

0. 基础配置
0.1. 设置随机种子
def set_seeds(seed, cuda): """ Set Numpy and PyTorch seeds. """ np.random.seed(seed) torch.manual_seed(seed) if cuda: torch.cuda.manual_seed_all(seed) print ("==> Set NumPy and PyTorch seeds.")
0.2. 张量处理与转化
tensor.type() # Data typetensor.size() # Shape of the tensor. It is a subclass of Python tupletensor.dim() # Number of dimensions.
# Type convertions.tensor = tensor.cuda()tensor = tensor.cpu()tensor = tensor.float()tensor = tensor.long()
#tensor 与python数据类型转化#Tensor ----> 单个Python数据,使用data.item(),data为Tensor变量且只能为包含单个数据#Tensor ----> Python list,使用data.tolist(),data为Tensor变量,返回shape相同的可嵌套的list
#CPU&GPU 位置#CPU张量 ----> GPU张量,使用data.cuda()#GPU张量 ----> CPU张量,使用data.cpu()
#tensor 与np.ndarrayndarray = tensor.cpu().numpy()ndarray = tensor.numpy()tensor.cpu().detach().numpy().tolist()[0]# np.ndarray -> torch.Tensor.tensor = torch.from_numpy(ndarray).float()tensor = torch.from_numpy(ndarray.copy()).float() # If ndarray has negative stride# torch.Tensor -> PIL.Image.image = PIL.Image.fromarray(torch.clamp(tensor * 255, min=0, max=255 ).byte().permute(1, 2, 0).cpu().numpy())image = torchvision.transforms.functional.to_pil_image(tensor) # Equivalently way# PIL.Image -> torch.Tensor.tensor = torch.from_numpy(np.asarray(PIL.Image.open(path)) ).permute(2, 0, 1).float() / 255tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # Equivalently way# np.ndarray -> PIL.Image.image = PIL.Image.fromarray(ndarray.astypde(np.uint8))# PIL.Image -> np.ndarray.ndarray = np.asarray(PIL.Image.open(path))
#复制张量# Operation | New/Shared memory | Still in computation graph |tensor.clone() # | New | Yes |tensor.detach() # | Shared | No |tensor.detach.clone()() # | New | No |#reshape 操作tensor = torch.reshape(tensor, shape)# Expand tensor of shape 64*512 to shape 64*512*7*7.torch.reshape(tensor, (64, 512, 1, 1)).expand(64, 512, 7, 7)
#向量拼接 注意torch.cat和torch.stack的区别在于torch.cat沿着给定的维度拼接,而torch.stack会新增一维。例如当参数是3个10×5的张量,torch.cat的结果是30×5的张量,而torch.stack的结果是3×10×5的张量。tensor = torch.cat(list_of_tensors, dim=0)tensor = torch.stack(list_of_tensors, dim=0)
#得到0/非0 元素torch.nonzero(tensor) # Index of non-zero elementstorch.nonzero(tensor == 0) # Index of zero elementstorch.nonzero(tensor).size(0) # Number of non-zero elementstorch.nonzero(tensor == 0).size(0) # Number of zero elements
#向量乘法# Matrix multiplication: (m*n) * (n*p) -> (m*p).result = torch.mm(tensor1, tensor2)# Batch matrix multiplication: (b*m*n) * (b*n*p) -> (b*m*p).result = torch.bmm(tensor1, tensor2)# Element-wise multiplication.result = tensor1 * tensor2
#计算两组数据之间的两两欧式距离# X1 is of shape m*d.X1 = torch.unsqueeze(X1, dim=1).expand(m, n, d)# X2 is of shape n*d.X2 = torch.unsqueeze(X2, dim=0).expand(m, n, d)# dist is of shape m*n, where dist[i][j] = sqrt(|X1[i, :] - X[j, :]|^2)dist = torch.sqrt(torch.sum((X1 - X2) ** 2, dim=2))
#卷积核conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True)
0.3. pytorch 版本
torch.__version__ # PyTorch versiontorch.version.cuda # Corresponding CUDA versiontorch.backends.cudnn.version() # Corresponding cuDNN versiontorch.cuda.get_device_name(0) # GPU type
0.4. GPU指定
torch.cuda.is_available()os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
1. 数据加载分割
1.0. Transform 变化

其中ToTensor操作会将PIL.Image或形状为H×W×D,数值范围为[0, 255]的np.ndarray转换为形状为D×H×W,数值范围为[0.0, 1.0]的torch.Tensor。 Normalize 需要注意数据的维度,否则容易报错。
train_transform = torchvision.transforms.Compose([ torchvision.transforms.RandomResizedCrop(size=224, scale=(0.08, 1.0)), torchvision.transforms.RandomHorizontalFlip(), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)), ]) val_transform = torchvision.transforms.Compose([ torchvision.transforms.Resize(256), torchvision.transforms.CenterCrop(224), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),])
