

本系列意在长期连载分享,内容上可能也会有所增删改减;
因此如果转载,请务必保留源地址,非常感谢!
知乎专栏:当我们在谈论数据挖掘
引言
上一篇文章中,有同学表示对 CNN 的 BP 很感兴趣,本篇就把此理论细节补全。然后,会继续补充一些有趣的 CNN 架构及其相关细节。
CNN 与 Backpropagation
CNN 可以看成是普通 FC(Fully Connected)DNN 的特殊形式。特殊在以下几个方面:
- CNN 中 Convolution Kernel 对应的两个 Layer 神经元之间的连接是稀疏的,当然,也可以将那些无连接看成是
恒为0的连接
- CNN 中 Convolution Kernel 对应的两个 Layer 之间连接的权重是共享的,因为它们共享一个 Convolution Kernel
- CNN 中存在 Pooling Layer
由于 CNN 是多种 Layer 的花式堆叠,不像 FC DNN 有统一的结构,因此无法给出整个网络的 BP 公式,这里我们只关注两个 Layer 之间的 BP。接下来,本部分会介绍 Convolutio Layer 的 BP。由于 Pooling Layer 的 BP 相对简单,就不增加篇幅了。建议对 FC DNN 的 BP 不熟悉的同学,可以先看看本专栏的“当我们在谈论 Deep Learning:DNN 与 Backpropagation”,下面整体思路与该篇相似,且会直接使用其中某些结论。
为了方便描述,下文讨论的 CNN 都是两维且 Channel 为1, 也即两层之间 Convolution Kernel 只有一个。
Convolutio Layer 与 BP
先明确本文后续使用的变量的定义。若将其中相邻的两层 Hidden Layers 提取出来,其表示的含义如下。表示第
层第
行第
列的神经元的输入,
表示第
层第
行第
列神经元的输出,
表示激活函数。
表示从第
连接到第
层的 Convolution Kernel,
则表示其第
行第
列对应的权重。
表示对应的偏置。
根据卷积的定义,有
此时,我们定义,于是有
由于
我们能够得到为
于是有
这里,下标是用来表示自变量,而非具体的坐标。
表示将 Convolution Kernel 水平与竖直翻转,也等同于旋转180度。
接下来,我们开始求,如下
然后,我们开始求,如下
最后,我们总结 CNN 的 BP 相关的几个公式如下。可以看出,跟 DNN 中的 BP 是一一对应的。
公式推导完毕,下面我们回到 CNN 相关的架构上来
AlexNet
AlexNet 是 Alex Krizhevsky 于2012年在“ImageNet Classification with Deep Convolutional Neural Networks”中提出的网络架构。Alex Krizhevsky 凭借它在 ILSVRC2012 的 ImageNet 图像分类项目中获得冠军,错误率比上一年冠军下降十多个百分点。其具体的结构如下图,第一个图为作者论文中的辅助理解的图示,第二个图为将 AlexNet 每一层的细节进行总结的图。
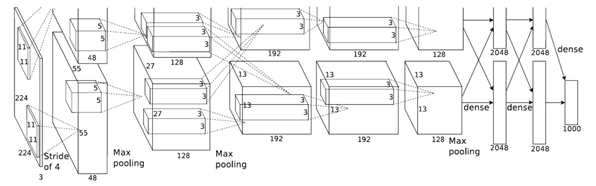
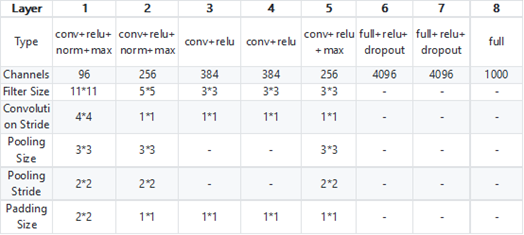
从上图可以看出,AlexNet 在结构上没有大改变。它真正区别于传统 CNN 的,在于对网络参数的选择上,而其中很多方法如今依然在用:
- 不同于传统 CNN 使用 Sigmoid 或者 Tanh 作为激活函数,AlexNet 使用的是 Relu。Relu 能有效抑制 Gradient Vanish 以及 Gradient Explode 的问题,现在仍然是最常用的激活函数。关于 Gradient Vanish 和 Relu 的更多理论细节,可以参看“当我们在谈论 Deep Learning:DNN 与它的参数们(壹)”中"Activation Function"一部分
- AlexNet 开始使用了 Droupout 来防止过拟合,这是一种简单且有效减少过拟合的方法,如今依然是手常用方法之一。关于 Droupout 更多理论细节,在“当我们在谈论 Deep Learning:DNN 与它的参数们(贰)”中已经详细介绍过了
- AlexNet 使用 LRN(Local Response Normalization)对网络中的数据进行归一化。当然现在 LRN 已经不太使用,使用的较多的是效果好得多的 Batch Normalization。但是 AlexNet 当时已经开始注意对数据进行归一化,这一点还是很厉害的。Batch Normalization 相关的细节在“当我们在谈论 Deep Learning:DNN 与它的参数们(叁)”部分
- AlexNet 使用了 GPU 来加速网络中的运算,现在 GPU 来加速计算已经是标配了
AlexNet 中这些技巧,很多已经成了现在的标准方法,足见其影响力之大。
GoogLeNet
GoogLeNet 其实属于 Inception 网络结构系列,其启发是 NIN(Network In Network),而后整个 Inception 系列共发展出四个版本。这里,先简单介绍这几种结构。
NIN
NIN 出自文章“Network in Network”,主要是提出了两点新的构想,以下简单描述:
- 使用多层
的 Convolution Kernel,来代替传统 CNN 一层的若干个
的 Convolution Kernel。原因在于,单层的 Convolution Kernel + Activation 只是扩展的线性变换,表达能力有限;但是多层 Convolution Kernel + Activation 的堆叠,后面几层的抽象能力会大大增强,所以表达能力比以前强,而参数可能还比以前少
- 使用 Global Average Pooling 代替传统 CNN 中最后一层的 Fully Connected 层,其中 Global Average Pooling 表示取每个 Feature Map 的均值。因此,对多类分类,最后一层的每个 Feature Map 即对应一个类别,在大大减少了 CNN 参数的同时,强制 Feature Map 学习不同类别的特征
Inception V1,BN,V3,V4
GoogLeNet 就是 Inception V1,出自2015年的“Going Deeper with Convolutions”。它继承并扩展了 NIN 中使用小 Convolution Kernel 来代替或者表示大 Convolution Kernel 的思想,在网络能力不减的情况下大大降低参数量
Inception BN 出自2015年的“Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”。在本文中,作者提出了大名鼎鼎的 Batch Normalization,现在是 DNN 调参的一个重要手段,提高了 DNN 对参数的稳定性。BN 的具体细节请参考“当我们在谈论 Deep Learning:DNN 与它的参数们(叁)”
