贝叶斯决策、概率估计
Introduction
将未知的东西,进行正确的类别划分,叫做classification。怎么用有效的数字、符号来表示你的未知的东西呢?我们将其称之为
feature,它能够有效表达未知物品,或者说所需要分类的物品的有效信息。大量的特征组成
特征向量{x1,x2,…,xl}用矩阵表示如下
介绍一些基本符号:

有了这些之后,我们来举个例子解释一下这些符号:
假设现在有100个学生,分类男同学和女同学,那么classes :
ω1= male, ω2= female ;我们所观察到的特征假设为身高,特征向量:
x= height ,这里的特征只有1个维度;假设男女同学各为50人,那么A-priori probabilities :
P(ωi)=0.5,i=1,2,那我们怎么来求它的A-posteriori probability :
P(ωi∣x),i=1,2 呢?依据我们手中100个学生的样本我们能统计出Class-conditional PDF :
p(x∣ωi),i=1,2 ,表示的是知道是某个类别,在这个类别中,某个特征所占的概率,比如知道是男生,其身高是165的概率。

Bayesian Classifier
由上文所述,我们依据统计能够知道Class-conditional PDF :
p(x∣ωi),i=1,2,也就是知道是男生,是165的概率,而机器学习做的是给定特征,希望得到类别的概率,也就是说告诉你是165,这个人是男生的概率是多少,是女生的概率又是多少?也就是A-posteriori probability :
P(ωi∣x),i=1,2。
Bayesian Rule 建立起了两者之间的桥梁:
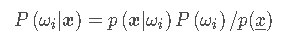
我们给一组数据实际计算一下:
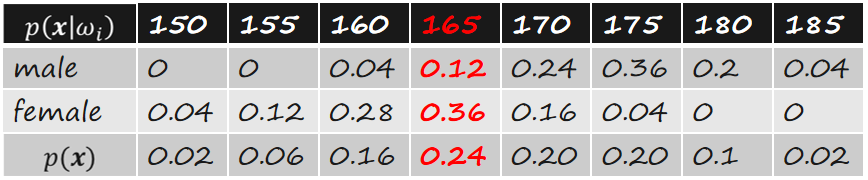
现在想要知道,给定165这个特征,属于男性的概率是多少?属于女性的概率又是多少?依据Bayesian Rule计算规则过程如下所示:

拿到准确的概率我们就能够判断,其来自女性的概率要大于男性的概率,做分类问题的话,就将其判定为女性即可。

如果我们只需要判定属于哪一个类别的话,我们只需要判定上式中的分子部分即可。上述判定式等价于:

而本例中,男女比例一样多,也就是a-priori probabilities P

由此,上式等价于:

那这两个分布又长什么样子呢?什么时候会判别为第一类?什么时候判别为第二类呢?将其画出,如下所示:
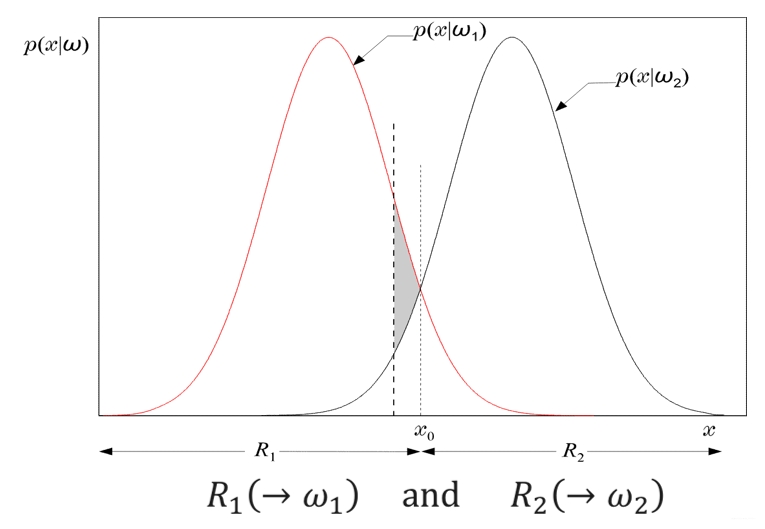 x
x 在左边属于
w1类,右边属于
w2类,中间
x0处无法划分。效果最好的划分也是当
x=x0处能够达到,在这个点处,产生的误判率如下所示:
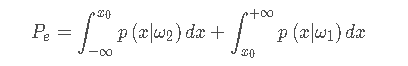
贝叶斯优化器所需要优化的就是最小化误判率。如上图所示:移动虚线边界,所产生的阴影部分就是能够优化的多余的误差。
然而在真实的生活中,对不同类别之间的判断成本是不一样的。比如,将得了恶性肿瘤 (malignant) 判定为良性肿瘤(benign),比良性肿瘤判定为得了恶性肿瘤要严重。因为误判定为良性肿瘤很有可能损失这个人的生命,而误判定为恶性肿瘤,这个人很有可能会换几家医院复检。
对于二分类问题,定义风险矩阵:
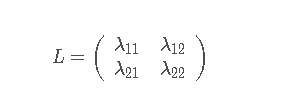
其中
λ12 表示的是将
ω1类判定为
ω2类。它们之间的关系如下所示:

