

文章目录
-
- PAC学习模型
-
- 定义 Generalization error :
- 定义 Empirical error :
-
- Learning axisaligned rectangles
- PAC learning
- Guarantees for finite hypothesis sets — consistent case
- Guarantees for finite hypothesis sets — inconsistent case
- Generalities
- 参考
- PAC学习模型
- 怎么样才能学习地更有效率?
- 什么样的问题天生很难学?
- 需要多少样本才能学好?
- 所学出来的
model泛化能力好吗?
PAC学习模型
这就是PAC要做的事情,解决上述疑问。PAC英文全程Probably Approximately Correct。在开始介绍这个framework之前需要定义一些notation:
- X:
examples或称为instances的集合,有时也代表输入空间。 - Y:
labels或者称为target的集合。 - c :X→Y:称之为一个概念(
concept),由于是一个二分类问题,所以c 可以被定义为X中label全为1的一个子集。 - C: 所有的概念(
concept)组成concept class,是需要去learn的。
binary classi cation问题,之后扩展到更一般的情形。假设样本是独立地满足一个固定但是未知的分布D \mathcal{D}D。
从D \mathcal{D}D中sample一些样本S=(x1,⋯,xm)和它的标签(c(x1),⋯,c(xm)),之后基于这些带label的样本选择hypothesis hS∈H,使得其泛化误差(generalization error)最小。
定义 Generalization error :
给定hypothesish∈H,target concept c∈C和一个潜在distribution D,generalization error或者h 的risk被定义为:
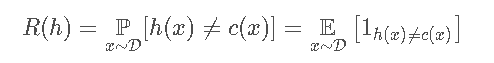 可以看出某个
可以看出某个hypothesis的generalization error并不是全部由learner所导致的,与distribution D D和 target concept c cc 都有关系。
定义 Empirical error :
给定一个hypothesis h∈H,一个target concept c∈C,一个sample S=(x1,⋯,xm),empirical risk被定义为:
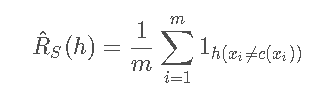 可以看出
可以看出empirical risk是sample下的平均error,而generalization error是在distributionexpected error。
对于一个固定的h∈H,基于独立同分布采样得到的期望empirical error与generalization error是相等的:
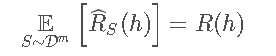
Learning axisaligned rectangles
考虑这样一种情况,样本是平面上的一些点,X∈R2,概念类(concept class)是R2中所有的与轴平行的矩形,因此每个concept c 是轴平行矩形中的点,矩形内部为1,外部为2。要学习的问题就是基于有label的训练数据确定能够最小error的轴平行矩形框:
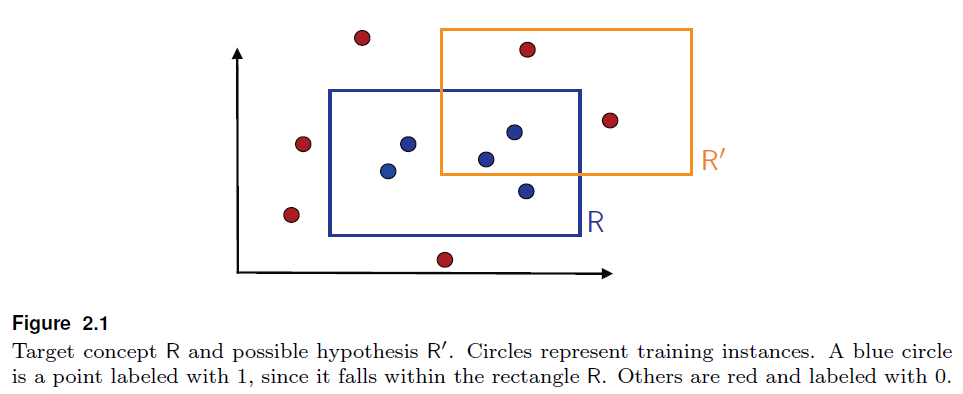 如上图所示R 表示目标
如上图所示R 表示目标axisaligned rectangles,R′是hypothesis。如上图所示误差主要来自两部分:
false negatives:在矩形R 内,但是不在矩形R′内。也就是实际label为1的被R′标记为0。
false positives:在矩形R′内,但是不在矩形R 内。也就是实际label为0的被R′标记为1。
tightest axis-aligned rectangle) R′=Rs ,包含了label为1的样本,如下图2.2所示:
 依据定义可知,Rs中不包含任何
依据定义可知,Rs中不包含任何false postives,因此Rs错误的区域(region)被包含在R 中。
记R∈C为target concept。固定ε>0。P[R]被定义为随机从分布D中采一个点,落入到R内的概率。因为由算法所导致的误差的点只会落入到R内,所以假设P[R]>ε。
定义好了P[R]>ε之后,再定义四个延边矩形r1,r2,r3,r4,每个的概率至少都是ε/4。这些region可以从整个矩形R RR开始构造,然后移动其中的一条边,使其尽可能地小,但是要保证其distribution mass至少都是ε/4,即P[ri]≥ε/4。如下图所示:
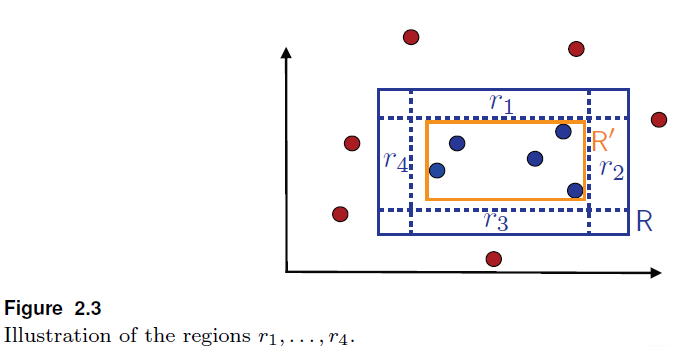 令l ,r ,b 和t 是四个真实的值,R 定义为:R=[l,r]×[b,t]。那对于左边的r4区域可以被定义成r4=[l,s4]×[b,t],其中s4=inf{s:P[[l,s]×[b,t]]≥1/4}。
如果RS与四个沿边矩形ri都有交集,因为其是矩形,所有每个
令l ,r ,b 和t 是四个真实的值,R 定义为:R=[l,r]×[b,t]。那对于左边的r4区域可以被定义成r4=[l,s4]×[b,t],其中s4=inf{s:P[[l,s]×[b,t]]≥1/4}。
如果RS与四个沿边矩形ri都有交集,因为其是矩形,所有每个regionri中都有RS的一条边,也就是RS一定在矩形R 内,即R(RS)≤ε。相反,如果R(RS)>ε,那至少有一个regionRS没有边相交。可以写成:
 也就是没有样本点在沿边矩形ri的内部或者边上。上式中我们使用了一个通用的不等式1−x≤e−x,对于任意δ>0,要使得
也就是没有样本点在沿边矩形ri的内部或者边上。上式中我们使用了一个通用的不等式1−x≤e−x,对于任意δ>0,要使得 要注意的是这里的
要注意的是这里的hypothesis set H是无限的。上述证明PAC-learnable用了矩形的几何关系,是整个证明的key,上述的证明过程泛化能力并不是很强。之后会在finite hypothesis set下证明更一般的情形。
PAC learning
在开始证明之前,我们需要先来了解一下这个PAC-learning定义:
 如果存在一个算法A和一个多项式函数plot(⋅,⋅,⋅,⋅),对于任意的ε>0和δ>0,对X上所有的分布D和任意一个
如果存在一个算法A和一个多项式函数plot(⋅,⋅,⋅,⋅),对于任意的ε>0和δ>0,对X上所有的分布D和任意一个target concept c∈C,当样本m≥ploy(1/ε,1/δ,n,size(c))时,有:
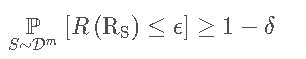 也就是在很大概率(1−δ)上是近似正确的(误差为ε )。
有一些关键知识点:
也就是在很大概率(1−δ)上是近似正确的(误差为ε )。
有一些关键知识点:
PAC框架是与分布D无关的,因为其没有对分布做任何假设。- 样本是从相同的分布D中采样得到的。
PAC框架处理的是概念类(concept class) C(is known to the algorithm),而不是目标类(target concept) c∈C (is unknown)。
Guarantees for finite hypothesis sets — consistent case
在axis-aligned rectangles的例子中,算法给出的hypothesis hS总是consistent,也就是说在training sample S 上是没有error的。针对consistent hypotheses情形来证generalization bound,假定target concept c 在H中。
- 定理(
Learning bound有限H,consistent情况下):H是X到Y的一个有限集合。A是一个从任意target conceptc ∈ H ,样本S 满足独立同分布,的一个学习算法,返回一个consistent hypothesish S : R^S(hS)=0。对任意的ε , δ>0,如果
 用
用generalization bound来描述:对于任意ε , δ,至少以概率1−δ:
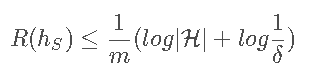 Proof:固定ε>0,定义H :R(h)≥ε}(泛化误差的含义是对随机一个样本,预测错误的概率。),对于h∈HE,它在
Proof:固定ε>0,定义H :R(h)≥ε}(泛化误差的含义是对随机一个样本,预测错误的概率。),对于h∈HE,它在training sample S 下的consistent(每个样本误差为0的情况)可表示为:
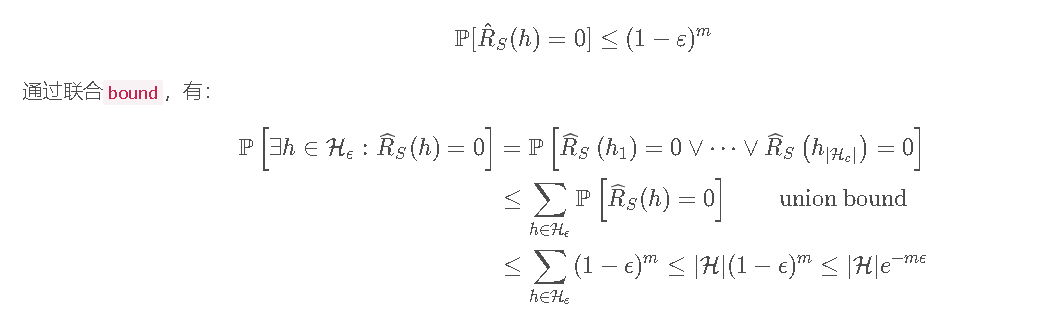 又有(事件的包含关系,左边事情发生,则右边事情一定发生):
又有(事件的包含关系,左边事情发生,则右边事情一定发生):
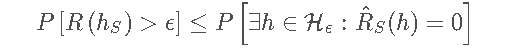 令等式右边等于δ即可得证。
令等式右边等于δ即可得证。
Guarantees for finite hypothesis sets — inconsistent case
上一小节的证明是在consistent情况下的证明,然而在大多数情况下是达不到这样一种情况的。更一般的假设可以采用Hoeffding inequality来得到generalization error和empirical error之间的关系。
Corollary(推论):固定ε>0,对于任意hypothesish:X→{0,1},有以下inequalities:
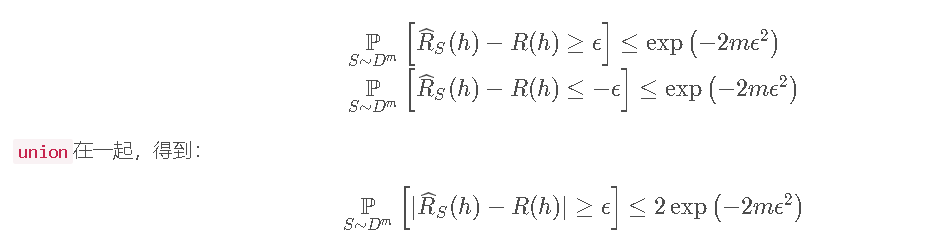 Theorem(
Theorem(learning bound - finite H, inconsistent case):H是一个finite hypothesis 集合。对于任意δ>0,有概率至少1−δ以下式子成立:
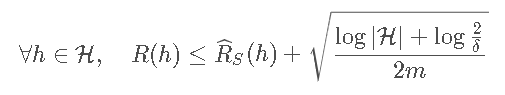
Proof:h1,⋯,hH是H中的elements。采用corollary将其union在一起得到:
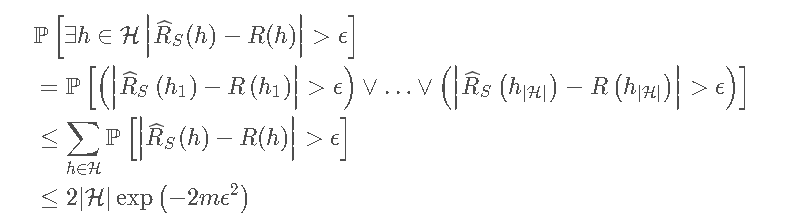 令右边等于δ 得证。
令右边等于δ 得证。consistent在上述等式下也是成立的,这是一个更加松的bound。从这里就可以得到hypothesis的大小,样本大小和误差之间的关系。
Generalities
更一般的情况,输出的label是输入数据的一个概率,比如说输入身高和体重预测这个人的性别这种问题。也就是说label是一个概率分布这样。
- 定义
Agnostic PAC learning:
 如果
如果label可以被某个function f : X→Y 独一无二地确定下来,将其称为deterministic,会存在某个target function使得generalization error R(h)=0,在stochastic情形下就不存在说会使得某个hypothesis下的error为0:
- 定义(
Bayes error):给定distribution D,Bayes error R∗被定义为measurable function h : X→Y的误差下界:
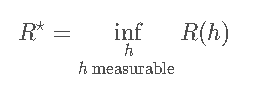
hypothesis h withR(h)=R∗被称作Bayes hypothesis或者是Bayes classi er。通过定义可知,在deterministic的情况下R∗=0,但是在stochastic的情况下R∗=0。
Bayes classi er h Bayes可以被定义成以下条件概率的情形:
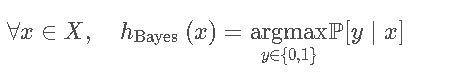
The average error made hy h Bayes on x∈X is thus min {P[0∣x],P[1∣x]},and this is the minimum possible error. This leads to the following definition of noise。
参考
- Mohri, M., Rostamizadeh, A., & Talwalkar, A. (2018).Foundations of machine learning. MIT press.
- https://zhuanlan.zhihu.com/p/66799567



评论(1)
您还未登录,请登录后发表或查看评论