1.1. 自定义dataset类
class CharDataset(Dataset): def __init__(self, csv_file, root_dir, transform = None): # args: path to csv file with keypoint data, directory with images, transform to be applied self.key_pts_frame = pd.read_csv(csv_file) self.root_dir = root_dir self.transform = transform def __len__(self): # return size of dataset return len(self.key_pts_frame.shape) def __getitem__(self, idx): image_name = os.path.join(self.root_dir, self.key_pts_frame.iloc[idx, 0]) image = mpimg.imread(image_name) # removing alpha color channel if present if image.shape[2] == 4: image = image[:, :, 0:3] key_pts = self.key_pts_frame.iloc[idx, 1:].values() key_pts = key_pts.astype('float').reshape(-1, 2) sample = {'image': image, 'keypoints': key_pts} # apply transform if self.transform: sample = self.transform(sample) return sampleif __name__ == "__main__": chardata=CharDataset("D:\\Model\\CharPointDetection\\data\\test\\") print(len(chardata)) #1198 print(chardata[0].get("image").shape) #(96, 96) 最大值1, 最小值0
- dataset
import jsonimport matplotlib.pyplot as pltimport numpy as npfrom torch.utils.data import Dataset,DataLoaderimport matplotlib.pyplot as pltfrom torchvision import transforms, utilsimport cv2from util.imageUtil import *from util.config import *class DatasetCustom(Dataset): def __init__(self, rootcsv, imgroot,train=True, transform = None,ratio=0.7): self.train = train self.transform = transform self.allItem=self.readcsv(rootcsv) self.imgroot=imgroot #todo 添加打乱操作 训练和测试数据集进行分割处理 if self.train : self.labelItem=self.allItem[:int(len(self.allItem)*ratio)] else: self.labelItem=self.allItem[int(len(self.allItem)*ratio)+1:]
def readcsv(self,filename): ''' 读取CSV中clothdata数据 ''' with open(filename,encoding = 'utf-8') as f: data = np.loadtxt(f,str,delimiter = ",", skiprows = 1) data=data[::2,:] #或取csv 文件数据 return data
def __getitem__(self, index): index=index%self.__len__() img_name = self.labelItem[index][0].split('_') # 或取图片对于路径 imgpath="{}/camera{}_{}_{}_{}.jpg".format(self.imgroot,img_name[0],img_name[1],0-int(img_name[1]),img_name[2]) ratioW,ratioH,img=imageloadCV(imgpath,RESIZE) #图片大小进行了resize处理,对于x,y也进行缩放处理 keypoints = self.labelCoordinateHandle(self.labelItem[index][10:],ratioW,ratioH) if self.transform is not None: img = self.transform(img) # return img, keypoints 对于这种枚举方式:for step ,(b_x,b_y) in enumerate(train_loader): # return { # 'image': torch.tensor(img, dtype=torch.float), # 'keypoints': torch.tensor(keypoints, dtype=torch.float), # } # 对应代码枚举方式 # for i, data in tqdm(enumerate(dataloader), total=num_batches): # image, keypoints = data['image'].to(DEVICE), data['keypoints'].to(DEVICE) return { 'image': img, 'keypoints': keypoints, }
def labelCoordinateHandle(self,data,ratioW,ratioH): ''' 对图片的长宽进行了相应的缩放处理 ''' data=[float(i) for i in data] data[0]=data[0]*ratioW data[1]=data[1]*ratioH data[3]=data[3]*ratioW data[4]=data[4]*ratioH return np.array(data, dtype='float32')
def __len__(self): return len(self.labelItem)
if __name__ == '__main__': train_dataset =DatasetCustom(rootcsv=ROOT_CSV,imgroot=IMG_ROOT,train=True,transform=transforms.ToTensor(),ratio=0.7) test_dataset = DatasetCustom(rootcsv=ROOT_CSV,imgroot=IMG_ROOT,train=False,transform=transforms.ToTensor(),ratio=0.7) #single record data= train_dataset.__getitem__(1) #toTensor中进行了转化 img = torch.from_numpy(pic.transpose((2, 0, 1))) img, label = data['image'], data['keypoints'] img = np.transpose(img.numpy(),(1,2,0)) plt.imshow(img) plt.show() print("label",label)
