

核心思想
本文提出一种基于RGB-D图像预测目标物体位姿的方法(DenseFusion)。首先,利用一个语义分割网络得到目标物体的分割图像,分别用两个网络用于处理RGB图像和点云图(由深度图获得),将颜色特征和几何特征逐像素的拼接起来,并利用一个特征融合网络获得全局特征。然后将全局特征级联到每个像素的特征向量上,并利用位姿预测网络输出每个像素点对应的位姿估计结果和一个置信度值,最终选择置信度最大的像素点对应的位姿估计结果。本文在此基础上还提出了一种基于深度学习的迭代优化方法,能够在上一次位姿估计的基础上,不断优化位姿估计的结果。流程图如下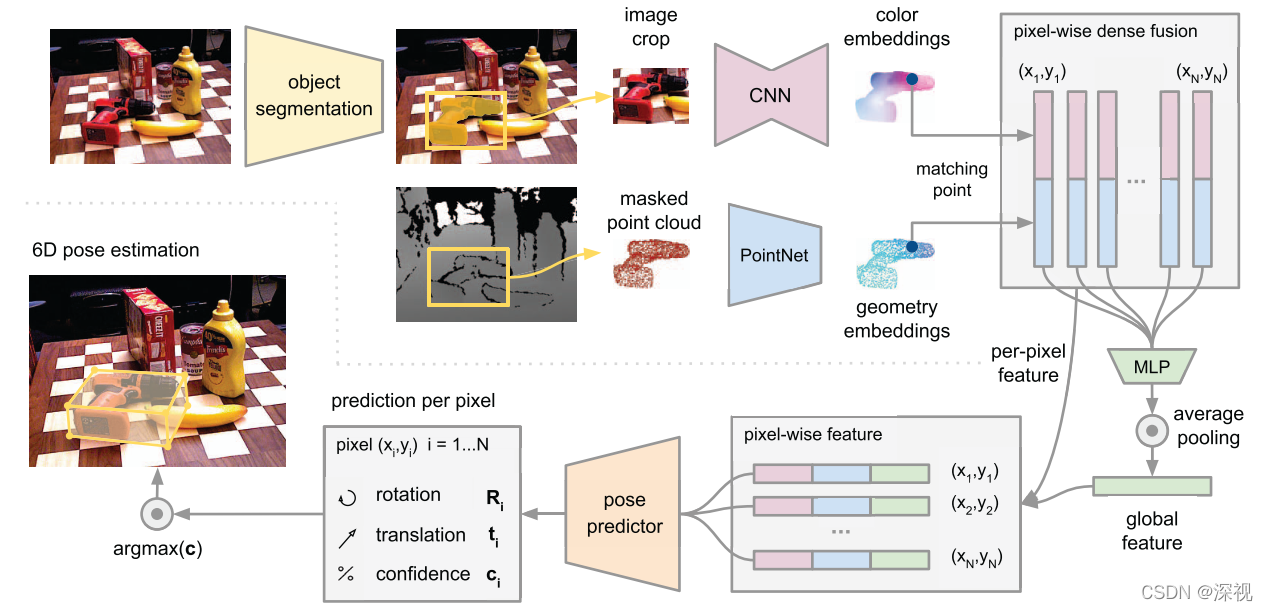
实现过程
首先,输入的RGB图像经过一个语义分割网络得到目标物体的掩码图和外接框,利用分割掩码结果从深度图中提取到目标物体的点云,并用外接矩形框从RGB图中裁剪目标物体所在位置的图块。然后分别用CNN和PointNet网络从点云和图块中提取几何特征和颜色特征。目标物体包含
P
P
P个点,每个点都对应一个长度为
d
g
e
o
d_{geo}
dgeo的几何特征向量,目标物体所在位置图块尺寸为
H
×
W
H\times W
H×W,每个像素点都对应一个长度为
d
r
g
b
d_{rgb}
drgb的颜色特征向量。
接下来是考虑如何融合颜色特征和几何特征,本文采用的是一种逐像素稠密融合(Pixel-wise Dense Fusion)的方式,即将每个像素点对应的特征都融合起来,并根据每个融合特征都预测位姿。为了避免收到分割不准确和遮挡问题导致的背景和其他物体干扰,本文根据相机的内参矩阵,将点云中的每个点和图像的像素逐一对应起来,然后再将对应的几何特征向量和颜色特征向量级联起来得到融合特征,输入到一个MLP网络中生成一个固定尺寸的全局特征。将全局特征向量,与每个融合特征再级联起来,以提供一个全局的上下文信息。虽然每个目标物体包含
P
P
P个点,但是为了保证网络结构的统一,对于每个目标物体都只采样
N
N
N个点进行特征融合。
最后,将包含全局信息的融合特征输入到位姿估计网络中,输出每个点对应旋转矩阵
R
i
R_i
Ri、平移矩阵
t
i
t_i
ti和一个置信度
c
i
c_i
ci,置信度采用一种自监督的训练方式,置信度的取值将决定最终采用那个点的预测结果作为最终位姿。网络的训练过程如下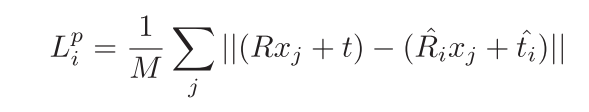
其中
x
j
x_j
xj表示从目标物体3D模型中采样得到的第
j
j
j个点,共采样
M
M
M个点,
p
=
[
R
∣
t
]
p=[R|t]
p=[R∣t]表示真实位姿,
p
^
i
=
[
R
i
^
∣
t
i
^
]
\hat{p}_i=[\hat{R_i}|\hat{t_i}]
