

内容列表
1 引言
YOLO在YOLOv1的基础上做了不少的改进,其中在VOC2007数据集上的map由63.4提升到78.6,并且保持检测速度.
从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进.

YOLOv2的论文链接: 戳我
接下来我们重点分析YOLOv2在YOLOv1的改进点有哪些.
闲话少述,我们直接开始 :)
2 相关改进
2.1 BN层
作者在每层卷积的后面都加入了BN层,不再使用dropout,采用该策略后,mAP提升了2.4%
- BN层可以提升模型的收敛速度,降低过拟合的状况
2.2 提高输入分辨率
大部分检测模型使用的是ImageNet分类数据集上的预训练模型,YOLOv1采用224X224的图像皮草分类器,但是其分辨率较低,不利于检测模型,因此YOLOv2提高输入图像分辨率至448X448,并在检测数据集上进行fine-tuning.
如果直接切换高分辨率,模型可能难以快速适应高分辨率,所以YOLOv2的pre-traing分为以下两个步骤:
- 先采用224X224的ImageNet数据集图像进行大概160epoch的训练,然后再将输入图像更改为448X448训练10个epoch
- 训练完的这个pre-train model可以使用高分辨率的输入,最后在拿这个模型在检测数据集上fine-tuning, mAP提升了3.7%
2.3 采用Anchor Box
因为YOLOv1在训练过程中学习适应不同物体的形状比较困难,导致在精确定位方面表现较差.作者借鉴了Faster R-CNN的方法:用卷积层与RPN来预测Anchor Box的偏移值与置信度,作者发现通过预测偏移量而不是bounding box 坐标值可以简化问题,让神经网络学习起来更加容易,因此YOLOv2也尝试采用不同形状的矩形作为锚框(Anchor Box).
YOLOv2首先移除掉YOLOv1网络中的全连接层,改用Anchor Box来预测边界框.跟YOLOv1不一样的是Anchor Box不是直接预测Bounding Box的坐标值,而是预测Anchor Box的 offset(坐标的偏移量)与confidence(置信度).
为了使最后的卷积层可以有更大的分辨率,YOLOv2将其中一个Pooling层去掉,并且用416X416大小的输入代替原来的448X448,目的是为了是网络输出的特征图有奇数大小的宽和高,进而使每个特征图在划分网格的时候只有一个中心单元格.
为什么是采用416X416的大小的输入代替原来的448X448呢?
- YOLOv2的卷积层采用32步长来下采样,所以通过选择416X416用作输入尺寸最终能输出一个13X13的特征图
为什么要使每个feature map在划分grid的时候只有一个中心单元格呢?
- 因为物体倾向出现在图像中央,物体中心点往往落入图片中心位置,因此使用这个中心单元格去预测这些物体的边界框相对容易
虽然采用Anchor Box之后,模型的mAP从69.5略降低到69.2,但是召回率从81%提高搞88%.也就是说,即使精度略有下降,但是采用Anchor Box增大了检测所有gt物体的机会.
2.4 尺寸聚类
在FasterRCNN中,Anchor Box的尺寸是手动选择的,有一定的主观性.若能选取合适的Anchor Box,可以使模型更加容易学习并预测出准确的bounding box,因此YOLOv2采用k-means聚类方法对训练集中物体的bounding box做了聚类分析.
聚类的目的是为了提高选取的Anchor Box和同一个聚类下的gt框之间的IOU,采用的距离公式如下:
- centroid为聚类时被选作中心的bounding box
- box为其他的bounding box
下图所示为VOC和COCO数据集上的聚类分析结果,综合考虑模型复杂度和召回率,作者最终选择了5个聚类数(K=5),也就是选了5个不同大小的Anchor Box来进行定位预测

来看一下结果分析,作者采用5个不同大小的Anchor Box,平均IOU为61,比不使用聚类方法的9种Anchor Box的平均IOU高一些.若选择聚类IOU为9时,平均IOU更显著提高,如下所示:

2.5 直接位置预测
在早期训练时,因为引入Anchor Box来预测offset导致模型不稳定,这时因为位置预测的公式没有做任何约束,因此训练的模型预测出的bounding box的中心点可能出现在任何位置.
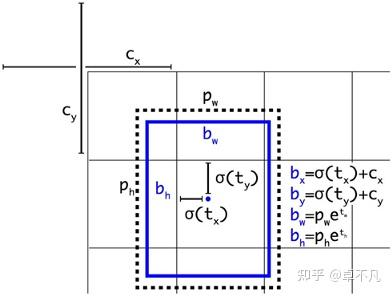
YOLOv2调整了预测公式,使用sigmoid处理,使其范围约束在(0,1)之间,经预测的bound box中心点约束在所属的网格内:

上述公式中:
为预测框的中心点坐标和宽高
是预测框的置信度
YOLOv1是直接预测置信度,YOLOv2则是对进行
转换后作为置信度的值
是当前网格左上角到图像左上角的距离(要先将网格大小归一化,即令grid的宽高都为1)
是Anchor Box的宽和高
是预测Anchor Box的offset和confidence
前面有提到说YOLOv2改用Anchor Box来预测offset(坐标的偏移值)与confidence scores(置信度),因此每个bounding box输出会有5个预测值
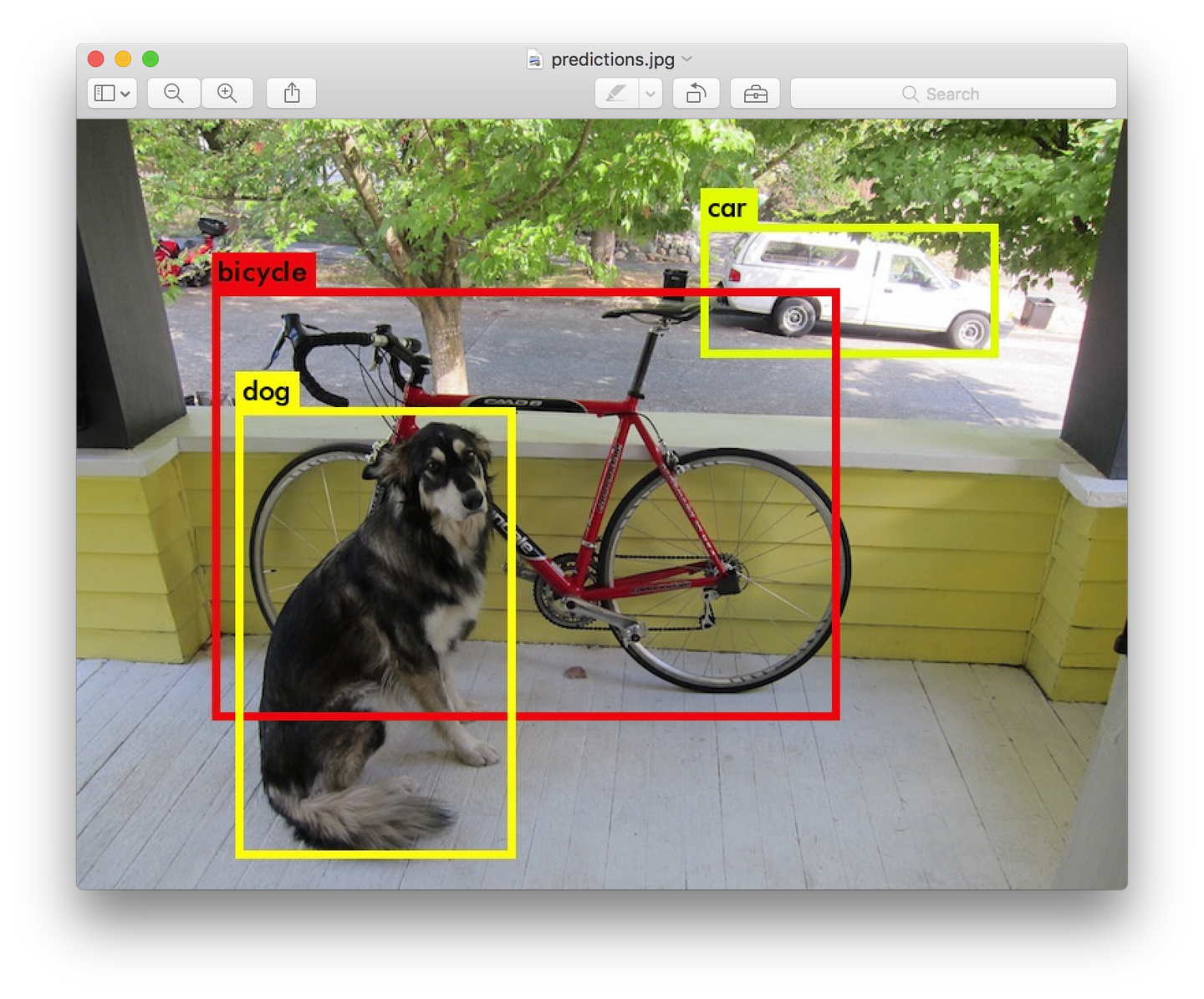
上图中,蓝色框为预测框,虚线框为Anchor Box
2.6 YOLOV1 VS YOLOV2 输出对比
接下来我们来对比YOLOv1和YOLOv2的输出:

如上图所示:
- YOLO v1在特征图(7X7)的每一个grid中预测出两个bounding box及分类概率值,每个bounding box预测5个值
- YOLO v1的总输出为 7X7X(5X2+20)
- YOLO v2在特征图(13X13)的每一个grid中预测5个bounding box(对应5个Anchor Box),每个bound box预测5个值以及分类概率值
- YOLO v2的总输出为 13X13X5X(5+20)
2.7 网络结构
YOLOv2采用了一个新的特征提取主干 Darknet-19,包括19个卷积层,5个maxpooling层
- 该主干原型设计与VGG16一致,主要采用3X3卷积,2X2max pooliing层(feature map维度降低2倍,通道数增加2倍)
- 与NIN(Network in Network)类似,Darknet-19最终采用global avgpooling做预测
- 在3X3卷积层之间使用1X1卷积层来压缩特征图通道数以降低模型的计算量和参数量
- 每个卷积层后面同样使用了BN层以加快模型收敛速度,降低模型过拟合
Darknet-19模型架构如下:

在ImageNet分类数据集上,Darknet-19的top-1准确率为72.9%,top-5的准确率为91.2%,mAP值没有显著提升,但是模型的参数量相对较小,计算量可以较少约33%.
2.8 特征融合
YOLOv2图像的输入大小为416X416,经过5次下采样后得到13X13的特征图,并以此特征图采用卷积来做预测,足够预测大物体,但是若要预测小物体还需要更精细的特征图,因此YOLOv2提出了一种 passthrough 层用以利用更加精细的特征图.
- passthrough层与ResNet网络的shortcur类似,使用前一层更高分辨率的特征图作为输入,然后将其连接到后面一层低分辨率的特征图上
- YOLOv2利用最后一层下采样的输入(也就是26X26X512的特征图)经过passthrough处理,变成13X13X3072的特征图,在此特征图上利用卷积做预测,YOLOv2的mAP提升了1%
之所以是26X26是因为最后一层下采样输入的特征图的维度是输出特征图的2倍
passthrough layer的处理过程如下:

将特征进行重新排列(不涉及到参数的学习),26X26X512的特征图使用按行隔行采样的方法,提取2X2的局部区域,然后将其转化为channel维度,变成13X13X2048的新的特征图,然后在连接下一层13X13X1024的特征图,最后形成13X13X3072的特征图,相当于做了一次特征融合,有利于检测小目标.
2.9 多尺度训练
由于YOLOV2的模型只有卷积层与maxpooling,所以输入可以不限制于416X416大小的图片.为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,就是在训练过程中每间隔一定的迭代次数后改变输入图像的大小:

- YOLOv2下采样步长为32,因此输入图片大小要选择32的倍数(最小尺寸为320X320 最大尺寸为608X608).在训练过程中,每隔10次迭代随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练.
采用多尺度训练后使得YOLOv2模型可以更好的预测不同大小的输入图片,由下图VOC数据集上的结果可以看到:
- 采用较低分辨率的图片mAP值略低,但是速度更快
- 采用较高分辨率的图片mAP值较高,但是速度较慢

3 总结
本文介绍了YOLO V2的网络架构和相应的具体实现细节,YOLOv2相比YOLOv1进行了多个方面的改进,在速度和性能上都有了很大的提升,推荐大家有时间尽量阅读一下原文.



评论(0)
您还未登录,请登录后发表或查看评论