

核心思想
本文提出一种通过迭代的方式对初始位姿估计结果进行优化的方法(DeepIM)。作者发现目前基于RGB图像的位姿估计算法相对于基于RGB-D图像的位姿估计算法其准确率存在一定的差距,作者认为缺少一种有效的位姿优化方法来解决基于RGB图像位姿估计不准确的问题。作者首先根据初始位姿和目标物体的3D模型,渲染出目标物体在初始位姿下的图像,然后比对初始位姿下的图像和实际观测到的图像之间的差异,如果差异较大则说明初始位姿估计的结果不够准确,反之则位姿估计结果更好。作者利用渲染图像和实际观测图像来预测二者之间的相对位姿变换,这个过程类似于视觉伺服,然后更新初始位姿,再重新生成渲染图像进行比较,直到渲染图像和实际观测图像非常接近时,说明此时的位姿估计结果已经足够准确了。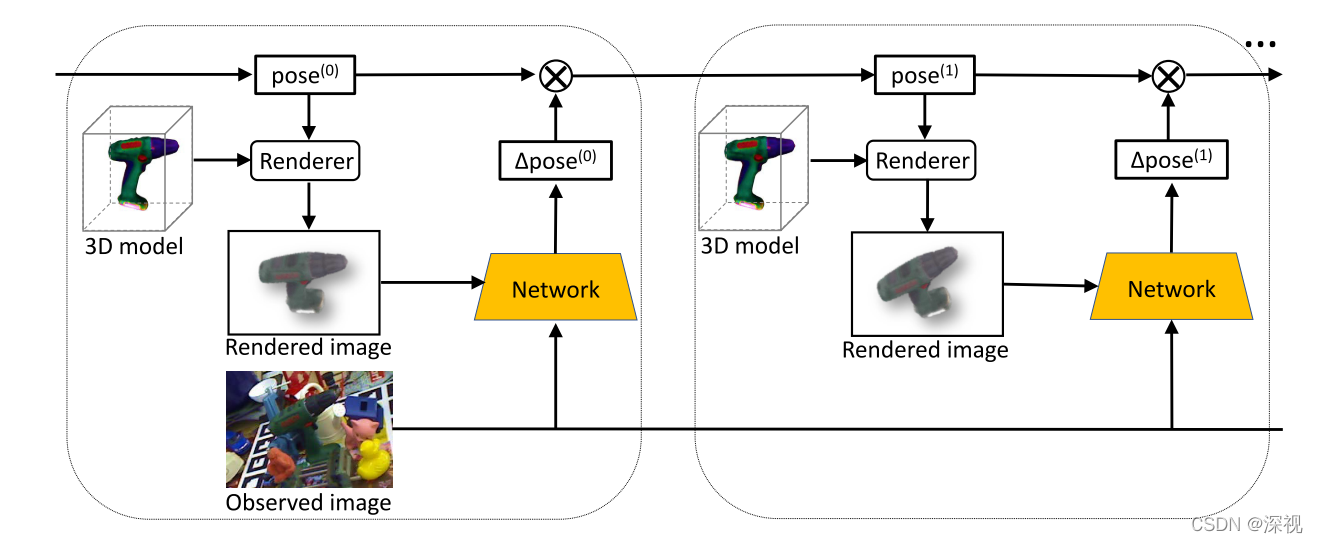
实现过程
首先,作者提出一种高分辨率的放大方法,用于获取目标物体的细节信息,给定一幅观测图像、图像中目标物体的初始位姿和物体的3D模型。根据物体的初始位姿和3D模型,可以渲染得到当前位姿对应的物体图像,然后生成目标物体在观测图像和渲染图像中的掩码图。利用最大外接矩形方法将目标物体从四幅图像(观测图像和渲染图象以及对应的掩码图)中裁剪出来,以3D物体原点的2D投影点为中心,并保证最大外接矩形框都具有相同的长宽比。最后通过双边上采样方法将裁剪得到的图像放大至480 _ 640尺寸。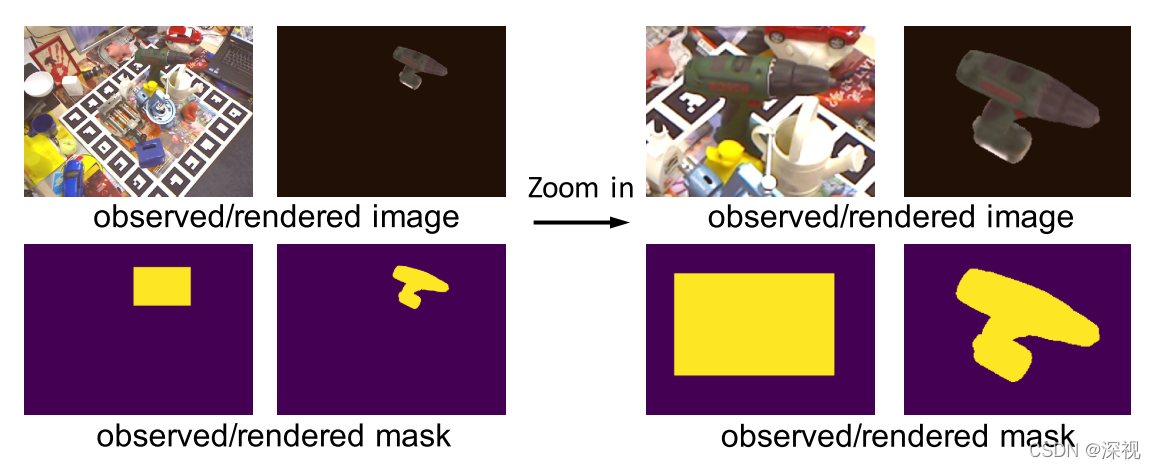
