

一幅漫画引发的思考

先从一幅漫画说起
话说有一天,小镇举行一场临摹比赛,规则是这样的:首先给大家一张底稿,然后在上面覆盖透明的纸进行作画。要求是每一层纸只允许画原稿的一部分特征,至于覆盖多少层纸不做要求。最后看谁能够画的最接近原底稿。
最后有三个人选择了三种不同的方式作画:第一个人只是覆盖了几层底稿,结果就是画出来的画缺少很多特征,不能完全表征原底稿;第二个人为了画全这个图像,覆盖了一层又一层,最后画是画完了,但是覆盖到最后,很多特征已经不是很清晰了,画得也不是很像;最后一个人就比较聪明,他每覆盖一层透明的纸之后,又会再把原底稿再加进来,这样既能保证画全了特征,还能让特征始终保持清晰,还原度得到了极大的提高。
最后这个人由于画得好,顺利获得临摹大赛的第一名,赢取了白富美,走上了人生巅峰。。。
什么是ResNet网络?
上面那个漫画和ResNet网络有啥子关系?
首先,ResNet网络是一个很牛逼的网络。为啥?因为它的神经网络的深度达到了惊人的152层,并以top-5错误率3.57%的好成绩在ILSVRC2015比赛中获得了冠军。这个成绩足以让大家好好研究一下这个网络到底是何方神圣了。
ResNet意义
随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构如图: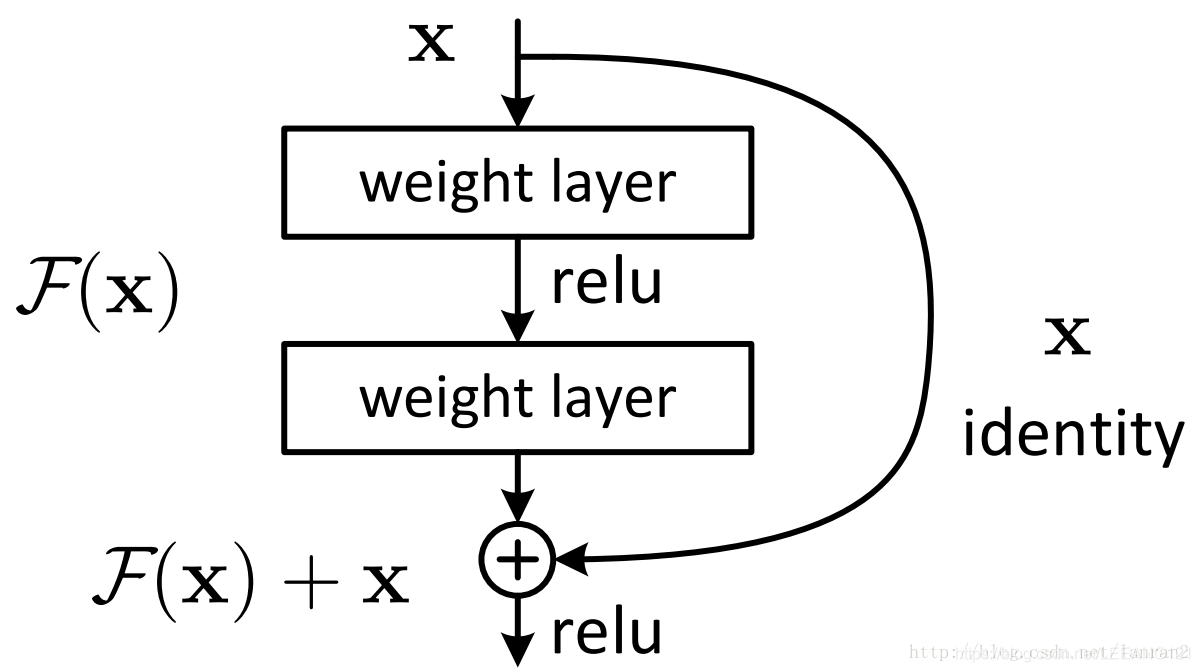
这里问大家几个问题
残差指的是什么?
其中ResNet提出了两种mapping:一种是identity mapping,指的就是上图中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是
y
=
F
(
x
)
+
x
y=F(x)+x
y=F(x)+x
identity mapping顾名思义,就是指本身,也就是公式中的
x
x
x,而residual mapping指的是“差”,也就是
y
−
x
y−x
y−x,所以残差指的就是
F
(
x
)
F(x)
F(x)部分。
我们当然希望
F
(
x
)
F(x)
F(x)为0.但是显然这是不现实的,因此我们通常希望
F
(
x
)
F(x)
F(x)逼近一个很小的值。