恶性肿瘤判定为良性肿瘤的风险
λ21 ,大于良性肿瘤判定为恶性肿瘤的风险
λ12 ,大于恶性肿瘤判定为恶性肿瘤的风险
λ22 ,大于良性肿瘤判定为良性肿瘤的风险
λ11 。
之前判定的是属于类别
ω1的概率大,还是属于类别
ω2的概率大。


很明显判定为良性的条件在加入风险函数后要更苛刻(判定为恶性的概率,乘了一个大于1的系数)。如果拿风险来作为判定的依据,我们希望是风险最少。也就是两者之间的平均风险最小。由此做优化。
ω1的风险:
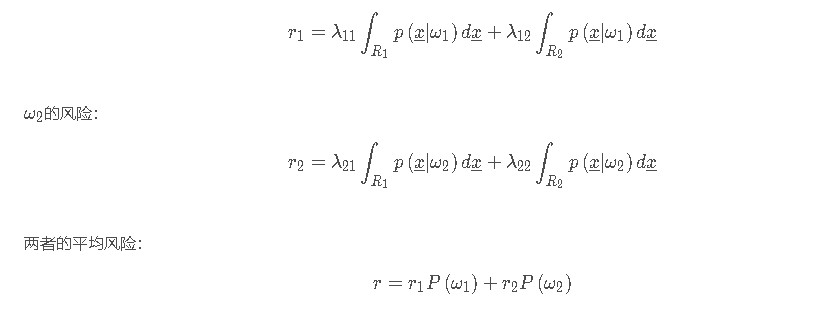
最小化平均风险作为优化目标。
说完了风险函数,我们再回到之前的男女分类问题,g
(x)≡P(ωi∣x)−P(ωj∣x)=0是他的决策面(decision surface),大于0属于一类,小于0属于另一类。如果
f(.)单调,
gi(x)≡f(P(ωi∣x)) 是决策函数(discriminant function)。
样本我们有,但是我们怎么才能快速知道样本所服从的Class-conditional PDF
p(x∣ωi)呢?因为数据量大了的话,统计这个分布还是有点难搞,那能不能先假设其服从某种分布,然后依据手中的数据去计算出这个分布大概长什么样子呢?却是,就是这么做的,并且一般假设服从的是高斯分布:
[多元高斯分布 The Multivariate normal distribution]

Probability Estimation
概率估计问题又分为参数估计(Parametric estimation)和非参数估计(Nonparametric estimation)。对于参数估计,上一节末尾所述的高斯分布的均值和方差就是参数估计问题中所要估计的参数。这里就能引出三种算法:
最大似然估计(MLE, Maximum Likelihood Estimation);
最大后验概率估计(MAP, Maximum A Posteriori Estimation);
EM(Expectation Maximization)算法。
-
最大似然估计(MLE, Maximum Likelihood Estimation)
在统计中,似然(Likelihood)与概率(probability)是不同的东西。概率是已知参数,对结果可能性的预测。似然是已知结果,对参数是某个值的可能性预测。下图很好展示了这一概念:

最大似然估计(Maximum Likelihood Estimation)简写问MLE,其直观的思想是使得观测数据(样本)发生概率最大的参数就是最好的参数。
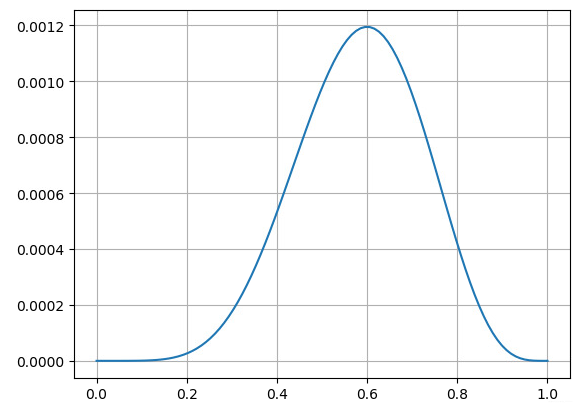
对于一个独立同分布的样本集来说,总体的似然就是每个样本似然的乘积。针对抛硬币的问题,似然函数可写作:

用Python将其图像画出如下图所示:
import numpy as np
import matplotlib.pyplot as plt
import math
x = np.linspace(0, 1, 100)
y = [math.pow(i,6)*math.pow((1-i), 4) for i in x]
plt.grid()
plt.plot(x, y)
plt.show()
对其求偏导,并令其等于0,求解如下:
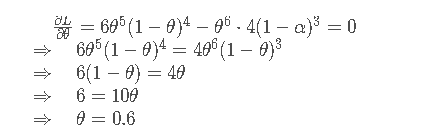
公式求解与图像所对应,说明求解正确。
由于我们经常用高斯函数去构造概率密度函数。高斯函数如下所示:


可知其求解结果与之前一致,但计算量急剧下降。
正态分布的最大似然估计


-
最大后验概率估计 (MAP, Maximum A Posteriori Estimation)
在最大似然估计中,我们需要使
∏i=0nP(xi∣θ)最大,也就是期望找到一个参数
θ,能够使整个样本发生的概率最大。这个参数
θ是一个固定值,需要求解。
在最大后验概率估计中认为
θ服从某种分布,是一个随机变量,我们将其称为先验分布。那此时整个事件发生的概率是
∏i=0nP(xi∣θ)p(θ)。找到能使其取到最大值的
θ。
到这里其实最大后验概率估计就能够进行求解,我们看一下它跟贝叶斯概率以及最大似然估计的关系。由于
x的先验分布
p(x)是固定的(可通过分析数据获得,其实我们也并不关系
x的分布,我们关系的是
θ.)因此最大化函数可变为
p(x∣θ)p(θ)/p(x),进而依据贝叶斯法则能够将其转化为后验概率。
最大后验概率估计可以看作是正则化的最大似然估计,当然机器学习或深度学习中的正则项通常是加法,而在最大后验概率估计中采用的是乘法,
p(θ)是正则项。在最大似然估计,由于认为
θ是固定的,因此
P(θ)=1。
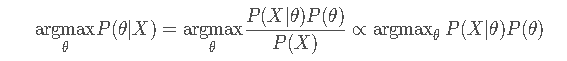
例:
1.确定参数的先验分布以及似然函数:
用均值为0.5,方差为0.1的高斯分布来描述
θ \thetaθ的先验分布,(当然也可以用其它的分布来描述
θ的先验分布。
θ的先验分布):
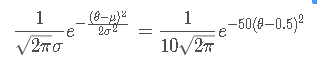
用Python画出其分布:
import math
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 1, 100)
y = [1 / (10 * math.sqrt(2* math.pi)) * math.exp(-50 * math.pow((i - 0.5), 2)) for i in x]
plt.grid()
plt.plot(x, y)
plt.show()
 2.确定参数的后验分布函数:
2.确定参数的后验分布函数:

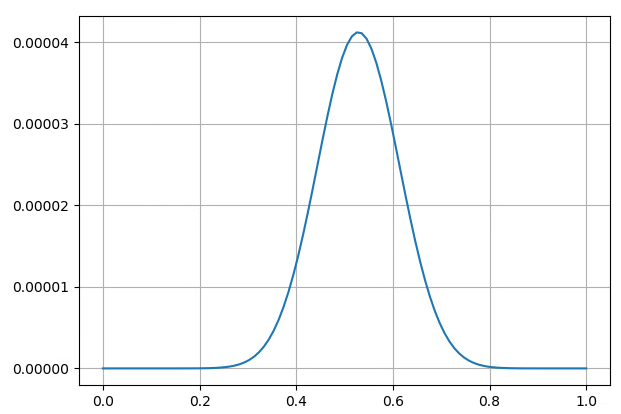
如果我们用均值为0.6,方差为0.1的高斯分布来描述
θ 的先验分布,则
θ^=0.6。由此可见,在最大后验概率估计中,
θ的估计值与
θ的先验分布会有很大的关系。这也说明一个合理的先验概率假设是非常重要的,如果先验分布假设错误,则会导致估计的参数值偏离实际的参数值。
参考:
贝叶斯估计、最大似然估计、最大后验概率估计
贝叶斯学派与频率学派有何不同?
李航统计学方法


 拿到准确的概率我们就能够判断,其来自女性的概率要大于男性的概率,做分类问题的话,就将其判定为女性即可。
拿到准确的概率我们就能够判断,其来自女性的概率要大于男性的概率,做分类问题的话,就将其判定为女性即可。
 如果我们只需要判定属于哪一个类别的话,我们只需要判定上式中的分子部分即可。上述判定式等价于:
如果我们只需要判定属于哪一个类别的话,我们只需要判定上式中的分子部分即可。上述判定式等价于:
 而本例中,男女比例一样多,也就是a-priori probabilities P
而本例中,男女比例一样多,也就是a-priori probabilities P



评论(0)
您还未登录,请登录后发表或查看评论