

深度迁移学习概述:
先分享一个小例子,对迁移学习有一个很好的初步理解:
读自https://blog.csdn.net/SuperYR_210/article/details/78952292
迁移学习简单的将就是举一反三,是将已经学习到的知识迁移到另一种未知的知识的学习,即从源域迁移到目标域。
小故事
从前有一个商人,在帝都以卖猫的玩偶为生,他叫CNN,很厉害,是一个分辨高手,擅长区分不同的猫咪,如果有人拿猫咪想要坑他,基本是不可能的。名贵的猫咪的玩偶也就
卖的贵一些。突然有一天,他不想卖猫了,想要卖狗狗和老虎的玩偶(只是比喻啦~保护小动物人人有责,违法乱纪的事坚决不能干)。
本以为老虎和猫长的比较像,区分种间不同的种类的时候,也是比较容易的。可是,事实并非如此,或者说,并没有他想象的那么容易。这突然间一下子的转行,却使他的生意
远不如从前了,因为他经常会对不同的种类的老虎和狗狗的玩偶种类做出错误的判断,会误以为名贵的为廉价的,而卖出的时候以一个低价卖出,导致自己的利润大大降低。
这时候,他只能重新开始学习大量的不同的种类的狗狗和老虎的细节特征,来尽量提升自己的利润。
后来,功夫不负有心人,凭借他以往积累的客户和他的努力,又重新打开了一片市场,获取了高额的利润,最终,他开开心心的打开某抢票软件,开通VIP抢票包,顺利的抢到
了元旦回家的车票。
好吧,故事就是这样的,好像并不怎么好玩,接下来是正题了:
模型
商人:不管他是叫是CNN,还是RNN,还是GAN,商人是迁移学习中需要用到的模型~
源域
猫咪
源域:具体地,在迁移学习中,我们已有的知识叫做源域(source domain)
目标域
狗狗和老虎的玩偶
目标域:要学习的新知识叫目标域(target domain)。
多任务学习
同时学习不同种类的狗狗和老虎的玩偶的特点。
负迁移
从猫迁移到狗,它们之间的相似度不高,即同一模型,对于数据的相似度不高的情况下,迁移的效果会出现副作用的情况,为负迁移。
产生负迁移的原因主要有:
1、源域和目标域压根不相似,谈何迁移?——数据问题(猫和狗的玩偶)
2、源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。 ——–方法问题(毛和老虎的玩偶)
深度迁移学习为传统迁移学习与深度神经网络相结合的一种新兴研究方向,以其对比非深度方法还有两个优势:自动化地提取更具现力的特征,以及满足了实际应用中的端到端
(End-to-End) 需求。
下图为深度迁移学习与传统迁移的结果比对。图中深度迁移学习方法 (BA、DDC、DAN) 对比传统迁移学习方法 (TCA、GFK 等)。
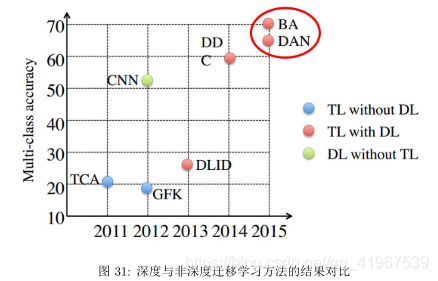
1.实验测试:
目前,深度迁移学习大致的思路为:
在 ImageNet 的 1000 类上,把 1000类分成两份(A 和 B),每份 500 个类别。然后,分别对A 和B 基于Caffe 训练了一个AlexNet 网络。一个 AlexNet 网络一共有 8 层,除去
第 8 层是类别相关的网络无法迁移以外,作者在 1 到 7 这 7 层上逐层进行 finetune 实 验,探索网络的可迁移性。
为了更好地说明 finetune 的结果,作者提出了有趣的概念:AnB 和 BnB。
迁移 A 网络的前 n 层到 B(AnB)vs 固定 B 网络的前 n 层(BnB) 。
简单说一下什么叫 AnB:(所有实验都是针对数据 B 来说的)将 A 网络的前 n 层拿来并将它 frozen,剩下的 8 − n 层随机初始化,然后对 B 进行分类。
相应地,有 BnB:把训练好的 B 网络的前 n 层拿来并将它 frozen,剩下的 8 −n 层随 机初始化,然后对 B 进行分类。
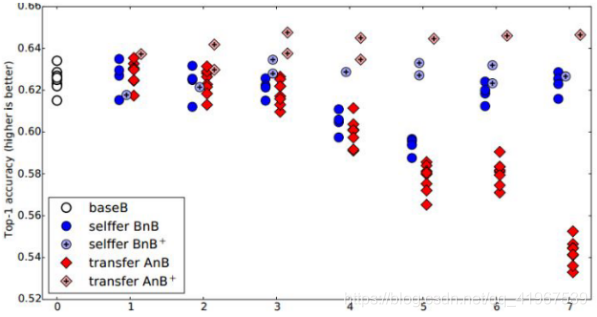
这个图说明了什么呢?我们先看蓝色的 BnB 和 BnB+(就是 BnB 加上 finetune)。对BnB 而言,原训练好的 B 模型的前 3 层直接拿来就可以用而不会对模型精度有什么损失。 到
了第 4 和第 5 层,精度略有下降,不过还是可以接受。然而到了第 6 第第 7 层,精度居 然奇迹般地回升了!这是为什么?原因如下:对于一开始精度下降的第 4 第 5 层来说,
确实是到了这一步,feature 变得越来越 specific,所以下降了。那对于第 6 第 7 层为什么精 度又不变了?那是因为,整个网络就 8 层,我们固定了第 6 第 7 层,这个网络还能
学什么 呢?所以很自然地,精度和原来的 B 网络几乎一致!