Inception V3 出自2016年的“Rethinking the Inception Architecture for Computer Vision”。其在 Inception V1 的基础上,利用 Factorization 进一步降低 Convolution Kernel 中的参数数量
Inception V4 出自2016年的“Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”。如其名所说,它就是结合了 Inception 和 ResNet 的思想。关于 ResNet 下文会有详细介绍
可以看出,除了 Inception BN 主题有点跑偏,其他的 Inception 都是在 GoogLeNet 的基础上的改进。所以,以下我会详细介绍 GoogLeNet。
GoogLeNet
GoogLeNet 最大的特点就是下面这种结构,暂且称之为原始的 Inception。
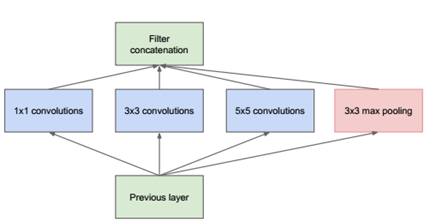
可以看出它本质跟 NIN 一样,使用 Network 来代替原来的一个 Convolution Kernel。但跟 NIN 只使用不同,这里使用了更大的 Convolution Kernel,以及 Pooling Layer,原因在于提取视野更大、或者提取类型不同的特征。但是由于这种 Network 的参数会非常大,所以作者先进行了降维,就得到了真正的 Inception 结构,如下图
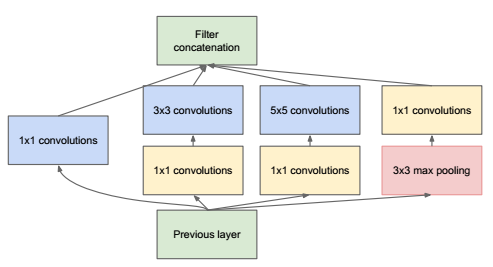
Kernel 在这里的作用就是为了在叠加 Inception 模块时,不至于让网络参数数量爆炸,所做的降维。在理解了 Inception 模块后,整个 GoogLeNet 的结构上就很容易看懂了,基本就是 Inception 模块、Pooling Layer 的不停叠加而已。其结构如下图(大图预警):
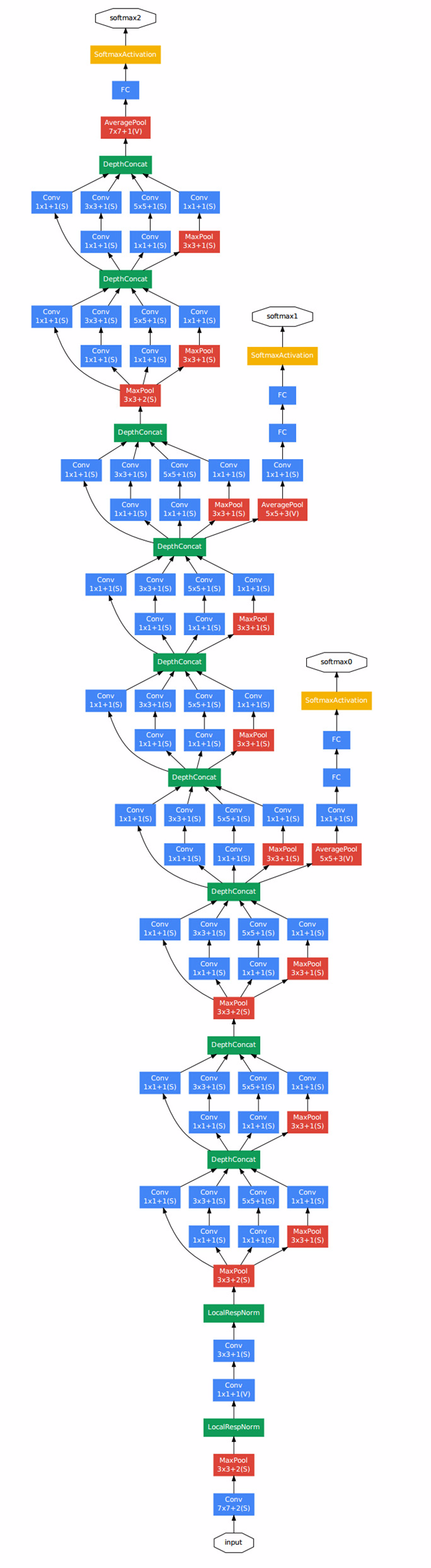
上图中我们能看到有一点比较特殊,就是除了最上层的 softmax2 分类器外,中间还有一些层连接了分类器(softmax0、softmax1)。
按照作者初期的说法,这是因为网络太深,Gradient Vanish 导致无法高效的更新参数,所以加了两个较浅的分类器辅助 BP 以加快网络收敛速度。可是在 Inception V3 中,作者发现其实它们对网络收敛速度并没什么帮助,更多的是起到了 Regularizer 的作用。
Inception 提出了新的 CNN 结构,并在 ILSVRC2014 使错误率再创新低。可它在深层网络 Gradient Vanish 的问题上并未找到好的解决办法,这就制约了网络进一步的加深。就在大家看似都一筹莫展时,另一个大佬微软笑着掏出了 ResNet。
ResNet
ResNet 出自“Deep Residual Learning for Image Recognition,2016”。它源于作者一些实验:在 Relu、BN 已经缓解了深层的网络无法收敛的问题后,随着网络层数的增加,训练和测试错误率仍然呈现先减后增的趋势。这时,就不再是过拟合的问题,而表明太深的网络其参数难以优化。比如对于恒等变换,更深的网络其对此函数的拟合效果甚至不如较浅的网路。
