

核心思想
本文提出一种基于卷积神经网络的物体分割与位姿估计的方法(PoseCNN)。如下图所示,输入图像经过卷积层特征提取之后,分成三个任务分支:语义分割、平移矩阵预测和旋转矩阵(四元数)预测。最后结合三个分支的预测结果,得到每个物体的位姿估计。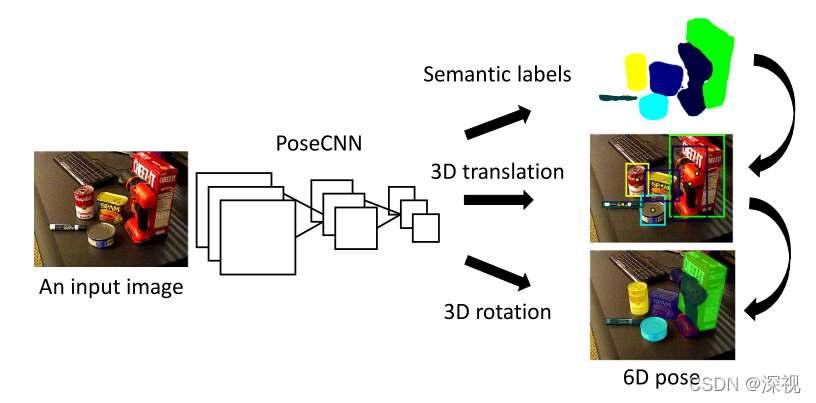
语义分割分支采用了常见的全卷积神经网络方法。平移矩阵的预测并不是直接通过回归的形式输出中心点坐标,因为这种方法当中心点被遮挡时容易失效。而是预测物体上的每个点和中心点之间的连线方向,并预测每个点的深度值,通过投票的方式得到每个物体点的中心点坐标,然后根据语义分割结果计算物体上每个点深度的平均值作为中心点的深度,最后通过反透视变换计算中心点的空间位置坐标。旋转矩阵则是根据物体的外接矩形框构成的ROI,通过回归的方式预测四元数。本文还针对对称物体,提出了一种新的损失函数,并提出一个新的位姿估计数据集YCB-video,目前已经是位姿估计的主流Benchmark。
实现过程
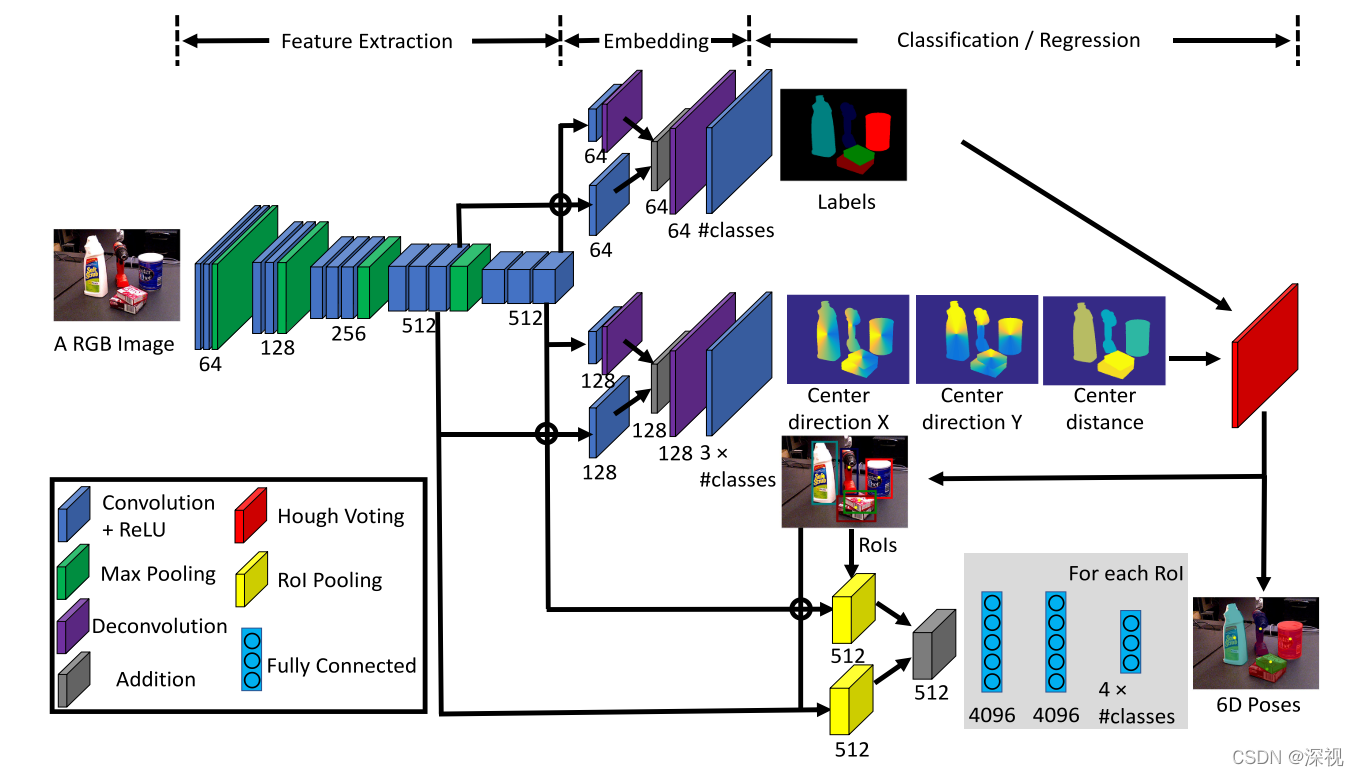
网络的详细结构如上图所示,输入图像首先经过级联的卷积神经网络进行特征提取,该部分采用VGG结构,包含13个卷积层和4个最大池化层。然后网络分成三个任务分支,分别对应语义分割、平移矩阵预测和旋转矩阵预测。对于语义分割任务,作者从特征提取网络中生成两个64通道的特征图,特征图尺寸分别是原图的1/8和1/16。尺寸为原图1/16的特征图经过一个反卷积层恢复到1/8尺寸后,与尺寸为原图1/8的特征图相加,再经过反卷积层恢复到原图尺寸。最后利用softmax层输出每个像素点上的语义标签。
对于平移矩阵预测任务,其网络结构与语义分割网络类似,只不过由于预测参数更多(每个点都包含三个预测值)所以通道数由64变为了128,最后利用通道为3 _ n的卷积层输出每个点的预测结果(n表示物体的类别数量)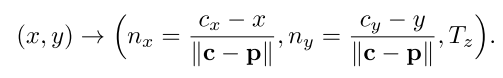
其中
p
=
(
x
,
y
)
\mathbf{p}=(x,y)
p=(x,y)为图中一个像素点,
(
c
x
