机器语音理论识别模型:
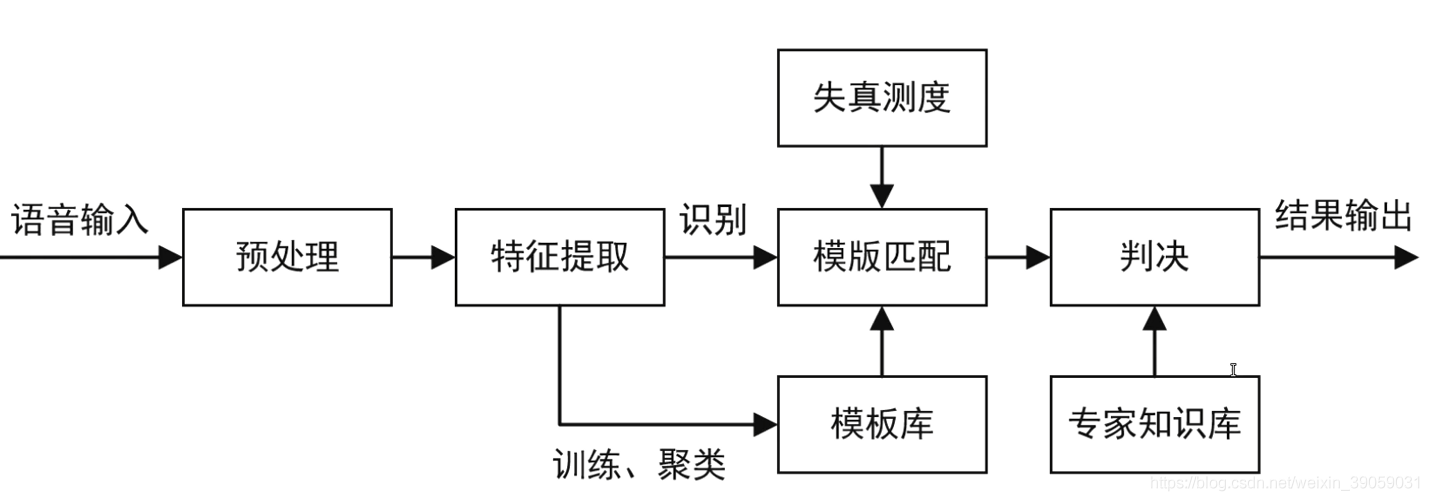
在ros里面有一些语音识别的功能包
pocketsphinx:集成CMU Sphinx和Festival开源项目中的代码,实现语音识别的功能。只能识别数据库中的语音。
audio-common:提供了文本转语音(Text-to-speech TTS)的功能实现完成“机器人说话”的想法。
AIML:人工智能标记语言,Artificial Intelligence Markup Language,是一种创建自然语言软件代理的XML语言。
我们其实就可以使用以上三个功能包去实现在ros系统里面的人机对话。我们首先语音识别,之后调用自然语言处理包,再将文本转化成语音。在这本书《ROS ROBOTICS PROJECTS》里面可以找到更详细的解释。
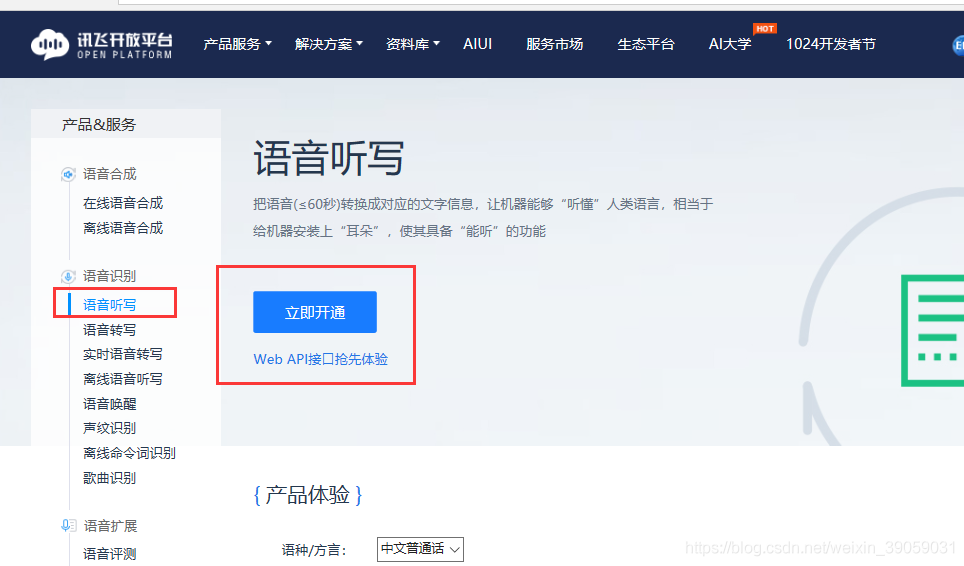
这里我们用一下科大讯飞的SDK实现功能:
1.去科大讯飞官网https://www.xfyun.cn/,注册一个账户,并下载SDK。
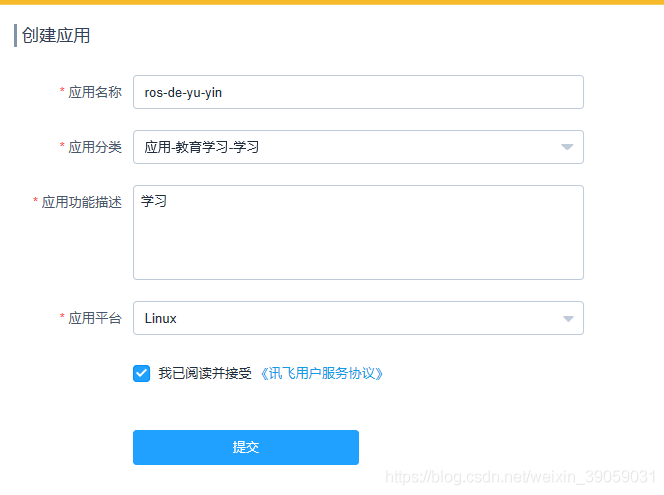
然后创建应用,填个表:
之后下载SDK。

这里需要记住APPID,
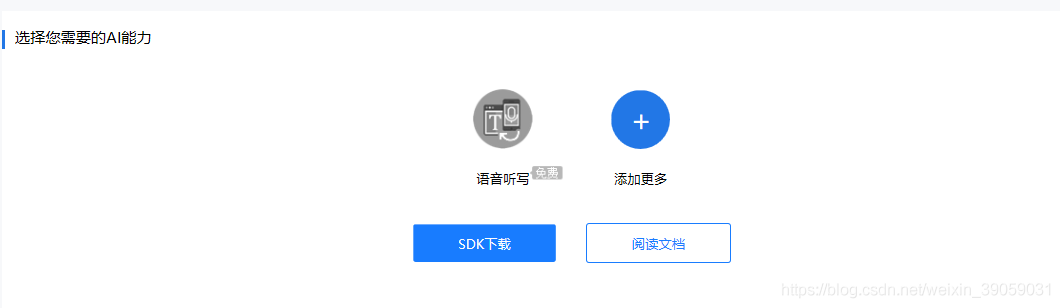
之后我们选择语音听写,然后下载它就好了。我们将其解压缩之后放入到后面的文件夹里面:
我们进入到其中某个例子文件目录下面:
把下面这个文件路径改一下:
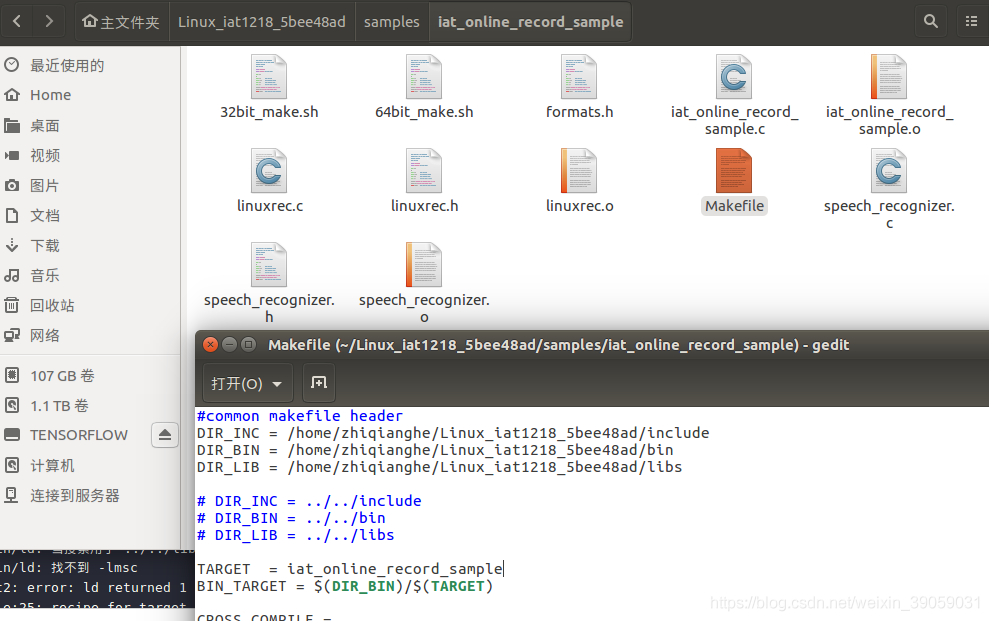
这个64位的文件内容如下:
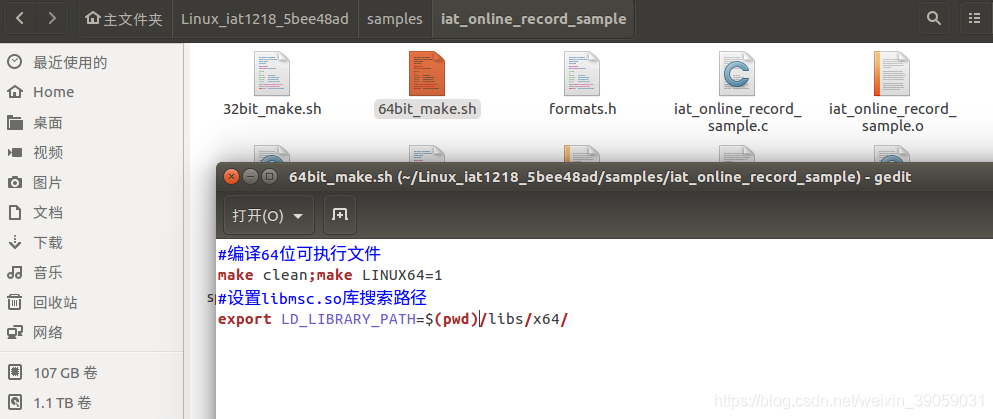
编译一下:
source 64bit_make.sh
make
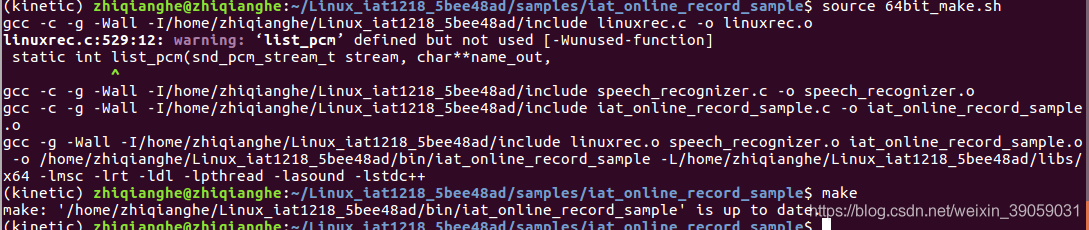
这里可能会报如下错误:
/usr/bin/ld: 当搜索用于 ../../libs/x86/libmsc.so 时跳过不兼容的 -lmsc
