

核心思想
本文提出一种基于稠密匹配的位姿估计和优化方法(DPOD)。之前介绍的基于关键点匹配或控制点匹配的位姿估计方法都是基于稀疏匹配的方法,利用PnP算法进行求解。这类方法的问题在于匹配点的数量较少,受误匹配点的影响较大,导致位姿估计的鲁棒性较差。而本文则是利用立体投影(球面投影或圆柱投影)将3D模型上的点映射到一个两通道的二维UV图上,本文称之为对应映射(或匹配映射,Correspondence Map)。然后利用神经网络去预测图像中的每个像素点对应的UV值,进而构建起2D-3D之间的稠密映射关系。最后利用RANSAC+PnP方法计算位姿,并根据预测位姿渲染得到图像和真实输入图像之间的差异来对位姿估计结果进行优化。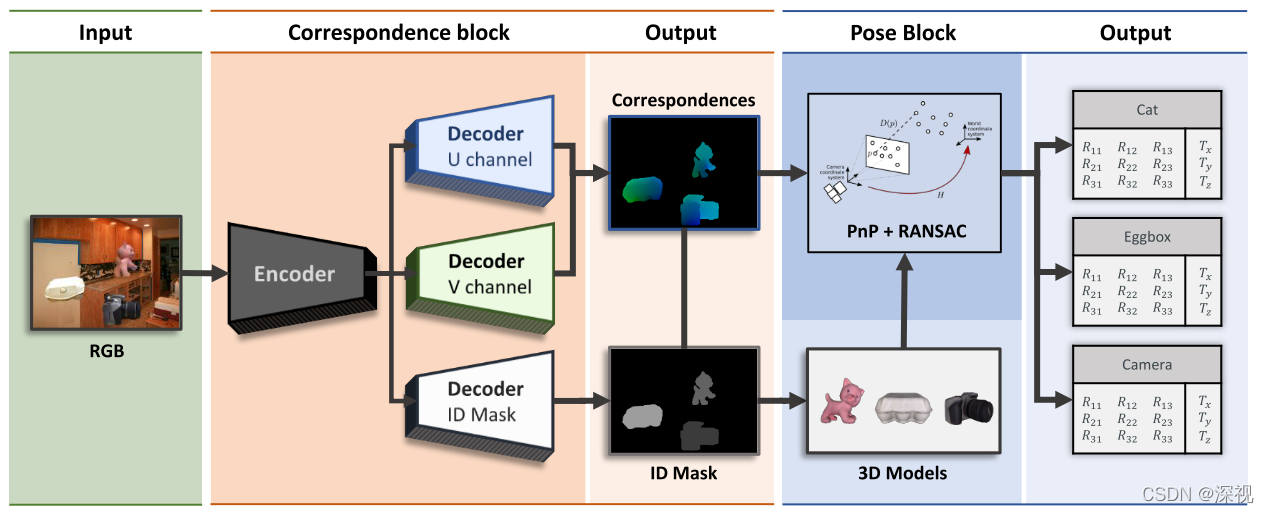
实现过程
首先构建训练的数据集,数据集包含真实数据和合成仿真数据。真实数据的优点在于其与实际物体非常接近因此能够获得更快的收敛速度和更准确的结果,缺点在于检测算法会对训练数据的光照、位姿、尺度等条件产生偏好,导致在实际图像中的泛化能力较差。合成数据的优点在于可以生成无数种不同条件下的图像,但生成图像和真实图像之间的差异需要克服。得到图像数据集后,要将3D模型上的点和2D图像中的像素对应起来。本文并没有采用将像素映射到一个三维空间坐标的形式,而是先利用立体投影方法将3D模型上的点对应到一个2通道的UV图中,UV图中每个点的取值范围为[0,255],则理论上2通道的UV图可以表示
A
256
2
A^2_{256}
A2562个3D坐标点。这个2通道的UV图(如图中(2)所示)的每个像素都有一个独一无二的编码值(由[0,255]中的两个数字组合成),利用立体投影法,将模型(如图中(1)所示)上的每个点都投影到UV图上,则模型上的每个点都得到一个独一无二的编码值,称之为对应模型(如图中(3)所示)。这一过程称为对应映射,其构建了2D与3D之间双向映射关系,即得到一个UV值就能找到其唯一对应的3D模型上的点。上文提到的立体投影是一种将立体图形投影到二维平面上的方法,包含球面投影、柱面投影多种方式,比如绘制世界地图的墨卡托投影法就是一种球面立体投影法。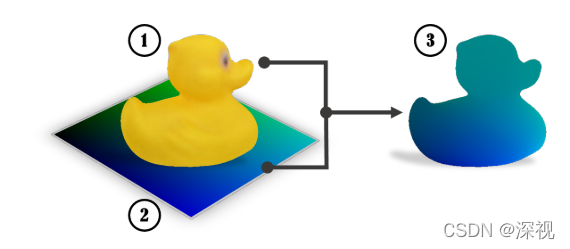