#DataLoader查看 train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=6, shuffle=False) def imshow(img): npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) print('num_of_trainData:', len(train_loader)) print('num_of_testData:', len(test_loader)) #显示要给batch 中图片内容 for step ,(b_x,b_y) in enumerate(train_loader): #print("step:",step) if step < 1: imgs = utils.make_grid(b_x) print(imgs.shape) imgs = np.transpose(imgs,(1,2,0)) print(imgs.shape) plt.imshow(imgs) plt.show() break
1.2. 数据分割获取
Dataset = CharDataset(rootdir) # 自定义的dataset 类l=Dataset.__len__()test_percent=5torch.manual_seed(1)indices = torch.randperm(len(Dataset)).tolist()dataset = torch.utils.data.Subset(Dataset, indices[:-int(np.ceil(l*test_percent/100))])dataset_test = torch.utils.data.Subset(Dataset, indices[int(-np.ceil(l*test_percent/100)):])# define training and validation data loadersimport utilsdata_loader = torch.utils.data.DataLoader( dataset, batch_size=2, shuffle=True, collate_fn=utils.collate_fn)data_loader_test = torch.utils.data.DataLoader( dataset_test, batch_size=(1), shuffle=False, collate_fn=utils.collate_fn)for batch_i, data in enumerate(data_loader): images = data['image'] key_pts = data['keypoints']
1.3. 视频图像数据
import cv2video = cv2.VideoCapture(mp4_path)height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))fps = int(video.get(cv2.CAP_PROP_FPS))video.release()
1.4. ImageFolder等类
import torchvision.datasets as dsetdataset = dset.ImageFolder('./data/dogcat_2') #没有transform,先看看取得的原始图像数据print(dataset.classes) #根据分的文件夹的名字来确定的类别print(dataset.class_to_idx) #按顺序为这些类别定义索引为0,1...print(dataset.imgs) #返回从所有文件夹中得到的图片的路径以及其类别
1.5. OneHot 编码
# pytorch的标记默认从0开始tensor = torch.tensor([0, 2, 1, 3])N = tensor.size(0)num_classes = 4one_hot = torch.zeros(N, num_classes).long()one_hot.scatter_(dim=1, index=torch.unsqueeze(tensor, dim=1), src=torch.ones(N, num_classes).long())
2. PretrainModel 使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kluqRQZZ-1626183044249)(…/…/pictures/image-20210516230215346.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-saf1SWop-1626183044250)(…/…/pictures/image-20210516230252202.png)]
2.1. 查看模型结构
resnet.fc = torch.nn.Linear(resnet.fc.in_features, 100)print(resnet) #将会输出网络每一层结构# 或者采用torchviz模块,对网络结构进行可视化, 将会生成一个pdf 网络结构图from torchviz import make_dotx = torch.randn(10, 3, 224, 224).requires_grad_(True)y = resnet(x)vis_graph = make_dot(y, params=dict(list(resnet.named_parameters()) + [('x', x)]))vise_graph.view()
2.2. 模型初始化
适当的权值初始化可以加速模型的训练和模型的收敛,而错误的权值初始化会导致梯度消失/爆炸,从而无法完成网络的训练,因此需要控制网络输出值的尺度范围。torch.nn.init中提供了常用的初始化方法函数,1. Xavier,kaiming系列;2. 其他方法分布
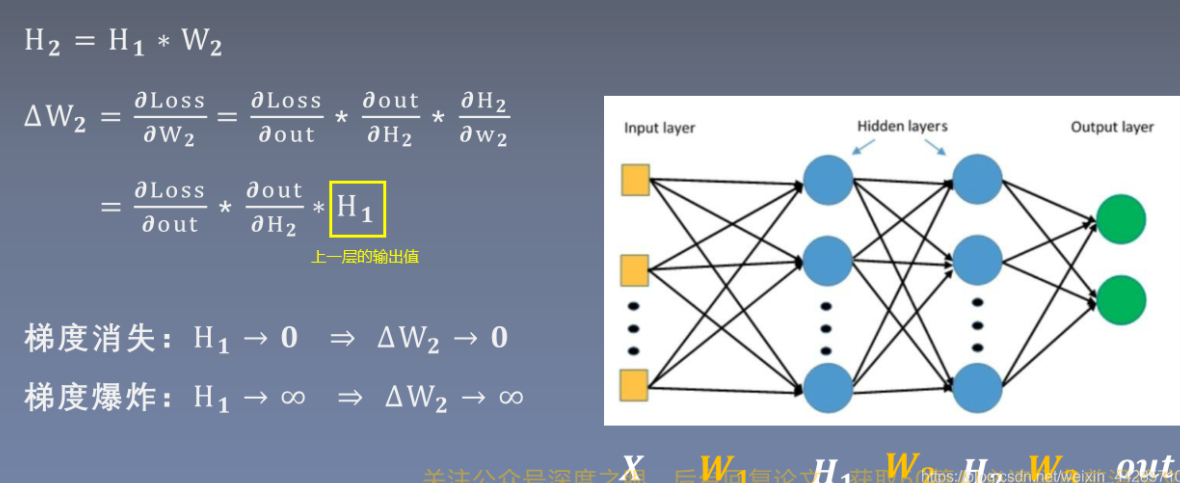
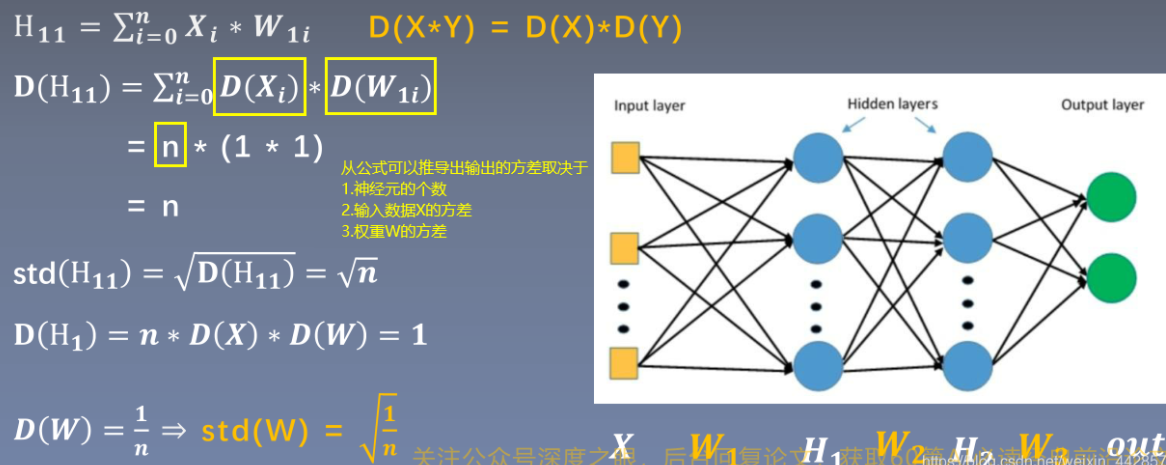
从上图中的公式可以看出,*每传播一层,输出值数据的方差就会扩大n* *倍*,要想控制输出H的尺度范围,只需要控制H的方差为1,则无论经过多少层都可以维持在初始输入X的方差附近,因此*权重w需要初始化方差为1/n*(n为神经元的个数)

.1. Xavier 均匀分布

import osimport torchimport randomimport numpy as npimport torch.nn as nn def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 class MLP(nn.Module): def __init__(self, neural_num, layers): super(MLP, self).__init__() self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)]) self.neural_num = neural_num def forward(self, x): for (i, linear) in enumerate(self.linears): x = linear(x) x = torch.tanh(x) print("layer:{}, std:{}".format(i, x.std())) if torch.isnan(x.std()): print("output is nan in {} layers".format(i)) break return x def initialize(self): for m in self.modules(): if isinstance(m, nn.Linear): #xavier手动计算 a = np.sqrt(6 / (self.neural_num + self.neural_num)) tanh_gain = nn.init.calculate_gain('tanh') #计算增益 a *= tanh_gain nn.init.uniform_(m.weight.data, -a, a) #调用pytorch实现xavier初始化,适用于饱和激活函数 # tanh_gain = nn.init.calculate_gain('tanh') # nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain) # flag = 0flag = 1 if flag: layer_nums = 100 neural_nums = 256 batch_size = 16 net = MLP(neural_nums, layer_nums) net.initialize() inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1 output = net(inputs) print(output)
