

0. 简介
其实3D Gaussian Splatting和MVS,SFM,Nerf这类比较类似,但是我们发现辐射场一类场景表示方法已经在新视角渲染任务上得到了革命性的进展,但是在高分辨率图片上由于需要使用神经网络,导致训练和渲染都需要十分昂贵的代价,因此最近那些速度比较快的方法都不可避免地需要通过损失质量来提高速度。
而3D 高斯泼溅(Splatting)是用于实时辐射场渲染的 3D 高斯分布描述的一种光栅化技术,它允许实时渲染从小图像样本中学习到的逼真场景。3D Gaussian Splatting的pipeline分为3个步骤:1、从相机配准过程中得到的稀疏点云开始,使用3D Gaussian表示场景2、对3D Gaussians进行交叉优化和密度控制3、使用快速可视感知渲染算法来进行快速的训练和渲染。这完全属于颠覆性的工作
1. 常见的重建方法
1.1 传统的场景重建与渲染
传统的场景重建和渲染的方法,如SfM、MVS,核心思路是根据几何来指导输入图像到摄像机的重投影和融合,在这个过程中来重建场景。一般来说这些方法能得到较好的结果,但当MVS产生不存在的几何时很难从未重建区域或过度重建区域中恢复,并且将所有输入图片存储在GPU上的花费太大。
1.2 神经渲染和辐射场
神经渲染和辐射场主要的方法是volumetric ray-marching,如NeRF取得了巨大的成功,但是训练很慢。目前加速的方法主要利用三点:1.利用空间数据结构存储volumetric ray-marching过程中使用到的feature,并利用插值的方法得到不位于顶点的feature;2.不同的编码;3.MLP capacity。如NGP、Plenoxels得到了很好的效果,但却仍然较难以高效表示空白区域,并且较为依赖场景和捕捉图像的形式。
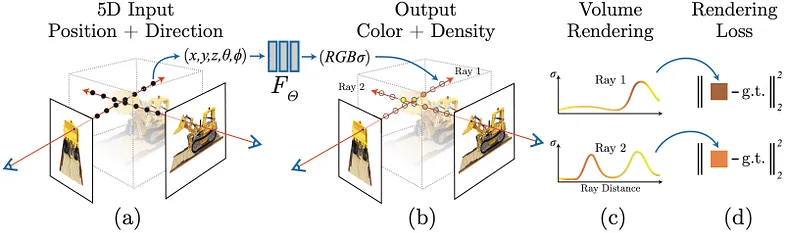
MERF作为一种加速NERF的方法被提出,它通过将多个方向上的光线追踪结果预先烘焙成体积纹理来实现实时处理。 然而,由于 MERF 使用固定大小的体积纹理(如 512x512x512)和高分辨率纹理(如 2048x2048),因此输出的细节和形状保真度会降低。
[外链图片转存中…(img-aNw0NZRM-1703838847746)]
1.3 基于点的渲染和辐射场