/usr/bin/ld: 找不到 -lmsc
collect2: error: ld returned 1 exit status
Makefile:25: recipe for target '../../bin/iat_online_record_sample' failed
make: *** [../../bin/iat_online_record_sample] Error 1
解决:
sudo apt-get install gcc-multilib g++-multilib module-assistant
之后的话还需要将一个文件复制到usr/local/lib文件下面。
sudo cp libs/x86/libmsc.so /usr/local/lib/
sudo ldconfig
否者会报错:
./iat_online_record_sample: error while loading shared libraries: libmsc.so: cannot open shared object file: No such file or directory
成功之后的话,我们可以在bin文件夹下面找到可执行文件:
运行测试:
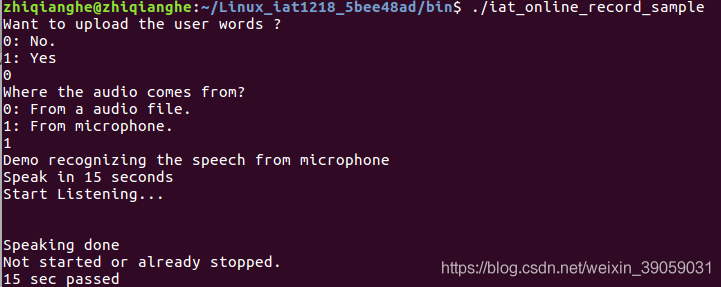
我这没有麦克风,所以没有显示结果,很伤心。
科大讯飞的SDK带有ID号,每个人每次下载后的ID都不相同,更换SDK之后需要修改代码中的APPID,运行教程包的话,你需要修改一下自己下载SDK中的ID。我们需要更改里面cpp文件里面的APPID号:ctrl+f可以对其进行搜索。

语音听写
这个文件在课程的代码里面有:
我们先来看一下里面的main函数:
int main(int argc, char* argv[])
{
// 初始化ROS
ros::init(argc, argv, "voiceRecognition");
ros::NodeHandle n;
ros::Rate loop_rate(10);
// 声明Publisher和Subscriber
// 订阅唤醒语音识别的信号