torch.nn.init.xavier_uniform_(tensor, gain=1)
xavier初始化方法中服从均匀分布U(−a,a) ,分布的参数a = gain * sqrt(6/fan_in+fan_out),
这里有一个gain,增益的大小是依据激活函数类型来设定
eg:nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
.2. Xavier正态分布
torch.nn.init.xavier_normal_(tensor, gain=1)
xavier初始化方法中服从正态分布,
mean=0,std = gain * sqrt(2/fan_in + fan_out)
.3. kaiming均匀分布
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
此为均匀分布,U~(-bound, bound), bound = sqrt(6/(1+a^2)*fan_in)
其中,a为激活函数的负半轴的斜率,relu是0
mode- 可选为fan_in 或 fan_out, fan_in使正向传播时,方差一致; fan_out使反向传播时,方差一致
nonlinearity- 可选 relu 和 leaky_relu ,默认值为 。 leaky_relu
nn.init.kaiming_uniform_(w, mode=‘fan_in’, nonlinearity=‘relu’)
import osimport torchimport randomimport numpy as npimport torch.nn as nn def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 class MLP(nn.Module): def __init__(self, neural_num, layers): super(MLP, self).__init__() self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)]) self.neural_num = neural_num def forward(self, x): for (i, linear) in enumerate(self.linears): x = linear(x) x = torch.relu(x) print("layer:{}, std:{}".format(i, x.std())) if torch.isnan(x.std()): print("output is nan in {} layers".format(i)) break return x def initialize(self): for m in self.modules(): if isinstance(m, nn.Linear): #kaiming初始化手动 nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num)) #kaiming初始化 # nn.init.kaiming_normal_(m.weight.data) # flag = 0flag = 1 if flag: layer_nums = 100 neural_nums = 256 batch_size = 16 net = MLP(neural_nums, layer_nums) net.initialize() inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1 output = net(inputs) print(output)
.4. kaiming 正态分布
torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
此为0均值的正态分布,N~ (0,std),其中std = sqrt(2/(1+a^2)*fan_in)
其中,a为激活函数的负半轴的斜率,relu是0
mode- 可选为fan_in 或 fan_out, fan_in使正向传播时,方差一致;fan_out使反向传播时,方差一致
nonlinearity- 可选 relu 和 leaky_relu ,默认值为 。 leaky_relu
nn.init.kaiming_normal_(w, mode=‘fan_out’, nonlinearity=‘relu’)
.5. 均匀初始化分布
torch.nn.init.uniform_(tensor, a=0, b=1)
使值服从均匀分布U(a,b)
.6. 正态初始化分布
torch.nn.init.normal_(tensor, mean=0, std=1)
使值服从正态分布N(mean, std),默认值为0,1
.7. 常数初始化
torch.nn.init.constant_(tensor, val)
使值为常数val nn.init.constant_(w, 0.3)
.8. 单位矩阵初始化
torch.nn.init.eye_(tensor)
将二维tensor初始化为单位矩阵(the identity matrix)
.9. 正交初始化
torch.nn.init.orthogonal_(tensor, gain=1)
使得tensor是正交的,论文:Exact solutions to the nonlinear dynamics of learning in deep linear neural networks” - Saxe, A. et al. (2013)
.10. 稀疏初始化
torch.nn.init.sparse_(tensor, sparsity, std=0.01)
从正态分布N~(0. std)中进行稀疏化,使每一个column有一部分为0
sparsity- 每一个column稀疏的比例,即为0的比例
nn.init.sparse_(w, sparsity=0.1)
注意 model.modules()和 model.children()的区别:model.modules()会迭代地遍历模型的所有子层,而**model.children()**只会遍历模型下的一层。
- 对网络中某一层进行初始化
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)init.xavier_uniform(self.conv1.weight)init.constant(self.conv1.bias, 0.1)
- 对网络整体进行初始化
def weights_init(m): classname=m.__class__.__name__ if classname.find('Conv') != -1: xavier(m.weight.data) xavier(m.bias.data)net = Net()#构建网络net.apply(weights_init) #apply函数会递归地搜索网络内的所有module并把参数表示的函数应用到所有的module上。 #对所有的Conv层都初始化权重.