对 BnB+ 来说,结果基本上都保持不变。说明 finetune 对模型结果有着很好的促进作用!
我们重点关注 AnB 和 AnB+。对 AnB 来说,直接将 A 网络的前 3 层迁移到 B,貌 似不会有什么影响,再一次说明,网络的前 3 层学到的几乎都是 general feature!往后,到
了第 4 第 5 层的时候,精度开始下降,我们直接说:一定是 feature 不 general 了! 然而, 到了第 6 第 7 层,精度出现了小小的提升后又下降,这又是为什么?作者在这里提出
两点: co-adaptation 和 feature representation。就是说,第 4 第 5 层精度下降的时候,主要是由 于 A 和 B 两个数据集的差异比较大,所以会下降;到了第 6 第 7 层,由于网
络几乎不迭代 了,学习能力太差,此时 feature 学不到,所以精度下降得更厉害。
再看 AnB+。加入了 finetune 以后,AnB+ 的表现对于所有的 n 几乎都非常好,甚至比 baseB(最初的 B)还要好一些!这说明:finetune 对于深度迁移有着非常好的促进作
用!
1)Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
2)Fine-tune:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
注:Transfer Learning关心的问题是:什么是“知识”以及如何更好地运用之前得到的“知识”,这可以有很多方法和手段,eg:SVM,贝叶斯,CNN等。而fine-tune只是其中的一
种手段,更常用于形容迁移学习的后期微调中。
2.Finetune:
Finetune的优势是:
• 不需要针对新任务从头开始训练网络,节省了时间成本;不需要针对新任务从头开始训练网络,节省了时间成本;
• 预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得 模型更鲁棒、泛化能力更好;
• Finetune 实现简单,使得我们只关注自己的任务即可
一个简单的finetune示意图:
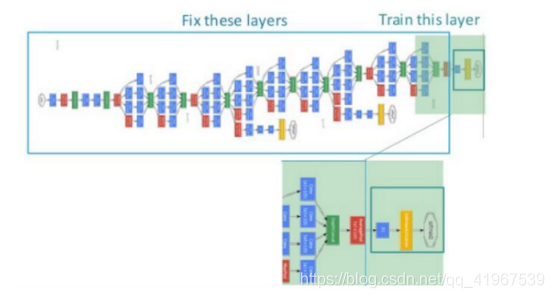
Finetune的不足是:
• 它无法处理训练数据和测试数据分布不同的情况。此时需要引入一个新的概念:深度网络自适应
3.深度网络自适应:
常用的方法有:
DDC([Tzeng et al., 2014] Tzeng, E., Hoffman, J., Zhang, N., et al. (2014). Deep domain confu- sion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474.)
DAN([Long et al., 2015a] Long, M., Cao, Y., Wang, J., and Jordan, M. (2015a). Learning trans- ferable features with deep adaptation networks. In ICML, pages 97–105.)
同时迁移领域和任务([Tzeng et al., 2015] Tzeng, E., Hoffman, J., Darrell, T., and Saenko, K. (2015). Simulta- neous deep transfer across domains and tasks. In Proceedings
of the IEEE International Conference on Computer Vision, pages 4068–4076, Santiago, Chile. IEEE.)
深度联合分布自适应([Long et al., 2017] Long, M., Wang, J., and Jordan, M. I. (2017). Deep transfer learning with joint adaptation networks. In ICML, pages 2208–2217.)
AdaBN([Li et al., 2018] Li, Y., Wang, N., Shi, J., Hou, X., and Liu, J. (2018). Adaptive batch normalization for practical domain adaptation. Pattern Recognition, 80:109–117.)
AutoDIAL([Carlucci et al., 2017] Carlucci, F. M., Porzi, L., Caputo, B., Ricci, E., and Bulò, S. R. (2017). Autodial: Automatic domain alignment layers. In International
Conference on Computer Vision)
4.深度对抗网络迁移
生成对抗网络 GAN(Generative Adversarial Nets) :
GAN受到自博弈论中的二人零和博弈 (two-player game) 思想的启发而提出。它一共包括两个部分:一部分为生成网络 (Generative Network),此部分负责生成尽可能地以假乱
真 的样本,这部分被成为生成器 (Generator);另一部分为判别网络 (Discriminative Network), 此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器
(Discriminator)。 生成器和判别器的互相博弈,就完成了对抗训练。
GAN 的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由 于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样
本的 过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的 职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数
据的特征, 使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器 (Feature Extractor)。
通常用 Gf 来表示特征提取器,用 Gd 来表示判别器。
正是基于这样的领域对抗的思想,深度对抗网络可以被很好地运用于迁移学习问题中。
与深度网络自适应迁移方法类似,深度对抗网络的损失也由两部分构成:网络训练的损失 ℓc 和领域判别损失 ℓd:
ℓ = ℓc(Ds, ys) + λℓd(Ds, Dt)
常用的方法:
DANN([Ganin et al., 2016] Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Lavi- olette, F., Marchand, M., and Lempitsky, V. (2016). Domain-adversarial
training of neural networks. Journal of Machine Learning Research, 17(59):1–35)
DSN([Bousmalis et al., 2016] Bousmalis, K., Trigeorgis, G., Silberman, N., Krishnan, D., and Erhan, D. (2016). Domain separation networks. In Advances in Neural
Information Processing Systems, pages 343–351)
选择性迁移网络Partial Transfer Learning([cvpr.2018].Cao, Zhangjie,Long, Mingsheng,Wang, Jianmin,Jordan, Michael I.(2018).Partial Transfer Learning with Selective Adversarial Networks Zhangjie)



评论(0)
您还未登录,请登录后发表或查看评论