ros::Subscriber wakeUpSub = n.subscribe("voiceWakeup", 1000, WakeUp);
// 订阅唤醒语音识别的信号
ros::Publisher voiceWordsPub = n.advertise<std_msgs::String>("voiceWords", 1000);
ROS_INFO("Sleeping...");
int count=0;
while(ros::ok())
{
// 语音识别唤醒
if (wakeupFlag){
ROS_INFO("Wakeup...");
int ret = MSP_SUCCESS;
const char* login_params = "appid = 5bee48ad, work_dir = .";
const char* session_begin_params =
"sub = iat, domain = iat, language = zh_cn, "
"accent = mandarin, sample_rate = 16000, "
"result_type = plain, result_encoding = utf8";
ret = MSPLogin(NULL, NULL, login_params);
if(MSP_SUCCESS != ret){
MSPLogout();
printf("MSPLogin failed , Error code %d.\n",ret);
}
printf("Demo recognizing the speech from microphone\n");
printf("Speak in 10 seconds\n");
demo_mic(session_begin_params);
printf("10 sec passed\n");
wakeupFlag=0;
MSPLogout();
}
// 语音识别完成
if(resultFlag){
resultFlag=0;
std_msgs::String msg;
msg.data = g_result;
voiceWordsPub.publish(msg);
}
ros::spinOnce();
loop_rate.sleep();
count++;
}
我们这里有一个订阅唤醒词的环节,类似siri一样,然后还有一个发布者,将接收到的语音信号发布出去。也就是说我们最开始就是在等待语音唤醒,唤醒之后进入回调函数里面:
void WakeUp(const std_msgs::String::ConstPtr& msg)
{
printf("waking up\r\n");
usleep(700*1000);
wakeupFlag=1;
}
可以看到在这里面我们是置位了一个变量,这个变量被置为之后我们就回去进行主函数里面的语音识别代码。完成之后我们把它resultFlag置位,然后把消息封装出去,然后再发布出去:
if(resultFlag){
resultFlag=0;
std_msgs::String msg;
msg.data = g_result;
voiceWordsPub.publish(msg);
}
ros::spinOnce();
loop_rate.sleep();
count++;
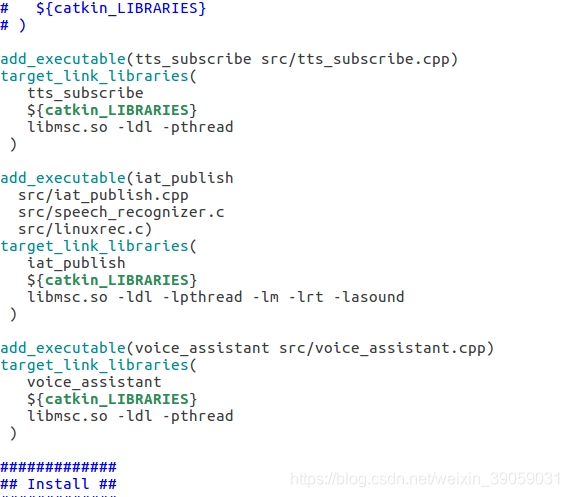
程序的编译如下:
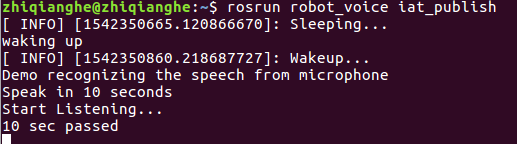
接下来我们测试一下程序的效果:
roscore
rosrun robot_voice iat_publish
rostopic pub /voiceWakeup std_msgs/String "data: '111'"
第三行是一个唤醒词为111的唤醒,


唤醒之后:
我们同样可以利用科大讯飞的平台做语音合成,这个原视频里面有说。
我的
微信公众号名称:深度学习与先进智能决策
微信公众号ID:MultiAgent1024
公众号介绍:主要研究强化学习、计算机视觉、深度学习、机器学习等相关内容,分享学习过程中的学习笔记和心得!期待您的关注,欢迎一起学习交流进步!





评论(3)
您还未登录,请登录后发表或查看评论