
前言
本篇博客为博主毕设的一部分,此部分主要解决海上船舶目标实时分类检测。在Tensorflow的环境下,采用YOLOv3(keras)算法,最终mAP可达到95.66%,下面详细的介绍了我的训练过程。
Seaship数据集:下载
下面为部分检测结果的截图:
第二部分:【目标检测】基于yolo3和sort的多目标检测与跟踪
一、准备环节
计算机环境:Win10 + Python3.6 + cuda9.0
主要依赖:
tensorflow-gpu 1.12.0
keras-gpu 2.2.4
opencv 4.2.0
pillow
numpy
matplotlib
深度学习框架
如果是第一次使用深度学习进行目标检测,需要安装深度学习框架,本项目使用的是Tensorflow深度学习框架。
【TensorFlow】Window10搭建GPU环境(CUDA、cuDNN)
必选部分
源码:https://github.com/qqwweee/keras-yolo3
权重文件:yolo.h5(被墙,可采用下面方法)
在YOLO官网下载YOLO的权重文件。通过以下命令将.weights文件转换为.h5模型。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
- 1
可选部分
mAP计算:【目标检测】kera-yolo3模型计算mAP
mAP源码:https://github.com/Cartucho/mAP
修改mAP源码,针对keras-yolov3的检测结果计算mAP。
数据集
Seaship数据集:下载
数据集介绍:SeaShips A Large-Scale Precisely Annotated Dataset for Ship Detection
二、代码结构分析
在训练时需要对其中的一些文件进行修改,同时也需要增添一些文件和文件夹。左侧为原工程,右侧为修改后的工程。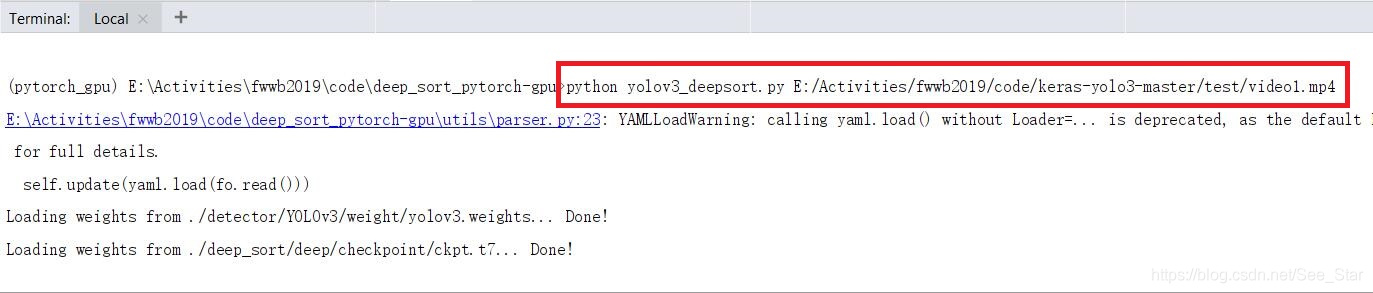
需要修改/增添部分:
| 文件 / 文件夹 | 作用 |
|---|---|
| dataset文件夹 | 存放数据集 |
| mAP文件夹 | 计算模型的mAP |
| model文件夹 | 存放训练出的模型 |
| model_data文件夹 | 训练模型所需的文件 |
| result文件夹 | 存放测试图片检测结果 |
| voc_annotation.py | 将数据集文本生产符合格式要求的训练文本 |
| test.txt | 通过voc_annotation.py生成的测试集文本 |
| train.txt | 通过voc_annotation.py生成的训练集文本 |
| val.txt | 通过voc_annotation.py生成的验证集文本 |
| train.py | 训练模型 |
| yolo.py | 测试模型,生成检测结果(保留,不修改) |
| test_yolo.py | yolo.py的复制文件,复制之后进行修改 |
| yolov3.cfg | yolo模型的配置文件 |
无需修改部分(主要部分,次要部分不再介绍):
| 文件 / 文件夹 | 作用 |
|---|---|
| yolo3文件夹 | 存放yolo相关算法的文件夹 |
| convert | 将.weight模型转换成.h5模型 |
| yolo_video | 用于检测视频文件的库 |
| kmeans | kmean聚类用于生成Anchors |
三、制作数据集
3.1 LabelImg 标记图片
标记图片就是对图片中的待识别目标进行标记,如果识别的目标时猫、狗,那就用方块标记出猫或狗,它们的标签分别为cat、dog。标记完成后,生成与原文件名相同的.xml文件。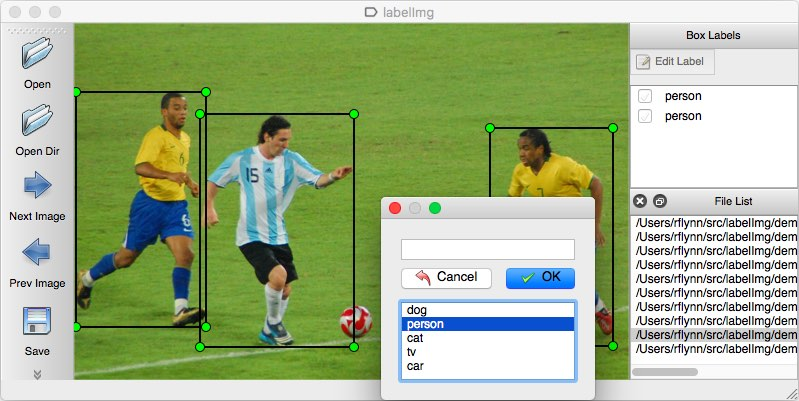
标记图片软件LabelImg,可参考:图像标注工具labelImg安装教程及使用方法。
3.2 VOC 数据集格式介绍
深度学习所使用的数据集格式大部分采用VOC格式。所以我们也要将自己所标记的图片转变到VOC格式。
可查看此博客了解VOC数据集的组成。
3.3 转化成VOC数据集
标记好所有图片后,所有的jpg和xml均在一个目录下。我们新建一个文件夹dataset,在dataset目录下新建JPEGImages、Annotations和ImageSets三个文件夹。
将所有jpg文件放入JPEGImages中;
将所有xml文件放入Annotations中;
在ImageSets文件夹内新建Main备用。
3.4 生成ImageSets