基于点的方法(即点云)有效地渲染了断开的和非结构化的几何样本。点采样渲染栅格化具有固定大小的非结构化点集,它可以利用本地支持的点类型的图形api或并行软件栅格化。但对于底层数据来说,点的采样会面临空洞、混叠的问题,并且是不连续的。而将point primitives “splatting” 到大于一个像素的范围,例如圆形、椭圆形、椭球,的方法解决了这些问题,实现了高质量的point-based rendering。而目前一些基于differentiable point-based rendering的方法能够达到real-time,但仍依赖MVS来初始化几何,并且继承了其在欠/过重建区域的artifacts。

1.4 快速光栅化-3D 高斯泼溅
Tile-based rasterizer (快速光栅化):将三维场景中的mesh面片,分割成小的片段,并将这些片段映射到屏幕上的 tile瓦片(区域而非像素),然后进行光栅化、深度测试和像素着色等操作,最终将三维场景转化为二维图像。这个过程是图形引擎或渲染器中的核心步骤,步骤为:
- 分割三角形:首先,三维场景中的三角形会被分割成小的三角形片段。这个过程通常是由图形引擎或渲染器完成的。分割的目的是为了更好地适应不同的瓦片大小或屏幕分辨率。
- 映射到瓦片:每个小的三角形片段会被映射到屏幕上的相应瓦片中。瓦片是屏幕上的一个小区域,可以是一个像素或者多个像素的集合。这个映射过程会计算片段在屏幕上的位置、深度值等信息。
- 光栅化:映射到瓦片后,tile-based rasterizer会将每个小的三角形片段转化为屏幕上的像素。这个过程被称为光栅化。在光栅化过程中,对于每个片段,会计算其在屏幕上的位置、深度值等信息。
- 深度测试:在光栅化过程中,进行深度测试是非常重要的。深度测试用于确定哪些像素应该被绘制。通过比较片段的深度值与屏幕上对应像素的深度值,可以确定是否绘制该像素。这样可以确保在绘制过程中正确处理遮挡关系,以产生正确的渲染结果。
- 像素着色:光栅化的最后一步是像素着色。在像素着色过程中,根据片段的属性(如颜色、纹理等),为每个像素计算最终的颜色值。这样,三维场景就被转化为了屏幕上的二维图像。
摄影测量(Photogrammetry)是一种从多视点图像生成 3D 多边形的技术,例如将物体放在转台上并在将物体旋转 360 度的同时拍照。 虽然摄影测量对于扫描物体很有用,但它无法渲染没有轮廓的场景,例如天空或远处场景的精细细节。 此外,由于优化是通过解决传统优化问题来执行的,因此对于某些用例(例如反射和镜子)不可能准确生成 3D 多边形。