- 权重初始化
# Common practise for initialization.for layer in model.modules(): if isinstance(layer, torch.nn.Conv2d): torch.nn.init.kaiming_normal_(layer.weight, mode='fan_out', nonlinearity='relu') if layer.bias is not None: torch.nn.init.constant_(layer.bias, val=0.0) elif isinstance(layer, torch.nn.BatchNorm2d): torch.nn.init.constant_(layer.weight, val=1.0) torch.nn.init.constant_(layer.bias, val=0.0) elif isinstance(layer, torch.nn.Linear): torch.nn.init.xavier_normal_(layer.weight) if layer.bias is not None: torch.nn.init.constant_(layer.bias, val=0.0)# Initialization with given tensor.layer.weight = torch.nn.Parameter(tensor)
- 对指定层进行Finetune
count = 0para_optim = []for k in model.children(): count += 1 # 6 should be changed properly if count > 6: for param in k.parameters(): para_optim.append(param) else: for param in k.parameters(): param.requires_grad = Falseoptimizer = optim.RMSprop(para_optim, lr)
- 对固定部分参数训练
# 只有True的才训练optimizer.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) #前面的参数就是False,而后面的不变 for p in self.parameters(): p.requires_grad=False self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)
- 优化
optimizer = optim.Adam([ {'params': [param for name, param in net.named_parameters() if name[-4:] == 'bias'], 'lr': 2 * args['lr']}, {'params': [param for name, param in net.named_parameters() if name[-4:] != 'bias'], 'lr': args['lr'], 'weight_decay': args['weight_decay']} ], betas=(args['momentum'], 0.999))
- 加载部分权重
# 获得模型的键值keys=[]for k,v in desnet.state_dict().items(): if v.shape: keys.append(k) print(k,v.shape) # 从预训练文件中加载权重state={}pretrained_dict = torch.load('/home/lulu/pytorch/Paper_Code/weights/densenet121-a639ec97.pth')for i,(k,v) in enumerate(pretrained_dict.items()): if 'classifier' not in k: state[keys[i]] = v# 保存权重torch.save(state,'/home/lulu/pytorch/Paper_Code/weights/densenet121.pth')
2.3. ImageNet预训练模型某层卷积特征
# VGG-16 relu5-3 feature.model = torchvision.models.vgg16(pretrained=True).features[:-1]# VGG-16 pool5 feature.model = torchvision.models.vgg16(pretrained=True).features# VGG-16 fc7 feature.model = torchvision.models.vgg16(pretrained=True)model.classifier = torch.nn.Sequential(*list(model.classifier.children())[:-3])# ResNet GAP feature.model = torchvision.models.resnet18(pretrained=True)model = torch.nn.Sequential(collections.OrderedDict( list(model.named_children())[:-1]))with torch.no_grad(): model.eval() conv_representation = model(image)
2.4. 提取ImageNet与训练模型多层卷积特征
class FeatureExtractor(torch.nn.Module): """Helper class to extract several convolution features from the given pre-trained model. Attributes: _model, torch.nn.Module. _layers_to_extract, list<str> or set<str> Example: >>> model = torchvision.models.resnet152(pretrained=True) >>> model = torch.nn.Sequential(collections.OrderedDict( list(model.named_children())[:-1])) >>> conv_representation = FeatureExtractor( pretrained_model=model, layers_to_extract={'layer1', 'layer2', 'layer3', 'layer4'})(image) """ def __init__(self, pretrained_model, layers_to_extract): torch.nn.Module.__init__(self) self._model = pretrained_model self._model.eval() self._layers_to_extract = set(layers_to_extract) def forward(self, x): with torch.no_grad(): conv_representation = [] for name, layer in self._model.named_children(): x = layer(x) if name in self._layers_to_extract: conv_representation.append(x) return conv_representation
2.5. 模型微调
#微调全连接层model = torchvision.models.resnet18(pretrained=True)for param in model.parameters(): param.requires_grad = Falsemodel.fc = nn.Linear(512, 100) # Replace the last fc layeroptimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)#以较大的学习率微调全连接层,较小的学习率微调卷积层model = torchvision.models.resnet18(pretrained=True)finetuned_parameters = list(map(id, model.fc.parameters()))conv_parameters = (p for p in model.parameters() if id(p) not in finetuned_parameters)parameters = [{'params': conv_parameters, 'lr': 1e-3}, {'params': model.fc.parameters()}]optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
- 学习率相关
#得到当前学习率lr = next(iter(optimizer.param_groups))['lr'] #multiple learning rates for different layers.all_lr = []for param_group in optimizer.param_groups: all_lr.append(param_group['lr']) #学习率衰减#Reduce learning rate when validation accuarcy plateau.scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=5, verbose=True)for t in range(0, 80): train(...); val(...) scheduler.step(val_acc)#Cosine annealing learning rate. scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=80)#Reduce learning rate by 10 at given epochs.scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 70], gamma=0.1)for t in range(0, 80): scheduler.step() train(...); val(...)#Learning rate warmup by 10 epochs.scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda t: t / 10)for t in range(0, 10): scheduler.step() train(...); val(...)
