

近日,PyTorch1.10版本发布,这个版本在分布式训练方面正式发布了ZeroRedundancyOptimizer,对标微软在DeepSpeed中发布的ZeRO,它可以wrap其它任意普通优化器如SGD和Adam等,主要是实现optimizer state在DDP训练过程中切分,从而减少每个节点(进程或者设备)的显存使用。此外,这个版本也发布了Join,这个是一个上下文管理器,用来处理分布式训练中的不均匀样本,DDP和 ZeroRedundancyOptimizer是支持这项功能的。
ZeroRedundancyOptimizer
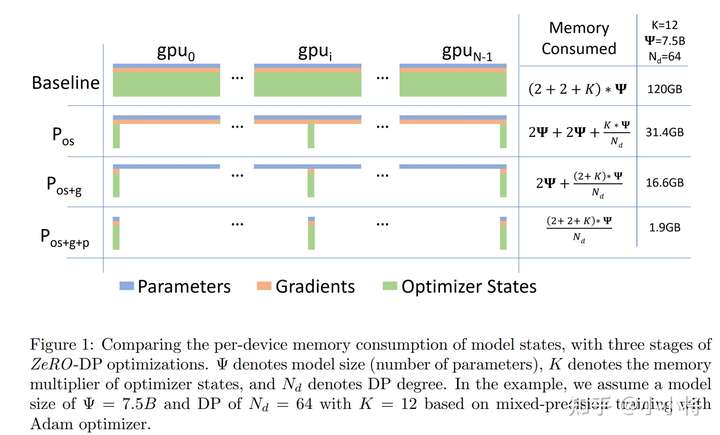
ZeRO是微软提出的一种大规模模型在分布式训练的一种优化策略,主要是通过model states进行切分来实现显存占用的优化,model states主要包括optimizer states,gradients和parameter。而ZeroRedundancyOptimizer用来实现对optimizer states的切分,这里的optimizer states指的是优化器所需的参数,比如SGD需要和模型参数一样大小的momentum,而Adam需要exp_avg和exp_avg_sq,它们是模型参数的两倍大小,当模型较大时,optimizer states会是不小的显存开销。而在DDP中,每个rank(node,process,device)都包括一个optimizer副本,在每个iteration中它们干相同的事情:用all-reduce后的gradients去更新模型参数,从而保证每个rank的模型参数一致。不过这个过程可以优化,那就是将optimizer states切分到每个rank上,每个rank的optimizer只保存一部分(1/world_size)模型参数需要的optimizer states,也只负责更新这部分模型参数。一旦某个rank完成参数更新后,它可以broadcast到其它ranks,从而实现各个rank模型参数的一致。ZeroRedundancyOptimizer其实相当于ZeRO-DP-1,是ZeRO的最简单版本,更多内容可以阅读之前的文章,Facebookfairscale库也已经实现了更全面ZeRO优化版本:FSDP。
ZeroRedundancyOptimizer的使用很简单,只需要对常规的optimizer进行warp即可以,一个简单的用例如下所示:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.distributed.optim import ZeroRedundancyOptimizer
from torch.nn.parallel import DistributedDataParallel as DDP
def print_peak_memory(prefix, device):
if device == 0:
print(f"{prefix}: {torch.cuda.max_memory_allocated(device) // 1e6}MB ")
def example(rank, world_size, use_zero):
torch.manual_seed(0)
torch.cuda.manual_seed(0)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Sequential(*[nn.Linear(2000, 2000).to(rank) for _ in range(20)])
print_peak_memory("Max memory allocated after creating local model", rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
print_peak_memory("Max memory allocated after creating DDP", rank)
# define loss function and optimizer
loss_fn = nn.MSELoss()
if use_zero:
# 简单地warp
optimizer = ZeroRedundancyOptimizer(
ddp_model.parameters(),
optimizer_class=torch.optim.Adam,
lr=0.01
)
else:
optimizer = torch.optim.Adam(ddp_model.parameters(), lr=0.01)
# forward pass
outputs = ddp_model(torch.randn(20, 2000).to(rank))
labels = torch.randn(20, 2000).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
print_peak_memory("Max memory allocated before optimizer step()", rank)
optimizer.step()
print_peak_memory("Max memory allocated after optimizer step()", rank)
print(f"params sum is: {sum(model.parameters()).sum()}")
def main():
world_size = 2
print("=== Using ZeroRedundancyOptimizer ===")
mp.spawn(example,
args=(world_size, True),
nprocs=world_size,
join=True)
print("=== Not Using ZeroRedundancyOptimizer ===")
mp.spawn(example,
args=(world_size, False),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
## output
=== Using ZeroRedundancyOptimizer ===
Max memory allocated after creating local model: 335.0MB
Max memory allocated after creating DDP: 656.0MB
Max memory allocated before optimizer step(): 992.0MB
Max memory allocated after optimizer step(): 1361.0MB
params sum is: -3453.6123046875
params sum is: -3453.6123046875
=== Not Using ZeroRedundancyOptimizer ===
Max memory allocated after creating local model: 335.0MB
Max memory allocated after creating DDP: 656.0MB
Max memory allocated before optimizer step(): 992.0MB
Max memory allocated after optimizer step(): 1697.0MB
params sum is: -3453.6123046875
params sum is: -3453.6123046875可以看到无论使用或不使用ZeroRedundancyOptimizer,模型创建使用的显存是一样的,而且最终的输出也是一致的,但是optimizer执行step后,两者差异就出来了,使用ZeroRedundancyOptimizer可以降低大约一半的显存消耗,这是因为optimizer states被均分在2个rank上了。