3D 高斯泼溅:3D 高斯泼溅的核心是一种光栅化技术。类似于计算机图形学中的三角形光栅化,它可以实时渲染。 首先,将多个视点的图像转换为点云,然后将点云转换为带参数的高斯分布,最后使用机器学习来学习参数。

虽然高斯参数的训练需要机器学习,但渲染不需要任何繁重的处理,并且可以实时完成。
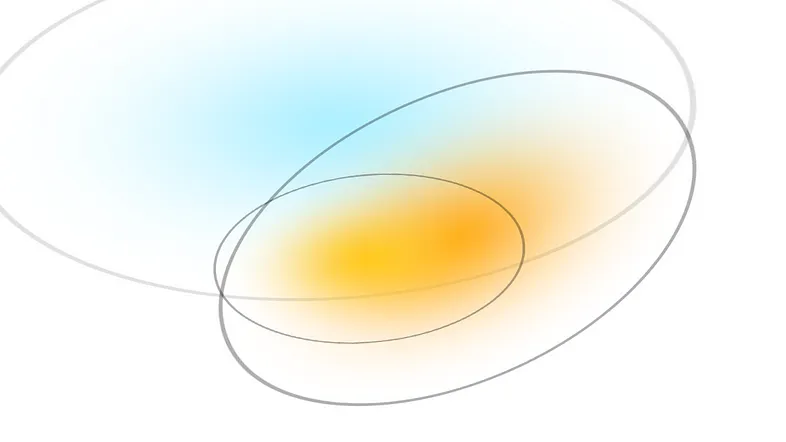
高斯泼溅由以下参数描述:1. 位置:它所在的位置 (XYZ) 2. 协方差:如何拉伸/缩放(3x3 矩阵) 3. 颜色:它是什么颜色(RGB) 4.Alpha:透明度如何 (α)。对于《3D Gaussian Splatting》详细可以参考这篇杀生丸学AI的博文,这里博主将大致的内容截取了。


2. 3D Gaussian Splatting使用
2.1 Windows
这里直接使用了分形噪波UP主的测试使用,其实在Windows下使用3D Gaussian Splatting还是很方便的
[video(video-4Fd9Wk6p-1703838140122)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=318296662)(image-https://img-blog.csdnimg.cn/img_convert/1b8ff9af683c3ace95e6a07859a2ca0b.jpeg)(title-【AI生成场景新突破】3D Gaussian Splatting入门指南)]
在传统的摄影测量流程中,可以将一组2d图像转换成点云。
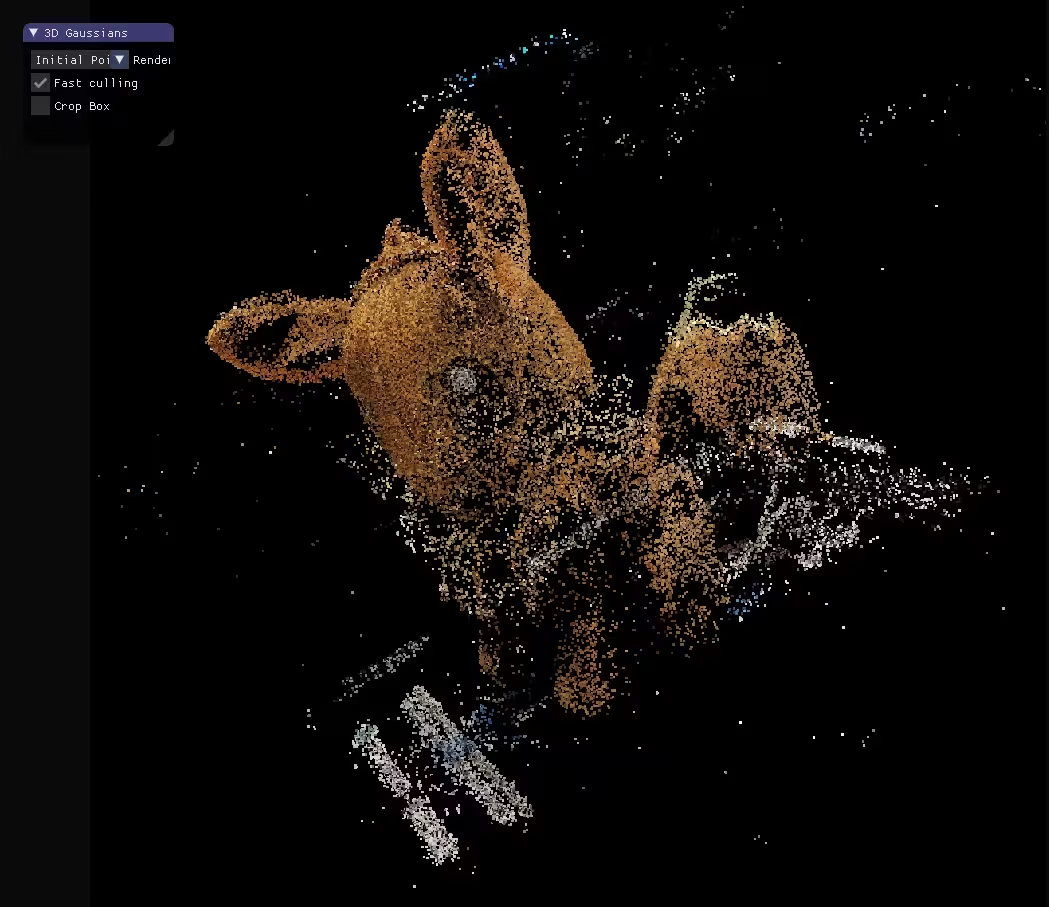
而3D Gaussian Splatting更进一步,将点云变成3d空间中的椭球体,每个椭球体都拥有位置\大小和选择都经过优化颜色和不透明度。当混合在一起时,可以产生从任何角度渲染的完整模型的可视化效果。
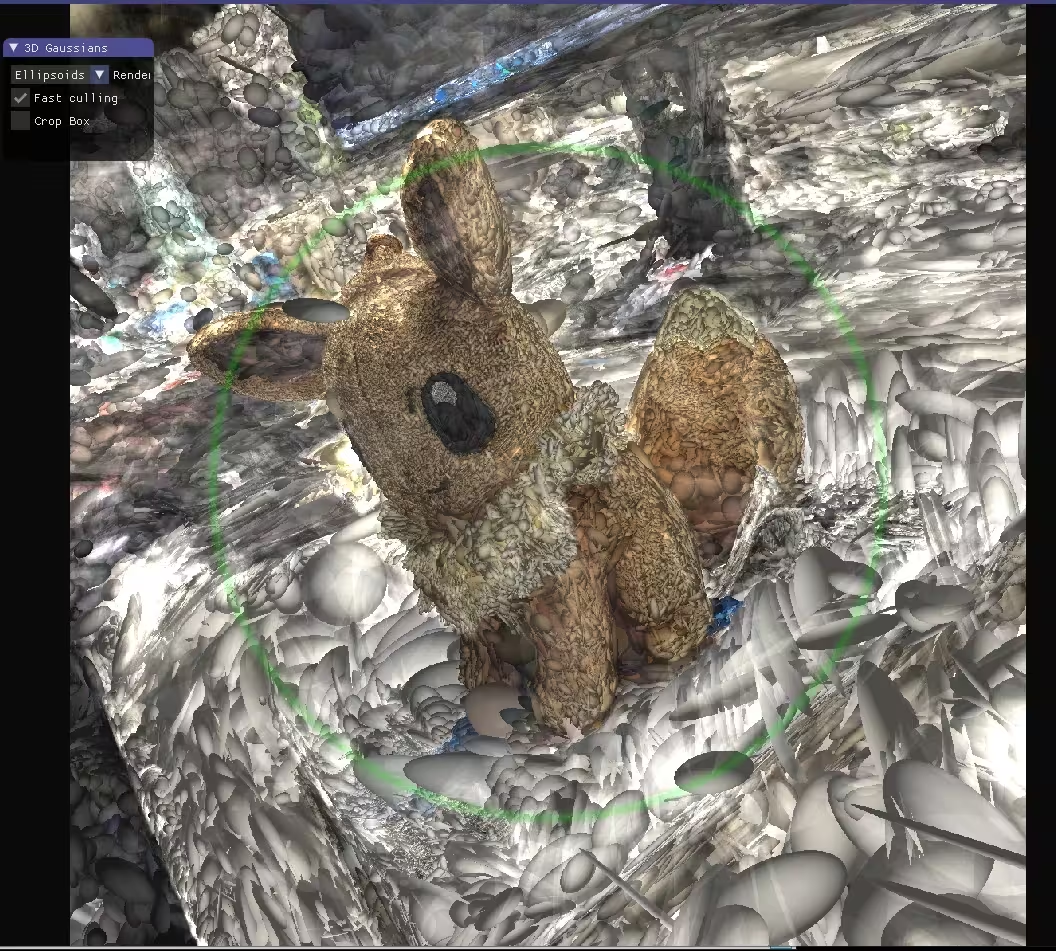
2.2 Ubuntu
- 软件要求
Conda(推荐使用,以便于设置)
用于 PyTorch 扩展的 C++ 编译器(我们使用 Visual Studio 2019 for Windows)
