

核心思想
本文提出一种基于3D关键点的位姿估计方法,其思想在于利用一张RGB图像作为参考图像,通过将测试图像和参考图像之间进行关键点匹配,再利用Kabsch算法得到两幅图像之间的位姿变换,进而根据参考图像的位姿得到测试图像的位姿。与其他的位姿估计方法不同,本文在训练过程中只需要已知相对位姿变换的一对图片(每次训练需要一对,整个训练过程还是需要许多对图像的)。相对于需要大量的已知位姿的图像数据集,只得到两张相对位姿已知的图像是比较容易的,比如用两个位姿已知的相机拍摄同一个物体,就能根据相机的位姿变化,得到两张图像之间的相对位姿。
实现过程
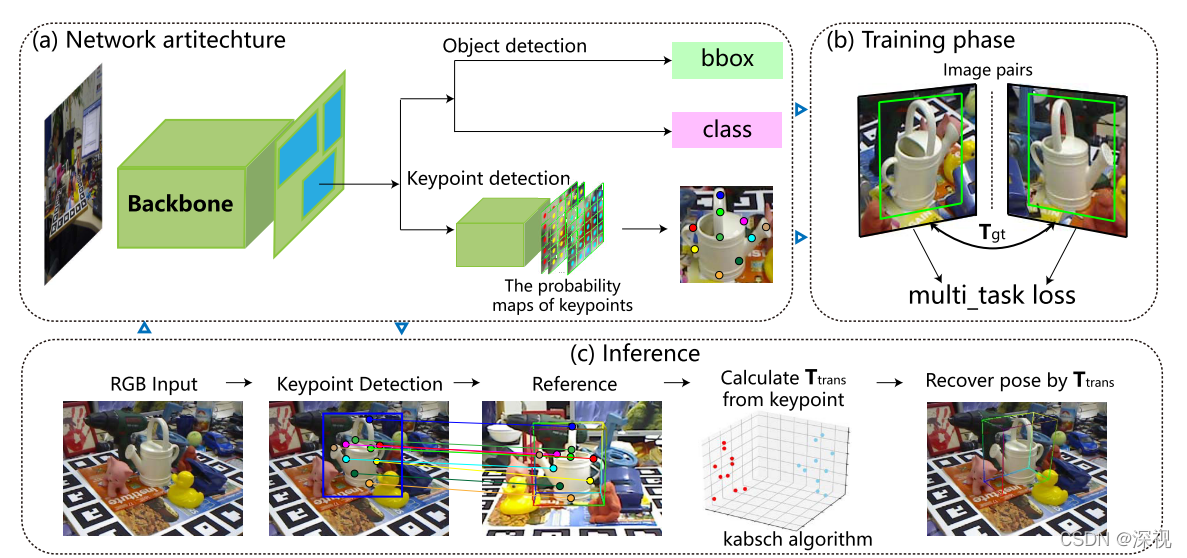
首先,利用一个ResNet主干网络从图像中提取特征信息,并使用FPN网络得到若干个可能存在目标物体的感兴趣区域(ROI)。将ROI分别输入到两个网络分支中,一个分支采用Faster-RCNN的结构用于实现目标检测输出边界框与类别,另一个分支则是输出关键点的概率图和深度信息。关键点检测分支输出
N
+
1
N+1
N+1个通道的预测图,其中
N
N
N表示预测关键点的个数,前
N
N
N个通道的特征图分别表示每个像素点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)是第
i
i
i个关键点的概率
P
i
P_i
Pi,则关键点的预测坐标为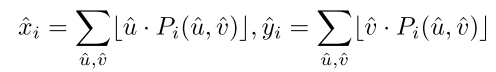
最后一个通道的特征图表示每个像素点上预测的深度值。为了对关键点检测分支进行训练,本文提出了五个损失函数:
- 跨视野连续性损失(Cross-view Consistency Loss)。该损失用于约束两张图像的关键点之间的连续性,图像
I
I
I中的每个关键点
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)经过两幅图之间的相对位姿变换都应映射到
I
′
I’
I′中的匹配点
(
x
′
,
y
′
,
z
′
)
(x’,y’,z’)
(x′,y′,z′),反之亦然。则一对匹配点之间的关系如下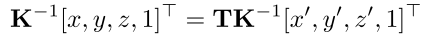
其中
T
T
T表示图像之间相对位姿变换,
K
K
K表示相机内参矩阵。成对的匹配点应映射到相机空间中的相同的位置: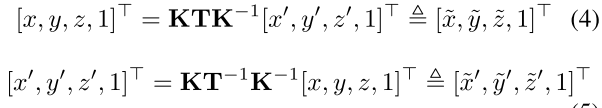
则损失函数定义为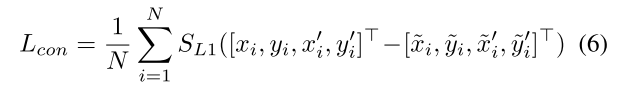
S
L
1
S_{L1}
SL1表示平滑的L1损失函数。 - 深度回归损失(Depth Regression Loss),为了能够预测3D关键点,需要对深度信息进行预测。在已知两幅图像之间的位姿变换矩阵和图像之间的匹配点的条件下,可以根据对极几何原理计算深度信息,计算方式如下
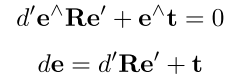
其中
e
=
[
x
,
y
,
1
]
T
e=[x,y,1]^T
e=[x,y,1]T,
e
′
=
[
x
′
,
y
′
,
1
]
T
e’=[x’,y’,1]^T