2.5.1. 学习率调整策略
a. 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和 余弦退火CosineAnnealing。
b. 自适应调整:自适应调整学习率 ReduceLROnPlateau。
c. 自定义调整:自定义调整学习率 LambdaLR。
- 针对不同的层
model = torchvision.models.resnet101(pretrained=True)large_lr_layers = list(map(id,model.fc.parameters()))small_lr_layers = filter(lambda p:id(p) not in large_lr_layers,model.parameters())optimizer = torch.optim.SGD([ {"params":large_lr_layers}, {"params":small_lr_layers,"lr":1e-4} ],lr = 1e-2,momenum=0.9)
- 等间隔调整学习率 StepLR
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
step_size(int)- 学习率下降间隔数,若为 30,则会在 30、 60、 90…个 step 时,将学习率调整为 lr*gamma。
gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
last_epoch(int)- 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值。
调整倍数为 gamma 倍,调整间隔为 step_size。间隔单位是step。需要注意的是, step 通常是指 epoch,不要弄成 iteration 了。
- 按需调整学习率 MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
milestones(list)- 一个 list,每一个元素代表何时调整学习率,list 元素必须是递增的。如 milestones=[30,80,120]
gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
按设定的间隔调整学习率。这个方法适合后期调试使用,观察 loss 曲线,为每个实验定制学习率调整时机。
- 指数衰减调整学习率 ExponentialLR
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
gamma- 学习率调整倍数的底,指数为 epoch,即 gamma**epoch
- 余弦退火调整学习率 CosineAnnealingLR
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
T_max(int)- 一次学习率周期的迭代次数,即T_max 个 epoch 之后重新设置学习率。
eta_min(float)- 最小学习率,即在一个周期中,学习率最小会下降到 eta_min,默认值为 0。
以余弦函数为周期,并在每个周期最大值时重新设置学习率。以初始学习率为最大学习率,以 2 ∗ T m a x 2*Tmax2∗Tmax 为周期,在一个周期内先下降,后上升。epochs = 60optimizer = optim.SGD(model.parameters(),lr = config.lr,momentum=0.9,weight_decay=1e-4) scheduler = lr_scheduler.CosineAnnealingLR(optimizer,T_max = (epochs // 9) + 1)for epoch in range(epochs): scheduler.step(epoch)
- 自适应调整学习率 ReduceLROnPlateau
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
mode(str)- 模式选择,有 min 和 max 两种模式, min 表示当指标不再降低(如监测loss),max 表示当指标不再升高(如监测 accuracy)。factor(float)- 学习率调整倍数(等同于其它方法的 gamma),即学习率更新为 lr = lr * factorpatience(int)- 忍受该指标多少个 step 不变化,当忍无可忍时,调整学习率。verbose(bool)- 是否打印学习率信息, print(‘Epoch {:5d}: reducing learning rate of group {} to {:.4e}.’.format(epoch, i, new_lr))threshold_mode(str)- 选择判断指标是否达最优的模式,有两种模式, rel 和 abs。当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best * ( 1 +threshold );当 threshold_mode == rel,并且 mode == min 时, dynamic_threshold = best * ( 1 -threshold );当 threshold_mode == abs,并且 mode== max 时, dynamic_threshold = best + threshold ;当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best - threshold;threshold(float)- 配合 threshold_mode 使用。cooldown(int)- “冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。min_lr(float or list)- 学习率下限,可为 float,或者 list,当有多个参数组时,可用 list 进行设置。eps(float)- 学习率衰减的最小值,当学习率变化小于 eps 时,则不调整学习率。optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)scheduler = ReduceLROnPlateau(optimizer, 'max',verbose=1,patience=3)for epoch in range(10): train(...) val_acc = validate(...) # 降低学习率需要在给出 val_acc 之后 scheduler.step(val_acc)
- 自定义调整学习率 LambdaLR
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QNKmXSPV-1626183044254)(…/…/…/picture/image-20210531084712294.png)]
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
- lr_lambda(function or list)- 一个
计算学习率调整倍数的函数,输入通常为 step,当有多个参数组时,设为 list。
- 手动设置
def adjust_learning_rate(optimizer, lr): for param_group in optimizer.param_groups: param_group['lr'] = lrfor epoch in range(60): lr = 30e-5 if epoch > 25: lr = 15e-5 if epoch > 30: lr = 7.5e-5 if epoch > 35: lr = 3e-5 if epoch > 40: lr = 1e-5 adjust_learning_rate(optimizer, lr)
2.6. keypointrcnn_resnet50_fpn 模型使用