用于 PyTorch 扩展的 CUDA SDK 11,在 Visual Studio 之后安装(我们使用 11.8,11.6 存在已知问题)
C++编译器和CUDA SDK必须兼容 - 设置
SET DISTUTILS_USE_SDK=1 # Windows only
conda env create --file environment.yml
conda activate gaussian_splatting
请注意,此过程假设您安装了 CUDA SDK 11,而不是 12。有关修改,请按照下文修改。
conda config --add pkgs_dirs <Drive>/<pkg_path>
conda env create --file environment.yml --prefix <Drive>/<env_path>/gaussian_splatting
conda activate <Drive>/<env_path>/gaussian_splatting
运行
python train.py -s <path to COLMAP or NeRF Synthetic dataset>
评估
python train.py -s <path to COLMAP or NeRF Synthetic dataset> --eval # Train with train/test split
python render.py -m <path to trained model> # Generate renderings
python metrics.py -m <path to trained model> # Compute error metrics on renderings
3. 参考连接
https://zhuanlan.zhihu.com/p/665135145
https://blog.csdn.net/qq_45752541/article/details/132854115
https://mp.weixin.qq.com/s/mSyfS3bWDnBQBGFjtJU2QA



(image-https://img-blog.csdnimg.cn/img_convert/1b8ff9af683c3ace95e6a07859a2ca0b.jpeg)(title-【AI生成场景新突破】3D){kind=link}
评论(0)
您还未登录,请登录后发表或查看评论