

文章题目:Traffic Sign Classification Using Deep Inception Based Convolutional Networks
开源代码地址:https://github.com/vxy10/p2-TrafficSigns
一、概述
本篇文章提出了一种基于深度学习的交通标志识别方法,网络以Google Inception网络模型为基础,做了一些改进,并增加了空间转换网络,以使该方法能够对不同角度看到的交通标志都能有效识别。
二、算法流程
网络分为两部分,一个是空间转换网络,一个是特征识别网络(Inception),所以我们也分两部分介绍
1.空间转换网络
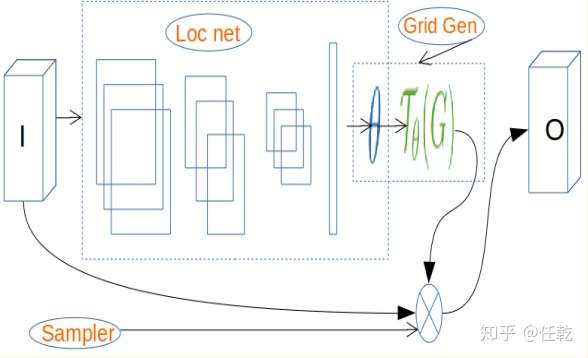
空间转换网络的整体结构如图中所示,其主要目的就是把一个非正视角度的图片转换为正式角度,同时,把不在图片正中心的标志转换到图片中心,所以这里的 大家自然也就明白是啥了,就是一个旋转加上一个平移,具体的形式如下:
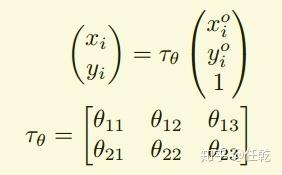
其中, 组成旋转矩阵,
为x和y方向上的平移。
作者认为,这种旋转和平移,会对提高算法的鲁棒性起到很好的作用。
2.特征提取网络
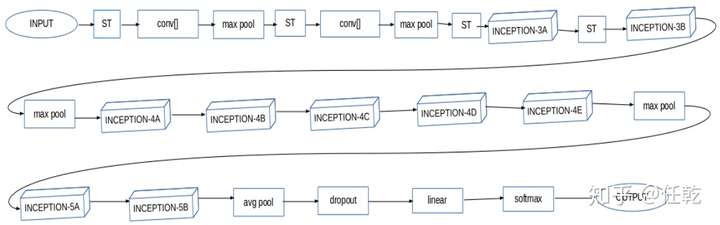
作者所使用的网络是在Inception模块的基础上改进而来,改进前后的网络模型图如下:


从图片中可以看出,作者增加了一个模块(1X1卷积->3X3卷积->3X3最大值池化),这个模块主要起作用的还是1X1卷积部分,毕竟1X1卷积的优点大家是知道的:
1) 实现跨通道的信息交互和整合
2) feature map通道数上的降维
3) 增加非线性映射次数
最终,作者的整体网络结构如下:
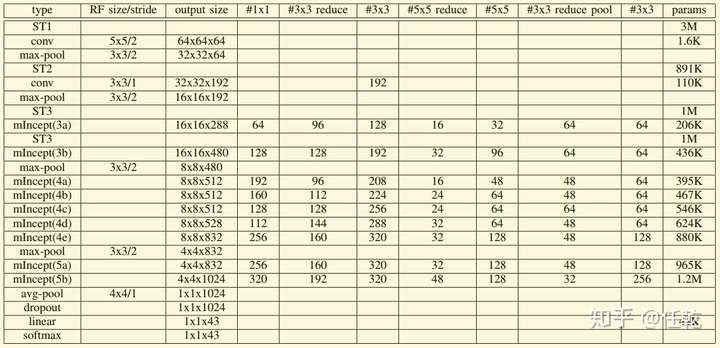
作者还给出了一个表格,详细介绍每一部分的内容
三、实验结果
交通标志识别以识别准确率作为评价指标,对比了本方法和其他方法的结果,实验结果显示本方法取得了最好的性能

四、总结与思考
作者提出了一个深度学习网络用于交通标志识别,网络以GoogleNet为原型,并对Inception模块做了改进。为了提高鲁棒性,作者又在网络中增加了空间旋转网络,以适应变化不同视角观测交通标志带来的影响。最终结果就state-of-art了,不过是在2016年
一点思考:
神经网络应该本来就具有旋转不变性,为啥还需要增加一个空间旋转网络,把标志映射到图片中心呢?



评论(0)
您还未登录,请登录后发表或查看评论