网络根据输入的RGB图像,先利用一个编码器提取其特征信息,然后使用三个解码器分别预测每个像素点的U值、V值和所属的类别。由于前文已经将模型映射到二维UV图上,因此只要预测得到每个像素点的UV值,就可以找到对应的模型上的3D点。UV值解码器的结构完全相同,输出
H
×
W
×
C
H\times W\times C
H×W×C维预测结果,
H
、
W
H、W
H、W分别表示图像的高和宽,
C
C
C表示通道数,本文取256代表UV值得取值范围。每个通道中每个像素点的预测值表示该像素点对应该通道号的概率值,比如说通道
i
i
i中的第
j
j
j个像素点的预测值为0.05,则表示该像素点对应的U值(或V值)为
i
i
i的概率是0.05,取概率值最大的通道数作为该像素点的预测结果。预测类别的掩码器与普通的语义分割方法类似,每个像素点输出属于某个类别的概率,选择概率最大的类别来代表该像素。
根据UV值预测结果并结合类别信息可以得到图像中每个像素点对应的3D模型点,然后再利用RANSAC+PnP算法进行位姿估计,得到图像中每个物体对应的初步位姿估计结果。由于采用稠密的匹配方法,因此RANSAC迭代次数可以更多,本文选择迭代150次,保证了位姿估计的鲁棒性。、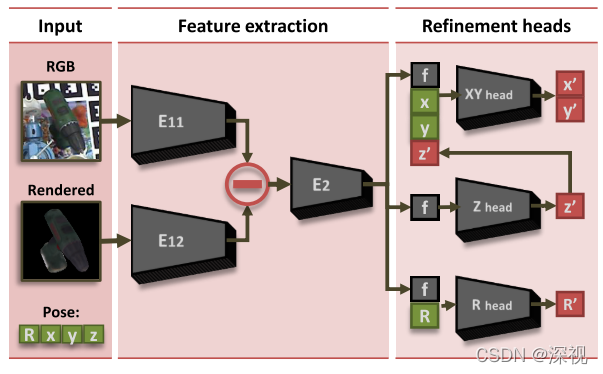
最后,是对初步位姿估计结果进行优化。本文的优化思路是根据初步位姿估计结果生成模型的渲染图像,然后分别用两个编码器提取输入图像和渲染图像的特征向量,特征向量做差在输入下一级编码器(E2),得到特征向量
f
\mathbf{f}
f。分别使用三个预测头来预测优化后的平移矩阵中的
X
,
Y
X,Y
X,Y坐标,
Z
Z
Z坐标和旋转矩阵。
创新点
- 利用立体投影和UV图将3D模型投影到2D图像中,建立起稠密的对应关系
- 根据RGB图像分别预测UV值和类别掩码构建稠密的2D-3D匹配
- 设计了一种新的位姿优化方法,将平移矩阵中的
X
,
Y
X,Y
X,Y和
Z
Z
Z坐标解耦
算法评价
本文最大的创新应该是体现在使用稠密的匹配关系来预测位姿,而不是类似关键点和控制点那种稀疏的匹配关系,这就使得对误匹配点的鲁棒性更高。另外就是利用立体投影将稠密的3D点投影到二维的图像中,这使得网络无需预测三维坐标点,只要输出二维离散的UV值,这降低了网络训练的难度。从结果来看本文在仅使用RGB图像和模型信息的方法中,效果是比较好的。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论