,
c
y
)
(c_x,c_y)
(cx,cy)表示物体中心点坐标,
n
x
n_x
nx表示X方向上像素点与中心点之间的偏移,并进行了归一化处理,同理
n
y
n_y
ny表示Y方向上的单位偏移,
(
n
x
,
n
y
)
(n_x,n_y)
(nx,ny)则构成了像素点和中心点之间的单位方向向量,
T
z
T_z
Tz表示像素点的预测深度。得到每个点的预测结果后,采用Hough投票的方法计算每个物体的中心点坐标。根据语义分割的结果,对每个类别的物体,计算所有像素点的投票得分,投票得分的高低就对应了该点是物体中心点的概率。每个像素点的投票得分是根据其他像素点和中心点的方向向量经过该点的次数来计算的,如下图所示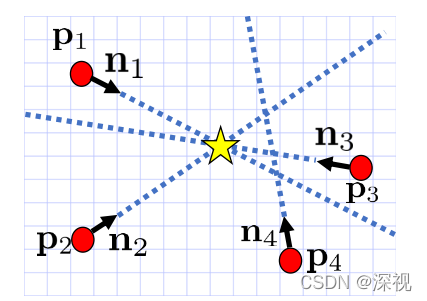
如果一个点位于许多其他像素点和中心点连线的交汇处,那么这个点就很有可能是中心点。通过投票法得到中心点坐标后,再根据语义分割结果计算属于该中心点对应物体的所有像素点深度的平均值,作为中心点的深度值。已知中心点的图像坐标和深度值,利用反透视变换,即可求得中心点的空间位置坐标,其关系如下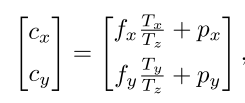
其中
f
x
,
f
y
f_x,f_y
fx,fy表示相机的焦距,
p
x
,
p
y
p_x,p_y
px,py表示相机原点(主点)坐标。
对于旋转矩阵预测任务,本文根据语义分割和中心点预测结果得到每个物体的外接矩形框,然后利用ROI池化层,对特征图进行先裁剪后池化的操作,经过三层的全连接层后输出4 _ n个预测结果,对应
n
n
n类物体的四元数。
语义分割任务采用交叉熵损失函数,平移矩阵预测任务采用L1损失函数,旋转矩阵预测任务采用两个损失函数,第一个是位姿损失PLoss: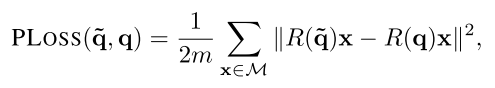
其中
M
\mathcal{M}
M表示物体3D模型点的集合,
m
m
m表示3D点的数量,
R
(
q
~
)
R(\tilde{q})
R(q~)表示预测的旋转矩阵,
R
(
q
)
R(q)