然后,作者将裁剪放大后的观测图像和渲染图象及其对应的掩码图级联起来输入到FlowNetSimple网络中, 该网络是在光流估计的数据集上预训练得到的,该网络输出的特征图经过两个全连接层,再利用两个全连接层分支分别预测旋转和平移参数。为了帮助网络训练更加稳定,作者利用FlowNetSimple网络中的解码器输出一个特征图,并利用两个1 _ 1的卷积层分别预测光流图和掩码图,作为训练中的一种额外监督。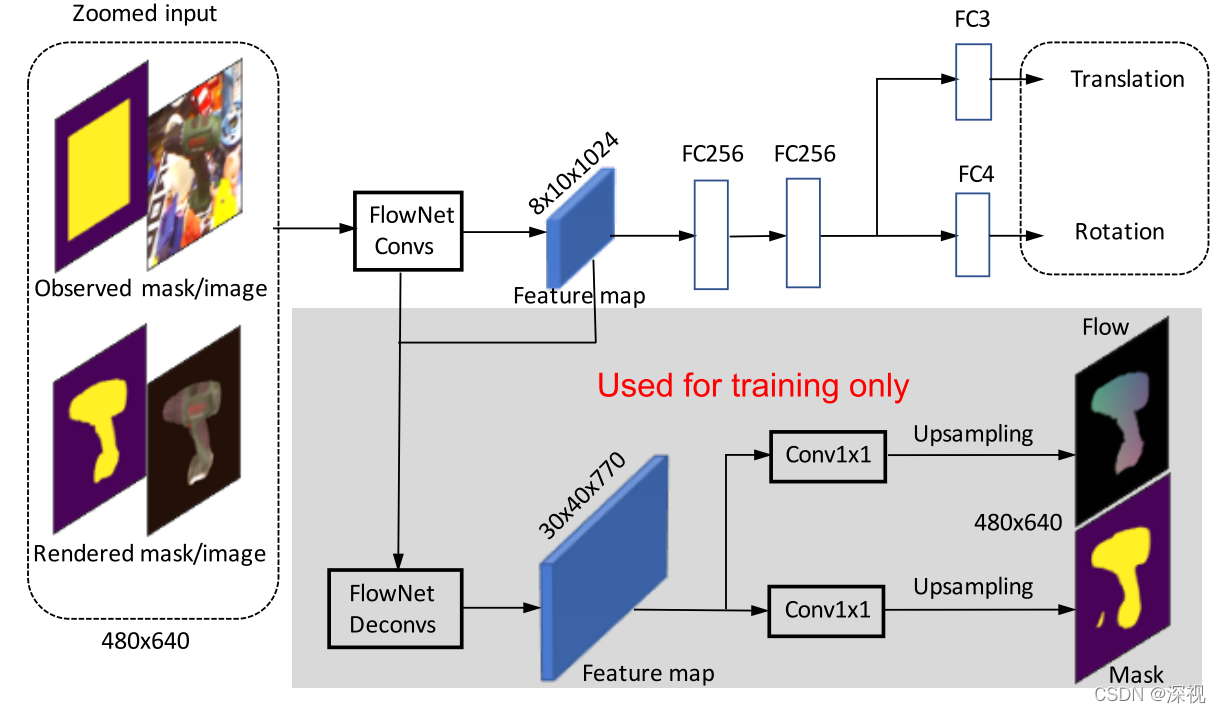
与直接预测平移和旋转矩阵参数的方式不同,本文预测的是观测图像和渲染图像之间的位姿变换矩阵,并且作者提出将旋转和平移拆分开来。在相机坐标系下,如图(a)所示,目标位姿
[
R
t
g
t
∣
t
t
g
t
]
[R_{tgt}|t_{tgt}]
[Rtgt∣ttgt]和当前位姿
[
R
s
r
c
∣
t
s
r
c
]
[R_{src}|t_{src}]
[Rsrc∣tsrc]之间的变换过程如下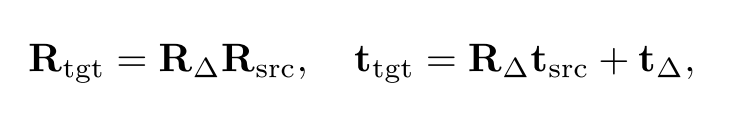
其中
[
R
Δ
∣
t
Δ
]
[R_{\Delta}|t_{\Delta}]
[RΔ∣tΔ]表示位姿变换。
R
Δ
t
s
r
c
R_{\Delta}t_{src}
RΔtsrc说明旋转矩阵不仅会影响物体的旋转运动也会影响物体的平移运动,而且平移变换
t
Δ
t_{\Delta}
tΔ使用3D空间中的度量(如米)这使得距离信息和物体的尺寸耦合在一起,所以就要求网络在预测平移向量时,需要记住每个物体的尺寸,这显然是不合适的。为了解决这个问题,作者将旋转中心从相机原点转移到目标物体的中心,因为当前目标物体位姿(可能不准确)是已知的所以这个转换时可以做到的,这就使得位姿变换中