为了解决上述难以拟合的问题,作者提出了一种设想:我们不去拟合
,改之去拟合
。而最终网络输出的是
,如下图
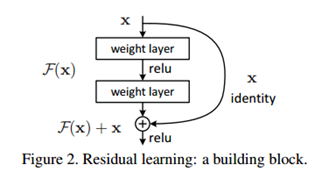
这种做法会涉及到两个问题:
- 在恒等变换中我们拟合的函数变成了
,它为什么比原始的
更容易拟合呢?作者表示,此时参数们只需要逼近0即可,这看起来比优化到其他值简单(这个虽然抽象,但似乎还有点道理)
- 实际情况中
不太可能都是恒等变换,这种拟合残差的做法为何有好处呢?作者表示,首先我们要假设它更好优化,其次我们的实验证明了它确实效果更好(这里估计很多 ML 学者希望亮出那张“尴尬又不失得体的笑”的表情图)
上面是戏谑一下 RessNet 在起初时的理论匮乏。其实在后续,分析其理论依据的文章也相继有提出,如
- 在“Identity Mappings in Deep Residual Networks,2016”中,作者从实验和理论两方面来说明为什么 ResNet 使用 Identity Mappping 来计算残差是合理的,且稳定性更强
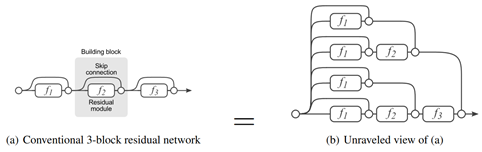
- 在"Residual Networks Behave Like Ensembles of Relatively Shallow Networks,2016"中,作者则用实验表明 ResNet 可能效果显著的原因在于其 Ensemble 的性质,即它的 Shortcut 层可以看作多种不同的路径的 Ensemble,如下图。同时作者也表示 ResNet 真实选择路径时其实选的都是较短的路径,因此本质上并不算解决了深层网络 Gradient Vanish 的问题
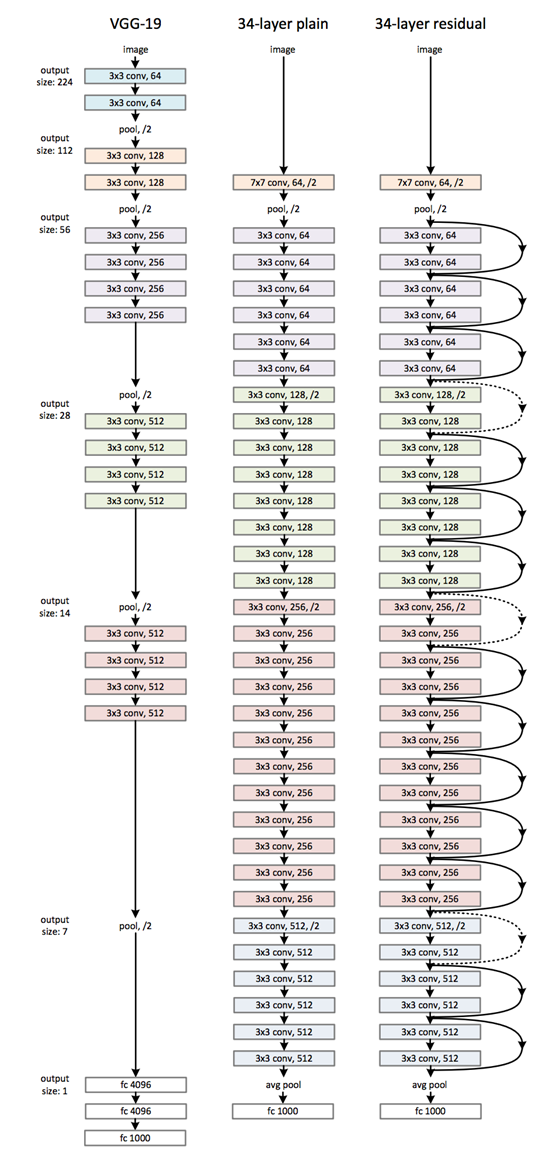
无论如何,ResNet 虽然理论不足,却被大量检验证明能有效改善网络参数的优化,一方面是即使网络深度剧增依然能够很好的学习参数,保持较好的网络分类效果;另一方面,参数收敛速度也更快。最终的 ResNet 架构如下,可以看出层数已经超深了(大图预警)
尾巴
其实 CNN 还有很多有意思的结构(Alphago、DeepDream、Neural-Style等等等),其理论上的更新也非常快,而篇幅跟精力实在有限,暂时先写到这里。毫无疑问 CNN 还处于高速进化阶段,后续到底是会“返璞归真”,开始注重单层 Layer 的质量,毕竟现在堆砌的 Layer 其实很多都被浪费了;还是继续“没有最深,只有更深”地往前奔,现在看着仍是未知数。
本系列其他文章:
Supervised Learning:
当我们在谈论 Deep Learning:DNN 与 Backpropagation
当我们在谈论 Deep Learning:DNN 与它的参数们(壹)
当我们在谈论 Deep Learning:DNN 与它的参数们(贰)
当我们在谈论 Deep Learning:DNN 与它的参数们(叁)
当我们在谈论 Deep Learning:CNN 其常见架构(上)
当我们在谈论 Deep Learning:CNN 其常见架构(下)
当我们在谈论 Deep Learning:GAN 与 WGAN
Unsupervised Learning:
Reinforcement Learning:



评论(0)
您还未登录,请登录后发表或查看评论