

文本分类是NLP领域最经典的应用场景之一,其实现方法我们可以划分为两类。
其一是基于传统机器学习的文本分类,如 TF-IDF文本分类。其二便是基于深度学习方法的文本分类,如Facebook开源的FastText文本分类,Text-CNN 文本分类,Text-CNN 文本分类等。下面我们详细介绍这两种方法。
一、机器学习方法
文本分类任务可被划分为特征工程和分类器两部分,具体流程如下图所示: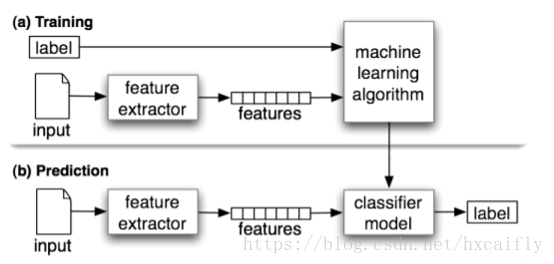
特征工程
这里的特征工程也就是将文本表示为计算机可以识别的、能够代表该文档特征的特征矩阵的过程。在基于传统机器学习的文本分类中,我们通常将特征工程分为文本预处理、特征提取、文本表示等三个部分。
文本预处理
文本预处理过程是提取文本中的关键词来表示文本的过程。中文文本预处理主要包括文本分词和去停用词两个阶段。
中文分词现有技术主要有以下几种:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法
1.基于字符串匹配的分词方法:
原理:这是一种基于词典的中文分词,核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。
核心: 字典,切分规则和匹配顺序是核心。
分析:优点是速度快,时间复杂度可以保持在O(n),实现简单,效果尚可;但对歧义和未登录词处理效果不佳。
2.基于理解的分词方法
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
3.基于统计的分词方法
原理:统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
主要的统计模型有: N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
停止词是文本中一些高频的代词、连词、介词等对文本分类无意义的词,通常维护一个停用词表,特征提取过程中删除停用表中出现的词,本质上属于特征选择的一部分。
特征提取
特征提取包括特征选择和特征权重计算两部分。
特征选择的基本思路是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有:文档频率、互信息、信息增益、χ²统计量等。
特征权重计算主要是经典的TF-IDF方法及其扩展方法。TF-IDF的主要思想是一个词的重要度与在类别内的词频成正比,与所有类别出现的次数成反比。
文本表示
文本表示的目的是把文本预处理后的转换成计算机可理解的方式,是决定文本分类质量最重要的部分。传统做法常用词袋模型(BOW, Bag Of Words)或向量空间模型(Vector Space Model),最大的不足是忽略文本上下文关系,每个词之间彼此独立,并且无法表征语义信息。
分类器
机器学习常用分类算法有:LR模型,随机森林模型(RF),SVM分类模型,KNN分类模型,神经网络分类模型。
深度学习方法
深度学习文本分类算法有FastText模型、TextCNN模型、TextRNN模型、TextRNN+Attention模型+TextRCNN模型等。
FastText
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
FastText方法包含三部分,模型架构,层次SoftMax和N-gram特征
FastText架构
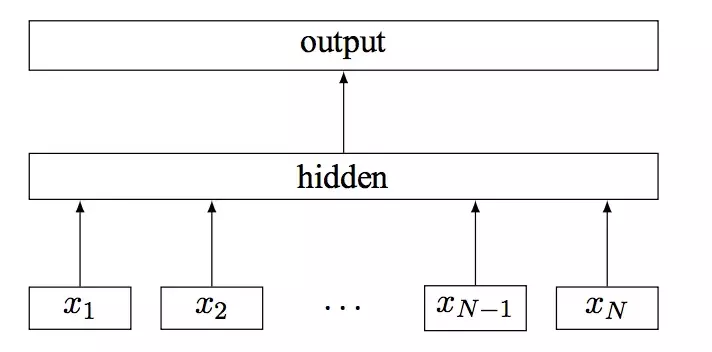
FastText模型架构和 Word2Vec 中的 CBOW 模型很类似,因为它们的作者都是Facebook的科学家Tomas Mikolov。不同之处在于,FastText预测标签,而CBOW 模型预测中间词。
CBOW输入的是w(t)的上下文2d个词,经过隐藏层后,输出的是w(t)。而FastText输入是整个文本。
N-gram特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
词袋模型介绍
例句: Jane wants to go to Shenzhen. Bob wants to go to Shanghai.
将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个词语都是独立的。例如上面2个例句,就可以构成一个词袋,袋子里包括Jane、wants、to、go、Shenzhen、Bob、Shanghai。
假设建立一个数组(或词典)用于映射匹配
[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么上面两个例句就可以用以下两个向量表示,对应的下标与映射数组的下标相匹配,其值为该词语出现的次数:
[1,1,2,1,1,0,0]
[0,1,2,1,0,1,1]
这两个词频向量就是词袋模型,可以很明显的看到语序关系已经完全丢失。
“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然啦,为了提高效率,我们需要过滤掉低频的 N-gram。
层次SoftMax
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中。
文本分类实现:github源码
参考文章
https://www.jianshu.com/p/56061b8f463a
其他方法待续…



评论(0)
您还未登录,请登录后发表或查看评论