使用代码make_main_txt.py在ImgeSets/Main目录下生成train.txt, trainval.txt, val.txt, test.txt。
该代码存放的目录如下图,make_main_txt.py与ImageSets同级。
代码:make_main_txt.py
# -_- coding:utf-8 -_-
import os
import random
train_percent = 0.8 # 训练集占数据的比例
val_percent = 0.15 # 验证集占数据的比例
test_percent = 0.05 # 测试集占数据集的比例
xmlfilepath = ‘Annotations’
txtsavepath = ‘ImageSets/Main’
total_xml = os.listdir(xmlfilepath)
num = len(total_xml) # 图片数量
list = range(num)
train_num = int(num _ train_percent) # train的数量
test_num = int(num _ test_percent) # test的数量
val_num = int(num _ val_percent) # val的数量
trainval = random.sample(list, train_num + val_num)
train = random.sample(trainval, train_num)
ftest = open(‘ImageSets/Main/test.txt’, ‘w’)
ftrain = open(‘ImageSets/Main/train.txt’, ‘w’)
fval = open(‘ImageSets/Main/val.txt’, ‘w’)
for i in list:
name = total_xml[i][:-4] + ‘\n’
if i in trainval:
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrain.close()
ftest.close()
fval.close()

运行之后,将在ImgeSets/Main目录下生成下面这些文件。
四、训练模型
4.1 修改voc_annocation.py
该文件用于生成下图所示的文本文件,包括train.txt,test.txt,val.txt。
其中包含图片的目录,以及图片中标签位置数据。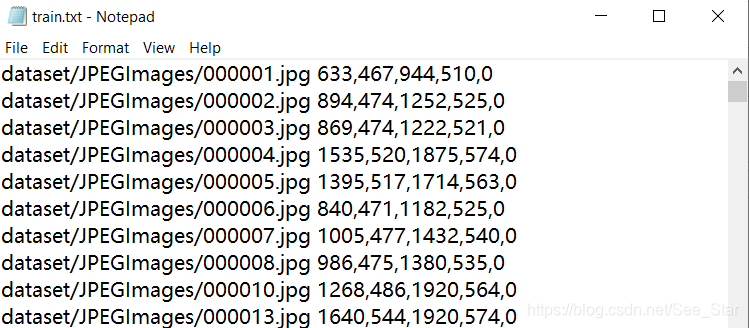
对文件进行修改,修改结果如下,修改了类别(classes)、图片的打开目录和保存目录。
# -_- coding:utf-8 -_-
import xml.etree.ElementTree as ET
from os import getcwd
sets = [‘train’, ‘val’, ‘test’]
classes = [“person”, “hat”]
def convert_annotation(image_id, list_file):
print(image_id)
in_file = open(‘dataset/Annotations/%s.xml’ % image_id)
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter(‘object’):
difficult = obj.find(‘difficult’).text
cls = obj.find(‘name’).text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find(‘bndbox’)
b = (int(xmlbox.find(‘xmin’).text), int(xmlbox.find(‘ymin’).text), int(xmlbox.find(‘xmax’).text), int(xmlbox.find(‘ymax’).text))
list_file.write(“ “ + “,”.join([str(a) for a in b]) + ‘,’ + str(cls_id))
wd = getcwd()
for image_set in sets:
image_ids = open(dataset/ImageSets/Main/%s.txt’ % image_set).read().strip().split()
print(image_ids)
list_file = open(‘%s.txt’ % image_set, ‘w’)
for image_id in image_ids:
list_file.write(‘dataset/JPEGImages/%s.jpg’ % image_id)
convert_annotation(image_id, list_file)
list_file.write(‘\n’)
list_file.close()
- 36
4.2 修改yolo3.cfg
打开yolo3.cfg,搜索yolo(共三处),每次均按下图修改。
filters:3_(5+len(classes))
classes:训练的类别数
random:原来是1,显存小改为0
4.3 增加my_classes.txt
目录如下图所示,将my_classes.txt的内容修改为为自己训练的类别。
4.4 修改train.py
这是代码最主要的部分,需要根据训练的情况进行调整:
18行:需要创建改目录
19行:因为自己的类与源码不同,所以需修改成classes_path = ‘model_data/my_classes.txt’
52行:将if True改成if False,不使用该种训练方式。通过该方式训练出的模型效果很差。
76行:根据GPU显存进行调节,越大越好,由于GPU限制,我只能设置为3。
82行:迭代次数,初始值为50,为了迭代100次,所以此处设置epochs=150。当过拟合时会自动停止训练。
“””
Retrain the YOLO model for your own dataset.
“””
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.optimizers import Adam
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
def _main():
annotation_path = ‘train.txt’
log_dir = ‘model/001/‘
classes_path = ‘model_data/my_classes.txt’
anchors_path = ‘model_data/yolo_anchors.txt’
class_names = get_classes(classes_path)
num_classes = len(class_names)
anchors = get_anchors(anchors_path)
input_shape = (416,416) # multiple of 32, hw
is_tiny_version = len(anchors)==6 # default setting
if is_tiny_version:
model = create_tiny_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path=‘model_data/tiny_yolo_weights.h5’)
else:
model = create_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path=‘model_data/yolo_weights.h5’) # make sure you know what you freeze
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + ‘ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5’,
monitor=‘val_loss’, save_weights_only=True, save_best_only=True, period=3)
reduce_lr = ReduceLROnPlateau(monitor=‘val_loss’, factor=0.1, patience=3, verbose=1)
early_stopping = EarlyStopping(monitor=‘val_loss’, min_delta=0, patience=10, verbose=1)
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)_val_split)
num_train = len(lines) - num_val
# Train with frozen layers first, to get a stable loss.
# Adjust num epochs to your dataset. This step is enough to obtain a not bad model.
if False:
model.compile(optimizer=Adam(lr=1e-3), loss={
# use custom yolo_loss Lambda layer.
‘yolo_loss’: lambda y_true, y_pred: y_pred})
batch_size = 16
print(‘Train on {} samples, val on {} samples, with batch size {}.’.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
model.save_weights(log_dir + ‘trained_weights_stage_1.h5’)
# Unfreeze and continue training, to fine-tune.
# Train longer if the result is not good.
if True:
for i in range(len(model.layers)):
model.layers[i].trainable = True
model.compile(optimizer=Adam(lr=1e-4), loss={‘yolo_loss’: lambda y_true, y_pred: y_pred}) # recompile to apply the change
print(‘Unfreeze all of the layers.’)
batch_size = 3 # note that more GPU memory is required after unfreezing the body
print(‘Train on {} samples, val on {} samples, with batch size {}.’.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=150,
initial_epoch=50,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
model.save_weights(log_dir + ‘trained_weights_final.h5’)
# Further training if needed.
def get_classes(classes_path):
‘’’loads the classes’’’
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
‘’’loads the anchors from a file’’’
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(‘,’)]
return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=2,
weights_path=‘model_data/yolo_weights.h5’):
‘’’create the training model’’’
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print(‘Create YOLOv3 model with {} anchors and {} classes.’.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print(‘Load weights {}.’.format(weights_path))
if freeze_body in [1, 2]:
# Freeze darknet53 body or freeze all but 3 output layers.
num = (185, len(model_body.layers)-3)[freeze_body-1]
for i in range(num): model_body.layers[i].trainable = False
print(‘Freeze the first {} layers of total {} layers.’.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name=‘yolo_loss’,
arguments={‘anchors’: anchors, ‘num_classes’: num_classes, ‘ignore_thresh’: 0.5})(
[_model_body.output, _y_true])
model = Model([model_body.input, _y_true], model_loss)
return model
def create_tiny_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=2,
weights_path=‘model_data/tiny_yolo_weights.h5’):
‘’’create the training model, for Tiny YOLOv3’’’
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16}[l], w//{0:32, 1:16}[l], \
num_anchors//2, num_classes+5)) for l in range(2)]
model_body = tiny_yolo_body(image_input, num_anchors//2, num_classes)
print(‘Create Tiny YOLOv3 model with {} anchors and {} classes.’.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print(‘Load weights {}.’.format(weights_path))
if freeze_body in [1, 2]:
# Freeze the darknet body or freeze all but 2 output layers.
num = (20, len(model_body.layers)-2)[freeze_body-1]
for i in range(num): model_body.layers[i].trainable = False
print(‘Freeze the first {} layers of total {} layers.’.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name=‘yolo_loss’,
arguments={‘anchors’: anchors, ‘num_classes’: num_classes, ‘ignore_thresh’: 0.7})(
[_model_body.output, _y_true])
model = Model([model_body.input, _y_true], model_loss)
return model
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
‘’’data generator for fit_generator’’’
n = len(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
if i==0:
np.random.shuffle(annotation_lines)
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i = (i+1) % n
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, _y_true], np.zeros(batch_size)
def data_generator_wrapper(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
if n==0 or batch_size<=0: return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == ‘__main__‘:
_main()
注意,需要创建model/000目录: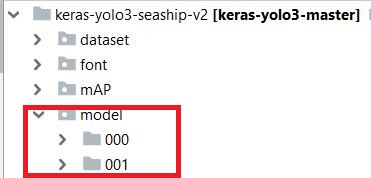
这个目录的作用就是存放自己的数据集训练得到的模型。不然程序运行到最后会因为找不到该路径而发生错误。
训练结束后,会生成很多模型,很多如图中标注的文件,还有最终的模型trained_weights_final.h5,正常情况下就选择最终的模型,如果前面的模型loss较低也可以选择前面的模型。
五、验证模型
创建test_yolo.py文件:
43行:模型存放位置
如果计算mAP,取消257~270行的注释,并创建如下文件目录:
代码如下:
# -_- coding: utf-8 -_-
“””
Class definition of YOLO_v3 style detection model on image and video
“””
import colorsys
import os
import time
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
dir_project = os.getcwd() # 获取当前目录
# 创建创建一个存储检测结果的dir
result_path = ‘./result’
if not os.path.exists(result_path):
os.makedirs(result_path)
# result如果之前存放的有文件,全部清除
for i in os.listdir(result_path):
path_file = os.path.join(result_path, i)
if os.path.isfile(path_file):
os.remove(path_file)
# 创建一个记录检测结果的文件
txt_path = result_path + ‘/result.txt’
file = open(txt_path, ‘w’)
class YOLO(object):
_defaults = {
“model_path”: ‘model/001/trained_weights_final.h5’,
“anchors_path”: ‘model_data/yolo_anchors.txt’,
“classes_path”: ‘model_data/my_classes.txt’,
“score” : 0.3,
“iou” : 0.45,
“model_image_size” : (416, 416),
“gpu_num” : 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return “Unrecognized attribute name ‘“ + n + “‘“
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(‘,’)]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith(‘.h5’), ‘Keras model or weights must be a .h5 file.’