为什么ResNet可以解决“随着网络加深,准确率不下降”的问题?
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
这段话比较晦涩一些,用大白话解释可以这样理解:
如上图网络结构一样,我们在对输入进行卷积的过程中,一直在提取特征,为了保证特征在提取的过程中不会因为网络的增加发生梯度消失或者梯度爆炸,我们会时不时的做个弊,就是在输出的时候,再把原始数据一起加进去,作为下一层计算的输入。(时刻保持革命的先进性)
如何实现这个操作?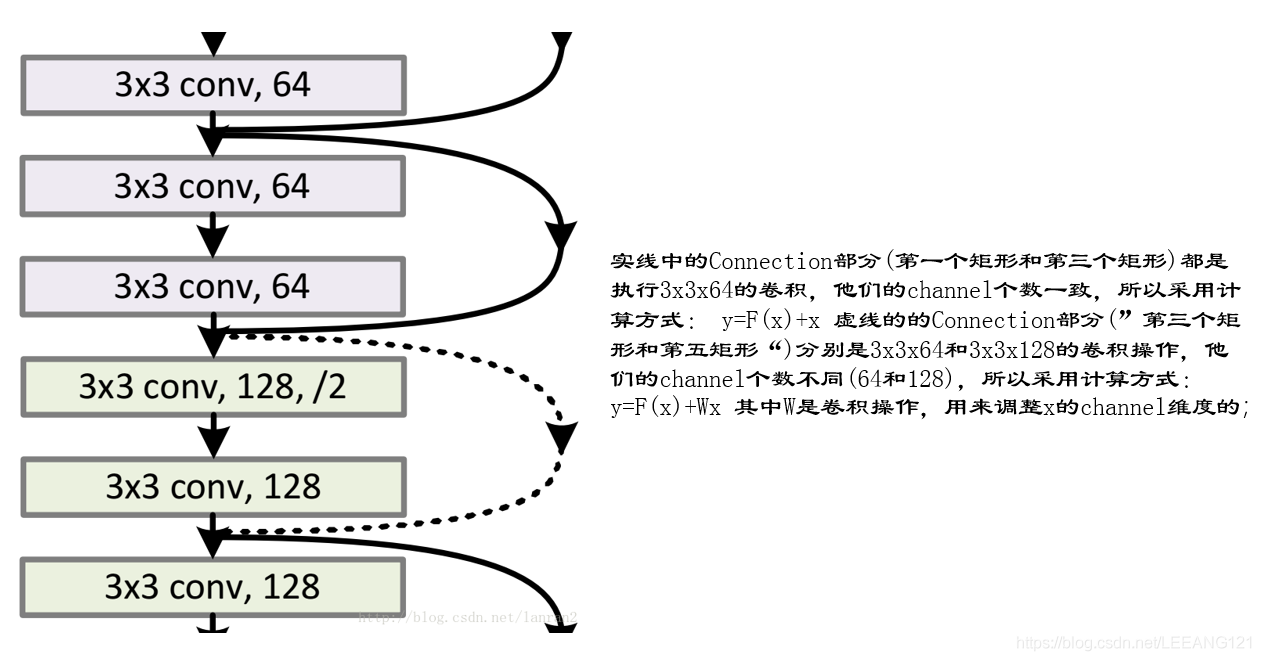
关于残差网络一些思考
为什么残差学习的效果会如此的好?与其他论文相比,深度残差学习具有更深的网络结构,此外,残差学习也是网络变深的原因?为什么网络深度如此的重要?
解:一般认为神经网络的每一层分别对应于提取不同层次的特征信息,有低层,中层和高层,而网络越深的时候,提取到的不同层次的信息会越多,而不同层次间的层次信息的组合也会越多。
为什么在残差之前网络的深度最深的也只是GoogleNet 的22 层, 而残差却可以达到152层,甚至1000层?
解:深度学习对于网络深度遇到的主要问题是梯度消失和梯度爆炸,传统对应的解决方案则是数据的初始化(normlized initializatiton)和(batch normlization)正则化,但是这样虽然解决了梯度的问题,深度加深了,却带来了另外的问题,就是网络性能的退化问题,深度加深了,错误率却上升了,而残差用来设计解决退化问题,其同时也解决了梯度问题,更使得网络的性能也提升了。
残差网络结构是如何运行的?
将输入叠加到下层的输出上。对于一个堆积层结构(几层堆积而成)当输入为x时其学习到的特征记为H(x),现在我们希望其可以学习到残差F(x)=H(x)-x,这样其实原始的学习特征是F(x)+x 。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
总结:
卷积神经网络到目前为止诞生了很多经典的结构模型,通过阅读文献,查找资料我们会很快了解他们,但是要想真的掌握他们,我们一定要亲自去写相应的代码,并应用到项目当中去才可以。



评论(0)
您还未登录,请登录后发表或查看评论