R(q)表示真实旋转矩阵。当预测姿态和真实姿态完全相同时,该损失函数取得最小值。但是对于对称的物体,可能存在多个正确的姿态(比如对于一个轴对称图形,其关于对称轴旋转180°仍然算是正确的姿态),而该函数只对其中一个姿态认为是正确的,其他姿态下损失函数较大,会导致训练过程不稳定。因此本文又提出了形状匹配损失SLoss: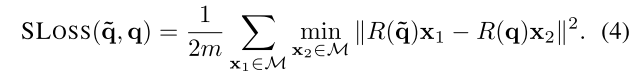
在PLoss的基础上做了一点点改进,只计算与当前预测点距离最近的点之间距离损失,只要当两个3D模型相互匹配时,该损失即为最小值,这样就不会对对称物体等效的旋转进行惩罚。
虽然根据上述过程就能够根据输入图像获取物体的位姿估计结果了,但是为了提高位姿估计的准确性,作者还利用深度图和3D模型得到物体每个像素点的3D坐标,并利用ICP方法对位姿估计结果进行优化。根据试验结果来看,ICP优化对应位姿估计准确性的提高有明显的效果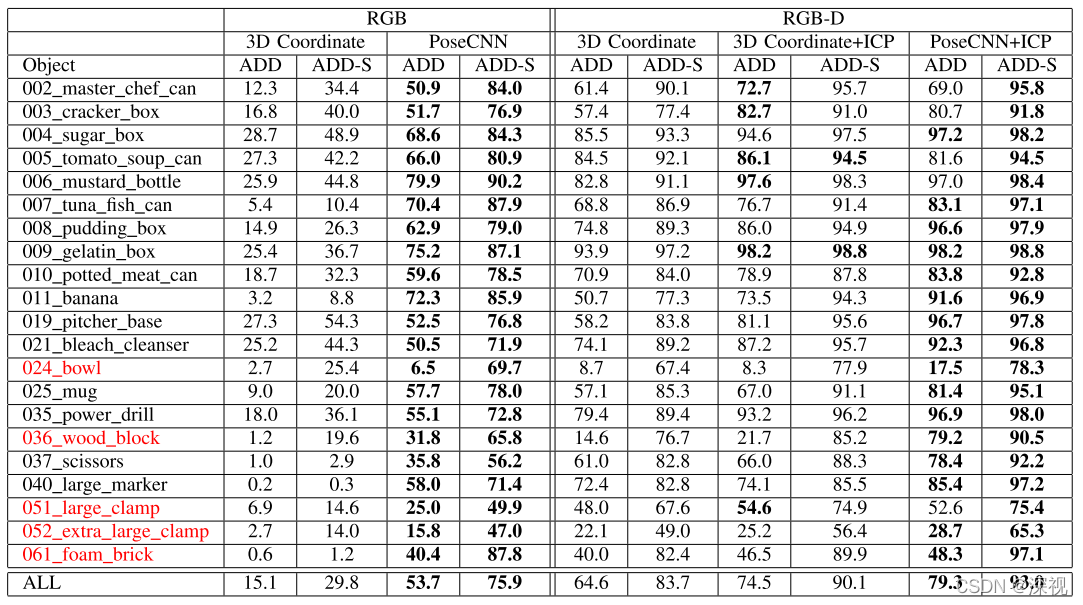
最后,作者提供了一个包含21件物体,133827帧图像的位姿估计数据集(YCB-Video),并提供了对应的深度图、语义分割图和3D模型。
创新点
- 提出一种基于卷积神经网络的位姿估计方法,通过投票的方式来预测物体中心点坐标
- 提出一种形状匹配损失函数,用于解决对称物体的旋转矩阵监督问题
算法评价
相对于直接利用神经网络回归位姿的方法,本文将旋转矩阵和平移矩阵分开预测,并利用投票法和深度估计来计算平移矩阵显然是更多的融合了先验的知识,提供了更多的约束,而不是单纯的依赖网络的映射能力。但是网络本身的语义分割、深度估计,相对方向的预测任务都是特异性很强的,即需要网络充分提取目标物体的特征信息,但这会导致一个问题泛化困难。对于没有见过的物体,本文的方法恐怕是很难准确的预测出分割结果和深度信息的,这在另一个数据集LineMOD的实验结果也能够很明显的体现出来。另外本文虽然可以只利用RGB图像进行位姿估计,但是如果不经过ICP优化其预测精度是比较差的,说明仅利用RGB图像进行预测还是存在一定的难度。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论