p^i=[Ri^∣ti^]表示第
i
i
i个特征点对应的预测位姿。与PoseCNN一样,为了避免对称物体的影响,损失函数改进为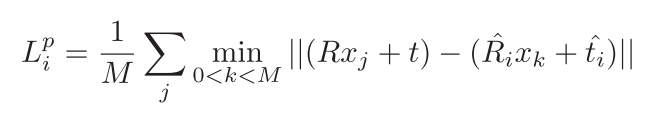
上式只是计算了一个点对应的损失函数,分别计算一个物体中
N
N
N个点对应的损失函数再求平均值得到目标物体对应的损失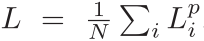
但正如上文所说,本文还希望网络学习如何平衡各个点预测结果之间的置信度,因此将每个点的预测损失都乘以对应的置信度,并增加了一个置信度正则化项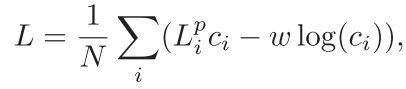
置信度越低将会使对应的位姿估计损失变低,但置信度正则化项对应的损失会增大,反之亦然。最终目标是让位姿估计损失
L
i
p
L_i^p
Lip小的点(即正确估计的点)其对应的置信度
c
i
c_i
ci更大,则对应的正则化损失项会更小,整个损失函数变小。最后,选择置信度最大的点对应的预测结果作为初始估计的位姿。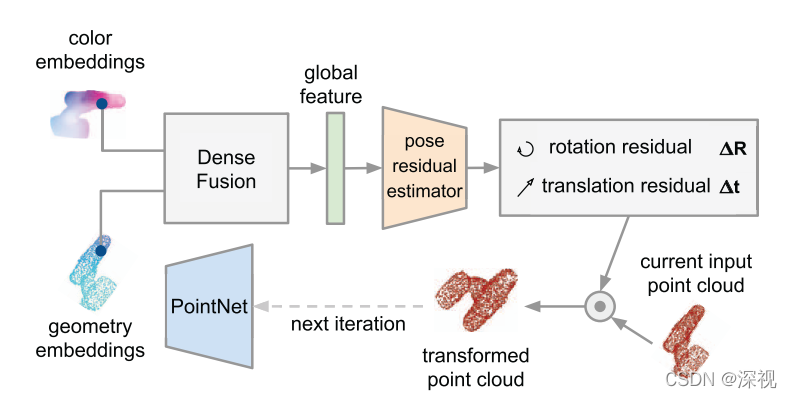
得到初始估计位姿后,作者又设计了一种迭代的优化算法,如上图所示。与使用ICP或利用渲染模型进行优化的方法不同,本文提出一种新的基于网络的迭代优化模块用于改善位姿估计结果。首先,根据初始位姿估计结果对目标物体的点云进行位姿变换,则变换后的点云包含了初始位姿估计的信息。将变换后的点云再输入到PointNet中提取对应的几何信息,并与之前提取的颜色特征信息(在位姿初步估计过程中提取的)融合起来得到一组新的全局特征。利用一个位姿残差估计网络根据输入的全局特征输出每个点对应的残差位姿
Δ
p
\Delta p
Δp。再根据残差
p
p
p对当前的点云再次进行位姿变换,并重复上述的估计过程,经过
K
K
K次迭代后得到最终的位姿估计结果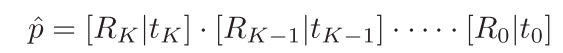
在YCB-Video数据集上位姿估计结果如下
创新点
- 提出一种稠密的位姿预测方法,根据每个点的特征结合全局特征预测位姿
- 根据预测置信度来选择位姿预测结果,并采用自监督的方式对置信度的预测结果进行训练
- 设计了一种基于网络的位姿迭代优化方法
算法评价
本文基于RGB-D图像信息直接对物体位姿进行预测,基本上还是延续了利用神经网络强大的特征映射能力进行位姿回归的思路。其特色还是很鲜明的包括稠密预测、置信度的设置和新的位姿迭代优化算法。但这类方法仍存在一定的局限问题就是泛化能力有限,只能对见过的训练过的目标进行准确预测,而对于未见过的全新目标,其预测结果就难以保证精度了。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论