R
Δ
R_{\Delta}
RΔ和
t
Δ
t_{\Delta}
tΔ是解耦的,旋转变换不会影响平移变换。剩下的问题就是选择坐标系的坐标轴,如果选择物体坐标系作为旋转变换的坐标轴,如图(b)所示,则又需要网络记住每个物体对应的坐标系,因此坐标轴方向选择与相机坐标系保持一致,如图(c)所示。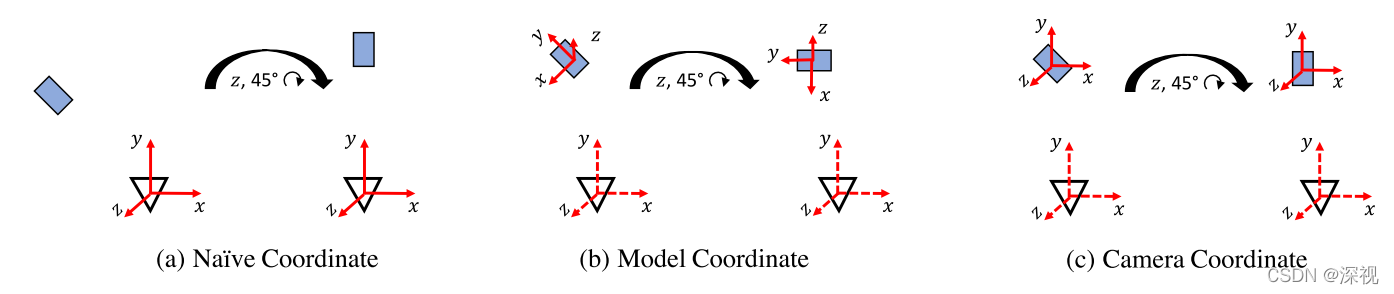
而对于平移变换,作者也不是预测直接的变化量
t
Δ
t_{\Delta}
tΔ,因为在缺少深度信息的条件下预测该值是非常困难的,而是选择预测相对变化量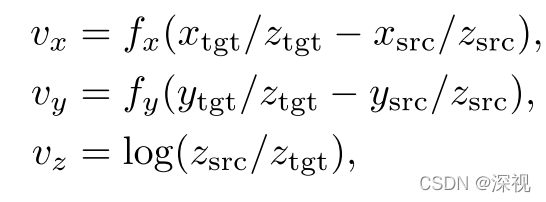
其中
f
x
,
f
y
f_x,f_y
fx,fy表示对应方向上的焦距,
v
z
v_z
vz表现了物体的尺度变化,取对数的目的是保证当物体尺度相同时,
v
z
v_z
vz取0。将旋转变换和平移变换分解开有几点好处,首先它将旋转和平移解耦,彼此不会相互影响;其次,
v
x
,
v
y
,
v
z
v_x,v_y,v_z
vx,vy,vz能够在图像空间中表示物体的位移与尺度变化;第三,这种表示方式不需要任何物体的先验知识,使得网络可以预测没有见过的物体的位姿变换。
最后,计算预测位姿和真实位姿之间匹配程度的损失函数,最直接的方法就是计算旋转参数的角度距离和平移参数的L2距离,然而这两种不同类型的损失函数是很难平衡融合起来的。作者采用了一种集合重投影误差作为损失函数,将目标物体上的3D点分别通过预测位姿和真实位姿投影到2D图像空间中,并计算2D投影点之间的平均距离来度量预测位姿和真实位姿之间的差异,计算方法如下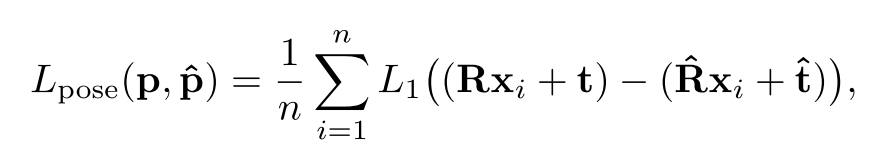