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) _ (num_classes + 5), \
‘Mismatch between model and given anchor and class sizes’
print(‘{} model, anchors, and classes loaded.’.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(_x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] _ 255), int(x[1] _ 255), int(x[2] _ 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, ‘Multiples of 32 required’
assert self.model_image_size[1]%32 == 0, ‘Multiples of 32 required’
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype=‘float32’)
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print(‘Found {} boxes for {}’.format(len(out_boxes), ‘img’))
font = ImageFont.truetype(font=‘font/FiraMono-Medium.otf’,
size=np.floor(3e-2 _ image.size[1] + 0.5).astype(‘int32’))
thickness = (image.size[0] + image.size[1]) // 300
# # 保存框检测出的框的个数 (添加)
# file.write(‘find ‘ + str(len(out_boxes)) + ‘ target(s) \n’)
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = ‘{} {:.2f}’.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype(‘int32’))
left = max(0, np.floor(left + 0.5).astype(‘int32’))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype(‘int32’))
right = min(image.size[0], np.floor(right + 0.5).astype(‘int32’))
# # 写入检测位置(添加)
# file.write(
# predicted_class + ‘ score: ‘ + str(score) + ‘ \nlocation: top: ‘ + str(top) + ‘、 bottom: ‘ + str(
# bottom) + ‘、 left: ‘ + str(left) + ‘、 right: ‘ + str(right) + ‘\n’)
file.write(predicted_class + ‘ ‘ + str(score) + ‘ ‘ + str(left) + ‘ ‘ + str(top) + ‘ ‘ + str(right) + ‘ ‘ + str(bottom) + ‘;’)
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=“”):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError(“Couldn’t open webcam or video”)
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC)) # 获得视频编码MPEG4/H264
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != “” else False
if isOutput:
print(“!!! TYPE:”, type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = “FPS: ??”