Join
在DDP训练中,在backward背后其实是执行all-reduce来实现各个rank上的gradients同步,这是一种集群通信(collective communications),所有的集群通信都需要所有rank的参与,如果某个rank的输入较少,那么其它rank就会等待甚至出错。而Join这个上下文管理器就是为了解决分布式训练过程中的不均匀输入的情况,简单来说就是允许某些输入较少的rank(已经join)可以跟随那么未执行完的rank(未join)进行集群通信。看起来比较抽象,但是从下面的一个DDP例子就比较容易理解:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.distributed.algorithms.join import Join
from torch.nn.parallel import DistributedDataParallel as DDP
BACKEND = "nccl"
WORLD_SIZE = 2
NUM_INPUTS = 5
def worker(rank):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(BACKEND, rank=rank, world_size=WORLD_SIZE)
model = DDP(torch.nn.Linear(1, 1).to(rank), device_ids=[rank])
# Rank 1 gets one more input than rank 0
inputs = [torch.tensor([1]).float() for _ in range(NUM_INPUTS + rank)]
num_inputs = 0
with Join([model]):
for input in inputs:
num_inputs += 1
loss = model(input).sum()
loss.backward()
print(f"Rank {rank} has exhausted all {num_inputs} of its inputs!")
def main():
mp.spawn(worker, nprocs=WORLD_SIZE, join=True)
if __name__ == "__main__":
main()
## output
Rank 0 has exhausted all 5 of its inputs!
Rank 1 has exhausted all 6 of its inputs!这里rank0只有5个inputs,而rank1有6个inputs,这是不均匀的数据。如果不使用Join的话,rank1在处理最后的一个input时会死等,但是使用Join后,就能正常处理这种情况,这背后的原理后面再说。这里的with Join([model])和with model.join():,不过前者更灵活,因为它能处理多个类的情况,比如要使用ZeroRedundancyOptimizer:
from torch.distributed.optim import ZeroRedundancyOptimizer as ZeRO
from torch.optim import Adam
def worker(rank):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(BACKEND, rank=rank, world_size=WORLD_SIZE)
model = DDP(torch.nn.Linear(1, 1).to(rank), device_ids=[rank])
optim = ZeRO(model.parameters(), Adam, lr=0.01)
# Rank 1 gets one more input than rank 0
inputs = [torch.tensor([1]).float() for _ in range(NUM_INPUTS + rank)]
num_inputs = 0
# Pass both `model` and `optim` into `Join()`
with Join([model, optim]):
for input in inputs:
num_inputs += 1
loss = model(input).sum()
loss.backward()
optim.step()
print(f"Rank {rank} has exhausted all {num_inputs} of its inputs!")此外,Join还支持修改加入Join的类的关键字参数,比如DDP的divide_by_initial_world_size,这个参数决定梯度是除以最初的world_size还是有效的world_size(未join的ranks总和)。具体使用如下:
with Join([model, optim], divide_by_initial_world_size=False):
for input in inputs:
...要理解Join背后的原理需要理解两个类:Joinable和JoinHook。所以送入Join的类必须是Joinable,即需要继承这个类,而且要实现3个方法。
- **join_hook(self, kwargs) -> JoinHook:返回一个JoinHook,决定了已经join的ranks跟随其它未join的ranks进行集群操作的具体行为;
- join_device(self) -> torch.device;
- join_process_group(self) -> ProcessGroup;
后面两个方法是Join来处理集群通信所必须的,而join_hook决定了具体行为。DistributedDataParallel和ZeroRedundancyOptimizer之所以能用在Join上是因为它们已经继承Joinable,并实现了这三个方法。
JoinHooK包含两个方法:
- main_hook(self) -> None:如果存在未join的rank,那么已经join的rank在就在每次集群操作时重复执行这个方法,即如何跟随其它未join的rank进行的集群操作;
- post_hook(self, is_last_joiner: bool) -> None:当所有rank都join后,这个方法会执行一次,这里is_last_joiner参数告知这个rank是否是最后join的,注意last joiner可能不止一个;
对于ZeroRedundancyOptimizer,它的main_hook要做的就是执行一次optimizer step,因为虽然它们已经join但依然需要负责更新切分到它们那里的参数更新和同步。对于DistributedDataParallel,它的post_hook要做的是将最后join的rank的模型参数broadcasts到其它ranks,以保证模型参数的一致性。
这里给一个简单的case来展示Joinable和JoinHook是如何具体工作的:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.distributed.algorithms.join import Join, Joinable, JoinHook
BACKEND = "nccl"
WORLD_SIZE = 2
NUM_INPUTS = 5
class CounterJoinHook(JoinHook):
r"""
Join hook for :class:`Counter`.