x
i
x_i
xi表示在目标物体模型上采样的3D点,
n
n
n表示采样点个数,本文取3000,
[
R
∣
t
]
[R|t]
[R∣t]表示真实位姿,
[
R
^
∣
t
^
]
[\hat{R}|\hat{t}]
[R^∣t^]表示预测位姿。
在训练和测试过程中,都采用迭代的方式对结果进行优化,根据初始位姿
p
(
0
)
p^{(0)}
p(0)渲染得到的图像
x
r
e
n
d
(
p
(
0
)
)
x_{rend}(p^{(0)})
xrend(p(0))和观测图像
x
o
b
s
x_{obs}
xobs之间仅有商量的视角重叠,随着位姿的不断更新,渲染得到的图像
x
r
e
n
d
(
p
(
i
+
1
)
)
x_{rend}(p^{(i+1)})
xrend(p(i+1))会比渲染得到的图像
x
r
e
n
d
(
p
(
i
)
)
x_{rend}(p^{(i)})
xrend(p(i))更加接近于观测图像
x
o
b
s
x_{obs}
xobs。
创新点
- 设计了一种根据观测图像和渲染图像预测两者之间位姿变换的网络,并将旋转和平移解耦
- 采用一种迭代优化的方式逐步提高位姿估计的准确率
算法评价
本文提出的方法对于基于RGB图像和3D模型的位姿估计方法中是非常有效的,根据试验结果来看能够有效的改进位姿估计的准确性。将旋转和平移相互解耦的思路也非常值得借鉴。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论