "Learning to rank with nonsmooth cost functions."NIPS. Vol. 6. 2006.
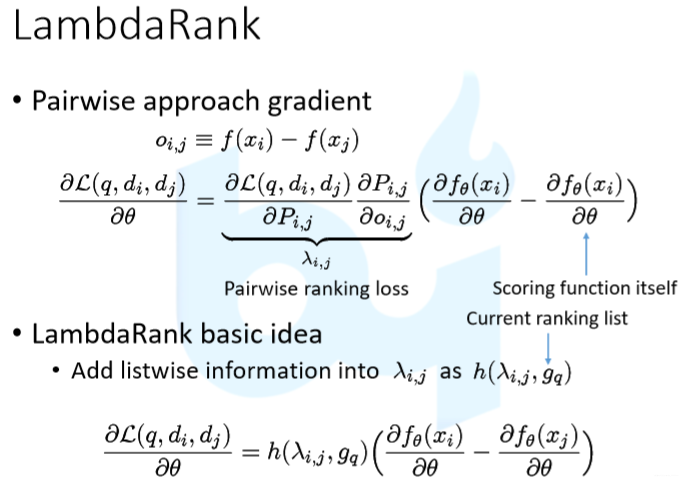

Summary of Learning to Rank






评论(0)
您还未登录,请登录后发表或查看评论