Arguments:
counter (Counter): the :class:`Counter` object using this hook.
sync_max_count (bool): whether to sync the max count once all ranks
join.
"""
def __init__(
self,
counter,
sync_max_count
):
self.counter = counter
self.sync_max_count = sync_max_count
def main_hook(self):
r"""
Shadows the counter's all-reduce by all-reducing a dim-1 zero tensor.
"""
t = torch.zeros(1, device=self.counter.device)
dist.all_reduce(t)
def post_hook(self, is_last_joiner: bool):
r"""
Synchronizes the max count across all :class:`Counter` s if
``sync_max_count=True``.
"""
if not self.sync_max_count:
return
rank = dist.get_rank(self.counter.process_group)
common_rank = self.counter.find_common_rank(rank, is_last_joiner)
if rank == common_rank:
self.counter.max_count = self.counter.count.detach().clone()
dist.broadcast(self.counter.max_count, src=common_rank)
class Counter(Joinable):
r"""
Example :class:`Joinable` that counts the number of training iterations
that it participates in.
"""
def __init__(self, device, process_group):
super(Counter, self).__init__()
self.device = device
self.process_group = process_group
self.count = torch.tensor([0], device=device).float()
self.max_count = torch.tensor([0], device=device).float()
def __call__(self):
r"""
Counts the number of inputs processed on this iteration by all ranks
by all-reducing a dim-1 one tensor; increments its own internal count.
"""
Join.notify_join_context(self)
t = torch.ones(1, device=self.device).float()
dist.all_reduce(t)
self.count += t
def join_hook(self, **kwargs) -> JoinHook:
r"""
Return a join hook that shadows the all-reduce in :meth:`__call__`.
This join hook supports the following keyword arguments:
sync_max_count (bool, optional): whether to synchronize the maximum
count across all ranks once all ranks join; default is ``False``.
"""
sync_max_count = kwargs.get("sync_max_count", False)
return CounterJoinHook(self, sync_max_count)
@property
def join_device(self) -> torch.device:
return self.device
@property
def join_process_group(self):
return self.process_group
# 用来确定最后join的rank,由于不止一个,可以选择rank最大的rank,以用来同步
def find_common_rank(self, rank, to_consider):
r"""
Returns the max rank of the ones to consider over the process group.
"""
common_rank = torch.tensor([rank if to_consider else -1], device=self.device)
dist.all_reduce(common_rank, op=dist.ReduceOp.MAX, group=self.process_group)
common_rank = common_rank.item()
return common_rank
def worker(rank):
assert torch.cuda.device_count() >= WORLD_SIZE
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(BACKEND, rank=rank, world_size=WORLD_SIZE)
counter = Counter(torch.device(f"cuda:{rank}"), dist.group.WORLD)
inputs = [torch.tensor([1]).float() for _ in range(NUM_INPUTS + rank)]
with Join([counter], sync_max_count=True):
for _ in inputs:
counter()
print(f"{int(counter.count.item())} inputs processed before rank {rank} joined!")
print(f"{int(counter.max_count.item())} inputs processed across all ranks!")
def main():
mp.spawn(worker, nprocs=WORLD_SIZE, join=True)
if __name__ == "__main__":
main()
# output
# Since rank 0 sees 5 inputs and rank 1 sees 6, this yields the output:
10 inputs processed before rank 0 joined!
11 inputs processed across all ranks!
11 inputs processed before rank 1 joined!
11 inputs processed across all ranks!这里的Counter是一个Joinable,功能是用来实现分布式计数,它对应的CounterJoinHook来处理不均匀输入,其中main_hook就是all-reduce一个为0的tensor,而post_hook用来同步最大的count,这里也用了关键字参数。
后话
这个发布的ZeroRedundancyOptimizer其实在PyTorch1.8版本已经支持,不过应该是进行了优化,比如支持Join,但目前的ZeroRedundancyOptimizer其实只是实现的ZeRO-DP-1,应该后续还有优化空间。而Join目前还处于迭代中,后续应该会有更多新的更新。



评论(0)
您还未登录,请登录后发表或查看评论