import torchimport torchvisionimport torch.nn as nndef get_model(num_kpts,train_kptHead=False,train_fpn=True): is_available = torch.cuda.is_available() device =torch.device('cuda:0' if is_available else 'cpu') dtype = torch.cuda.FloatTensor if is_available else torch.FloatTensor model = torchvision.models.detection.keypointrcnn_resnet50_fpn(pretrained=True) for i,param in enumerate(model.parameters()): param.requires_grad = False if train_kptHead!=False: for i, param in enumerate(model.roi_heads.keypoint_head.parameters()): if i/2>=model.roi_heads.keypoint_head.__len__()/2-train_kptHead: param.requires_grad = True if train_fpn==True: for param in model.backbone.fpn.parameters(): param.requires_grad = True out = nn.ConvTranspose2d(512, num_kpts, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1)) model.roi_heads.keypoint_predictor.kps_score_lowres = out return model, device, dtype#model, device, dtype=get_model(2)
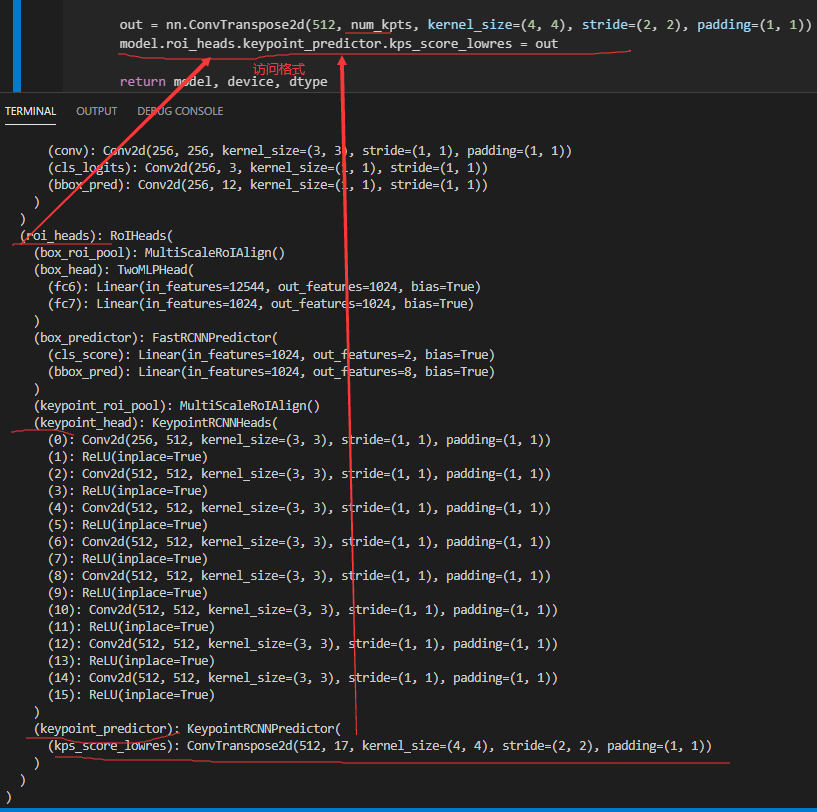
2.7. 构建模型
- Sequential:顺序性,各网络层之间严格按照顺序执行,常用语block构建
- ModuleList:迭代性,常用于大量重复网络构建,通过for循环实现重复构建
- ModuleDict:索引性,常用于可选择的网络层
.1. nn.Sequential
# ============================ Sequentialclass LeNetSequential(nn.Module): def __init__(self, classes): super(LeNetSequential, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 6, 5), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, 5), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2),) self.classifier = nn.Sequential( nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, classes),) def forward(self, x): x = self.features(x) x = x.view(x.size()[0], -1) x = self.classifier(x) return x
.2. nn.ModuleList
功能:像python的list一样包装多个网络层,以迭代的方式调用网络层
- append():在modulelist后面添加网络层
- extend():拼接两个modulelist
- insert():在modulelist中指定位置插入网络层
class ModuleList(nn.Module): def __init__(self): super(ModuleList, self).__init__() self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)]) def forward(self, x): for i, linear in enumerate(self.linears): x = linear(x) return xnet = ModuleList()print(net)fake_data = torch.ones((10, 10))output = net(fake_data)print(output)
.3. nn.ModuleDict
功能:像python的dict一样包装多个网络层(每一个给一个key,可通过key索引网络层)
clear():清空moduleDict
items():返回可迭代的键值对(key-value pairs)
keys():返回字典的key
values():返回字典的value
pop():返回一对键值,并从字典中删除# ============================ ModuleDictclass ModuleDict(nn.Module): def __init__(self): super(ModuleDict, self).__init__() self.choices = nn.ModuleDict({ 'conv': nn.Conv2d(10, 10, 3), 'pool': nn.MaxPool2d(3) }) self.activations = nn.ModuleDict({ 'relu': nn.ReLU(), 'prelu': nn.PReLU() }) def forward(self, x, choice, act): x = self.choices[choice](x) x = self.activations[act](x) return xnet = ModuleDict()fake_img = torch.randn((4, 10, 32, 32))output = net(fake_img, 'conv', 'relu')#prelu输出结果有负值,改为relu后输出没有负数,可以检查是不是按照我们的想法运行的print(output)
3. 训练基本框架
for t in epoch(80): for images, labels in tqdm.tqdm(train_loader, desc='Epoch %3d' % (t + 1)): images, labels = images.cuda(), labels.cuda() scores = model(images) loss = loss_function(scores, labels) optimizer.zero_grad() loss.backward() optimizer.step()#计算 softmax 输出准确率score = model(images)prediction = torch.argmax(score, dim=1) # 按行 返回每行最大值在的该行索引, 如果没有dim 则按照一维数组计算num_correct = torch.sum(prediction == labels).item()accuruacy = num_correct / labels.size(0)
- Label One-hot编码时
for images, labels in train_loader: images, labels = images.cuda(), labels.cuda() N = labels.size(0) # C is the number of classes. smoothed_labels = torch.full(size=(N, C), fill_value=0.1 / (C - 1)).cuda() smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9) score = model(images) log_prob = torch.nn.functional.log_softmax(score, dim=1) loss = -torch.sum(log_prob * smoothed_labels) / N optimizer.zero_grad() loss.backward() optimizer.step()
4. 模型保存与加载
注意,torch.load函数要确定存储的位置:map_location=‘cpu’
torch.sava有俩种方式:
保存权重和模型,但是文件结果不能改变,否则报错;
保存权重,加载时,先初始化类,然后加载权重信息。