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(frame) # 从array转换成image
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = “FPS: “ + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow(“result”, cv2.WINDOW_NORMAL)
cv2.imshow(“result”, result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord(‘q’):
break
yolo.close_session()
# 批量处理文件
if __name__ == ‘__main__‘:
# 读取test文件
with open(“dataset/ImageSets/Main/test.txt”, ‘r’) as f: # 打开文件
test_list = f.readlines() # 读取文件
test_list = [x.strip() for x in test_list if x.strip() != ‘’] # 去除/n
# print(test_list)
t1 = time.time()
yolo = YOLO()
# for filename in test_list:
# image_path = ‘dataset/JPEGImages/‘+filename+’.jpg’
# portion = os.path.split(image_path)
# # file.write(portion[1]+’ detect_result:\n’)
# file.write(image_path + ‘ ‘)
# image = Image.open(image_path)
# image_mAP_save_path = dir_project + ‘/mAP/input/images-optional/‘
# image.save(image_mAP_save_path + filename + ‘.jpg’)
# r_image = yolo.detect_image(image)
# file.write(‘\n’)
# #r_image.show() 显示检测结果
# image_save_path = ‘./result/result_‘+portion[1]
# print(‘detect result save to….:’+image_save_path)
# r_image.save(image_save_path)
time_sum = time.time() - t1
# file.write(‘time sum: ‘+str(time_sum)+’s’)
print(‘time sum:’,time_sum)
file.close()
yolo.close_session()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
六、检测结果
这部分就放一些图片好了:

七、计算mAP
前面有提到过
mAP计算:【目标检测】kera-yolo3模型计算mAP
mAP源码:https://github.com/Cartucho/mAP
修改mAP源码,针对keras-yolov3的检测结果计算mAP。
mAP在95.66%,正确率也在95%左右。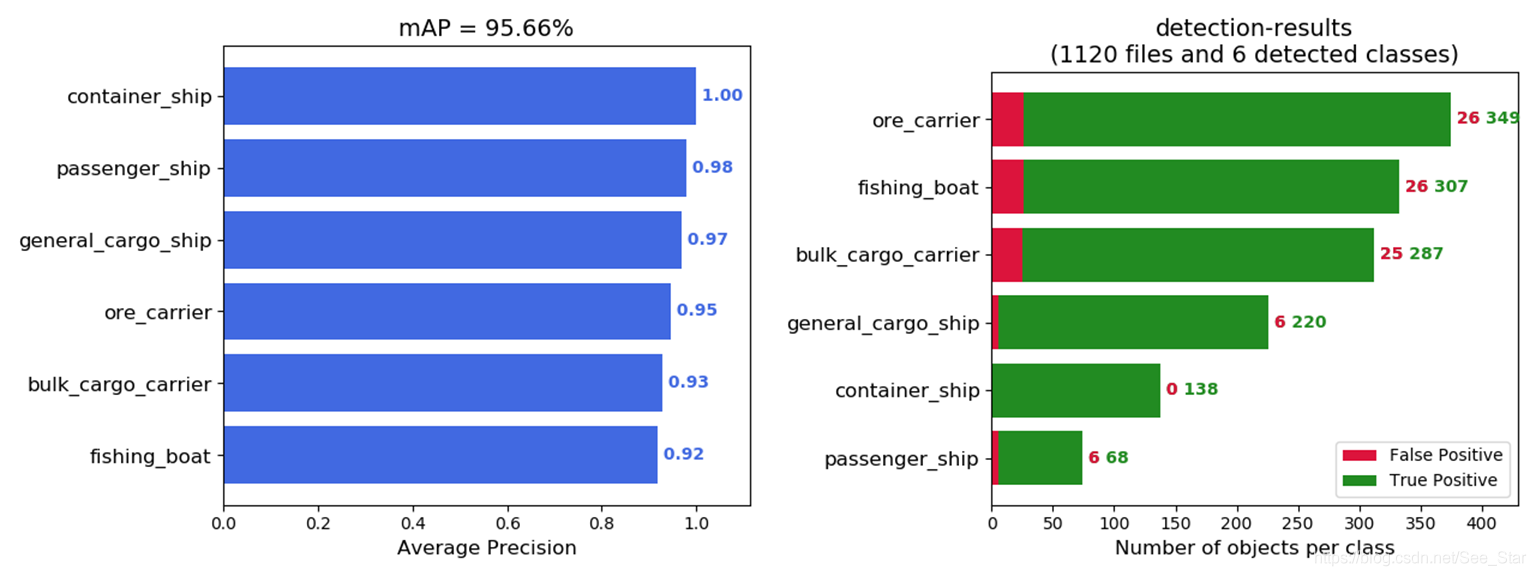
预测边界框与真实边界框对比:
此篇博客内容为博主的毕设的一部分,如有不正确的部分欢迎指正,如有问题欢迎讨论~
八、检测模型下载
很多人向博主要检测模型,所以我就将它放在百度云上了,需要的朋友可以自行提取。
链接:https://pan.baidu.com/s/1N_DgVYrWFrM9syybrpBFSw
提取码:de2i



评论(0)
您还未登录,请登录后发表或查看评论