e′=[x′,y′,1]T表示一对匹配点的2D齐次坐标,
e
∧
e^{\wedge }
e∧表示斜对称矩阵,
d
,
d
′
d,d’
d,d′分别表示两个匹配点的深度。根据公式1利用最小二乘法,可以计算得到
d
′
d’
d′,然后根据公式2可以计算得到
d
d
d。得到真实深度信息后,就可以对预测深度进行监督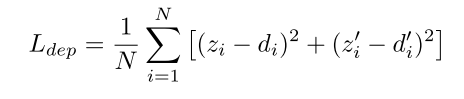
- 显著度损失(Distinctiveness Loss),该损失函数是鼓励从视觉显著的位置选取关键点。为实现该目标,本文首先得到每个点的何塞矩阵(Hessian matrix),何塞矩阵表示该像素点与其相邻像素点之间的变化程度。如果某个点其3*3的邻域内的何塞矩阵的行列式为最大值,则这个点被标记blob-like点
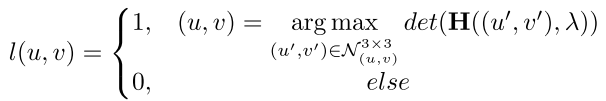
考虑到预测的3D关键点可能出现在物体被遮挡的区域,为了避免与跨视野连续性损失出现冲突,本文假设至少有一半的关键点是可见的,因此只对一半的关键点进行显著性约束,则损失函数为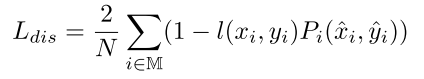
其中
M
\mathbb{M}
M表示排名前
N
/
2
N/2
N/2的关键点,
P
i
(
x
^
i
,
y
^
i
)
P_i(\hat{x}_i,\hat{y}_i)
Pi(x^i,y^i)表示
(
x
^
i
,
y
^
i
)
(\hat{x}_i,\hat{y}_i)
(x^i,y^i)为关键点的概率值。 - 分离损失(Separation Loss),该损失鼓励关键点之间的距离超过参数
δ
\delta
δ,也就是说会对相邻两个关键点之间的距离小于
δ
\delta
δ的点进行惩罚,损失函数为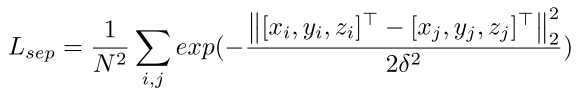
- 变换恢复损失(Transformation Recovery Loss),该损失要求根据匹配点估计得到的相对位姿变换
R
′
R’
R′和
t
′
t’
t′与真实的相对位姿变换
R
R
R和
t
t
t应该尽可能相近,本文采用测地距离损失函数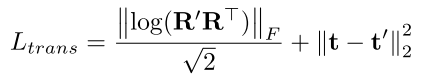
最终利用目标检测分支的分类损失和边界框回归损失,关键点检测分支的五个损失函数,以及负样本的分类损失构成总的损失函数,对整个网络进行训练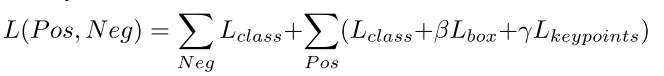
创新点
- 利用两幅图像之间的相对位姿变换信息对关键点预测进行约束,并利用参考图像位姿和预测得到相对位姿变换计算测试图像的位姿
- 设计了五个损失函数用于关键点预测网络的训练
算法评价
本文最大的突破在于利用两幅图像之间的相对位姿变换来对网络进行训练,而不需要依赖大量的已知位姿的图像,这就给网络的训练降低了难度,可以通过采样匹配图像对来进行训练。但是相对而言,本文预测的位姿精度较低,但考虑到本文只需要RGB图像且无需依赖模型,这个结果还是有一定价值的。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论