# 保存整个网络torch.save(net, PATH) # 保存网络中的参数, 速度快,占空间少torch.save(net.state_dict(),PATH)#--------------------------------------------------#针对上面一般的保存方法,加载的方法分别是:model_dict=torch.load(PATH)model_dict=model.load_state_dict(torch.load(PATH))mlp_mixer.load_state_dict(torch.load(Config.MLPMIXER_WEIGHT,map_location='cpu'))#save modeldef save_models(tempmodel,save_path): torch.save("./model/"+tempmodel.state_dict(), save_path) print("Checkpoint saved")# load modelmodel=Net() #模型的结构model.load_state_dict(torch.load(Path("./model/95.model")))model.eval() #运行推理之前,必须先调用以将退出和批处理规范化层设置为评估模式。不这样做将产生不一致的推断结果。#断点保存# Save checkpoint.is_best = current_acc > best_accbest_acc = max(best_acc, current_acc)checkpoint = { 'best_acc': best_acc, 'epoch': t + 1, 'model': model.state_dict(), 'optimizer': optimizer.state_dict(),}model_path = os.path.join('model', 'checkpoint.pth.tar')torch.save(checkpoint, model_path)if is_best: shutil.copy('checkpoint.pth.tar', model_path) # Load checkpoint.if resume: model_path = os.path.join('model', 'checkpoint.pth.tar') assert os.path.isfile(model_path) checkpoint = torch.load(model_path) best_acc = checkpoint['best_acc'] start_epoch = checkpoint['epoch'] model.load_state_dict(checkpoint['model']) optimizer.load_state_dict(checkpoint['optimizer']) print('Load checkpoint at epoch %d.' % start_epoch)
5. 计算准确率,查准率,查全率
# data['label'] and data['prediction'] are groundtruth label and prediction # for each image, respectively.accuracy = np.mean(data['label'] == data['prediction']) * 100 # Compute recision and recall for each class.for c in range(len(num_classes)): tp = np.dot((data['label'] == c).astype(int), (data['prediction'] == c).astype(int)) tp_fp = np.sum(data['prediction'] == c) tp_fn = np.sum(data['label'] == c) precision = tp / tp_fp * 100 recall = tp / tp_fn * 100 # data['label'] and data['prediction'] are groundtruth label and prediction # for each image, respectively.accuracy = np.mean(data['label'] == data['prediction']) * 100 # Compute recision and recall for each class.for c in range(len(num_classes)): tp = np.dot((data['label'] == c).astype(int), (data['prediction'] == c).astype(int)) tp_fp = np.sum(data['prediction'] == c) tp_fn = np.sum(data['label'] == c) precision = tp / tp_fp * 100 recall = tp / tp_fn * 100
建议有参数的层和汇合(pooling)层使用torch.nn模块定义,激活函数直接使用torch.nn.functional。torch.nn模块和torch.nn.functional的区别在于,torch.nn模块在计算时底层调用了torch.nn.functional,但torch.nn模块包括该层参数,还可以应对训练和测试两种网络状态。model(x)前用model.train()和model.eval()切换网络状态。loss.backward()前用optimizer.zero_grad()清除累积梯度。optimizer.zero_grad()和model.zero_grad()效果一样。
6. 可视化部分
有 Facebook 自己开发的 Visdom 和 Tensorboard 两个选择。
https://github.com/facebookresearch/visdom
https://github.com/lanpa/tensorboardX
# Example using Visdom.vis = visdom.Visdom(env='Learning curve', use_incoming_socket=False)assert self._visdom.check_connection()self._visdom.close()options = collections.namedtuple('Options', ['loss', 'acc', 'lr'])( loss={'xlabel': 'Epoch', 'ylabel': 'Loss', 'showlegend': True}, acc={'xlabel': 'Epoch', 'ylabel': 'Accuracy', 'showlegend': True}, lr={'xlabel': 'Epoch', 'ylabel': 'Learning rate', 'showlegend': True})for t in epoch(80): tran(...) val(...) vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([train_loss]), name='train', win='Loss', update='append', opts=options.loss) vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([val_loss]), name='val', win='Loss', update='append', opts=options.loss) vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([train_acc]), name='train', win='Accuracy', update='append', opts=options.acc) vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([val_acc]), name='val', win='Accuracy', update='append', opts=options.acc) vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([lr]), win='Learning rate', update='append', opts=options.lr)
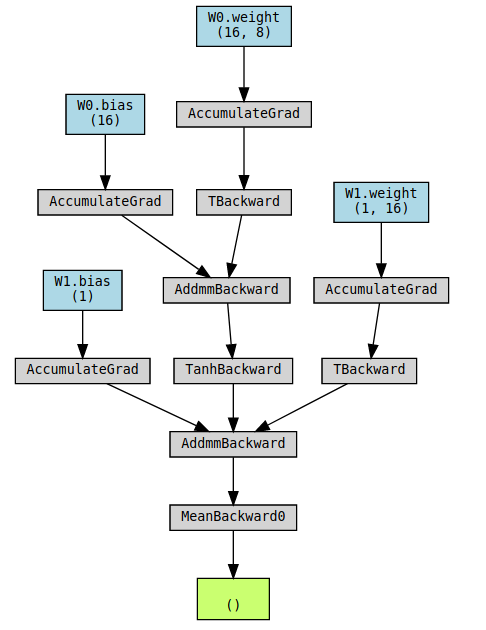
- pytorch graphviz
pip install torchviz
model = nn.Sequential()model.add_module('W0', nn.Linear(8, 16))model.add_module('tanh', nn.Tanh())model.add_module('W1', nn.Linear(16, 1))x = torch.randn(1, 8)y = model(x)make_dot(y.mean(), params=dict(model.named_parameters()), show_attrs=True, show_saved=True)



评论(0)
您还未登录,请登录后发表或查看评论