文章目录
-
- 指数家族
- 伯努利分布转指数家族
- 高斯分布转指数家族
- 指数家族的性质
- 最大熵模型
- 最大熵似然法
- 参考
了解最大熵模型之前,我们需要先了解一个和最大熵模型相伴的概念,
指数家族。
指数家族
指数家族是一个包含我们常见的概率分布的分布族。不管是离散概率分布的代表
伯努利分布还是连续概率分布的代表
高斯分布,它们
都属于指数家族。将其抽象到指数家族这一类会有一些性质,利于求解部分问题。指数家族的基本公式形式为:
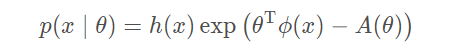
其中
h ( x ) 一般被认为是一个简单的乘子项,大多数时候是一个常量。
θ表示模型中的参数,
ϕ ( x ) )被成为函数的充分统计量(
Sufficient Statistic),
A ( θ ) 被称为对数分割函数(
Log Partition Function),一般被用来归一化所有的概率项,具体形式为:
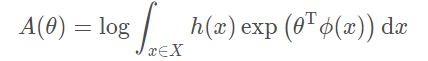
那常见的分布模型是如何变换成上述这种形式的呢?
伯努利分布转指数家族
伯努利分布的形式为:
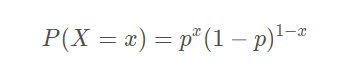
其中
p 表示
X = 1 时的概率,将其做一定变换得到:
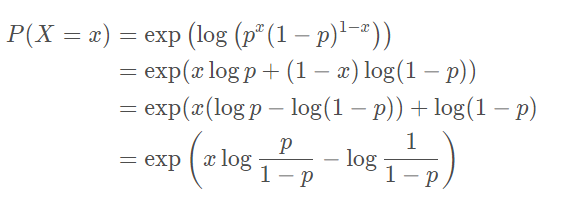
其中
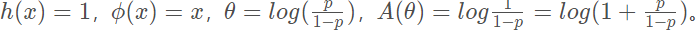
高斯分布转指数家族
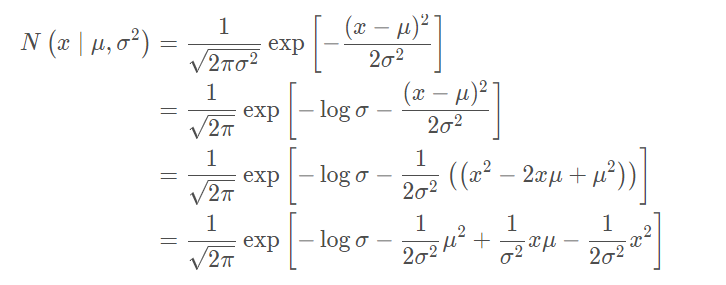
其中
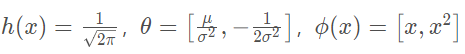
,对于
A ( θ ) 有:
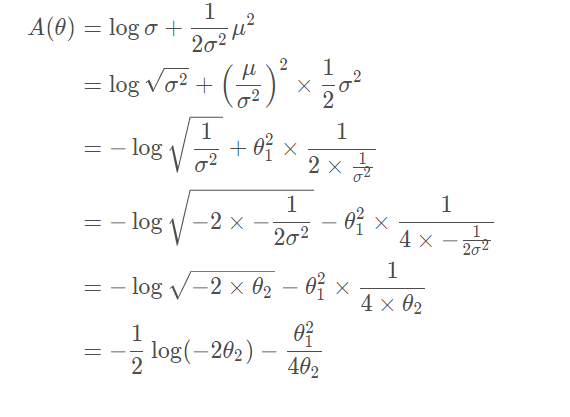
指数家族的性质
- A ( θ ) 的一阶导等于ϕ ( x ) 的期望:
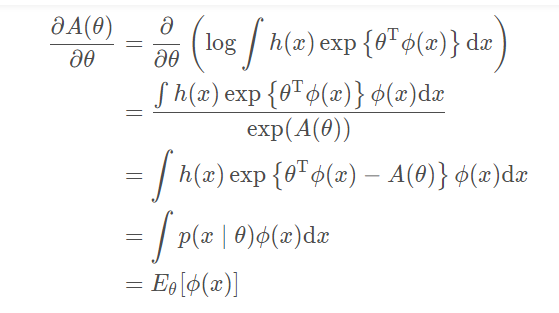
- A ( θ ) 的二阶导等于ϕ ( x ) 的方差:
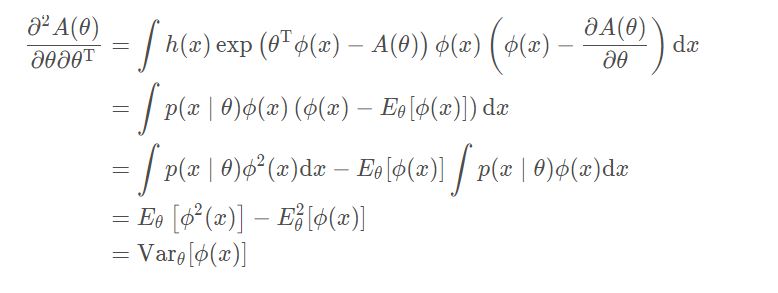
因此,将概率分布以指数家族的形式表达后,
ϕ ( x ) 的期望与方差实际上拥有两种解法,一种是直接使用这个函数进行求解,另一种则是采用对数分割函数进行求解。在实际问题中选择一种简便方式即可。
之后为了简便,指数家族采用如下简单的形式:
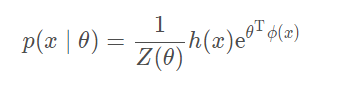
最大熵模型
设随机变量
X 的概率分布为
P ( X ) ,熵可表示为:
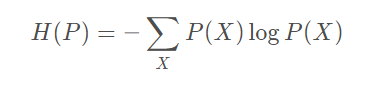
在建立一个概率模型时,往往会伴随一些约束,有时,这些约束的存在并不能得到一个唯一的模型,满足这些条件的模型有很多种,这些模型在约束上的表现基本一致的,而在没有约束的子空间上则表现得不尽相同,那么
根据最大熵的思想,没有约束的子空间应该拥有均等的概率,这样就能确定一个唯一的概率分布。
因此
最大熵原理为:在满足已知条件的情况下,选取熵最大的模型。而决策树的划分是不断降低实例所属类的不确定性,最终给实例一个合适的分类,是不确定性不断减小的过程,所以选择熵最小的划分。
通常我们希望模型能学习到数据中的分布特性,因此我们可以建立一个约束:
模型分布的特征期望和训练样本分布的特征期望相等。其中模型分布的特征期望和训练样本的特征期望可分别表示为:
- 模型分布的特征期望,特征f ( x , y ) 关于模型要建立的概率分布p ( y ∣ x )的特征期望为:
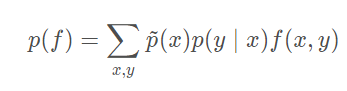
- 训练样本分布的特征期望,特征f ( x , y ) 关于训练样本分布p ~ ( x , y ) 的特征期望为:
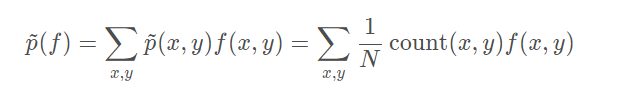 y)
y)
这样我们就找到一个约束条件:
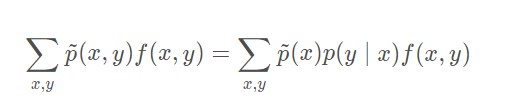
于此同时希望模型的概率分布能最大化熵
H ( p ) :
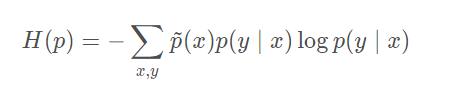
此时问题又变成了一个规划问题,其目标函数和约束项可表示为:
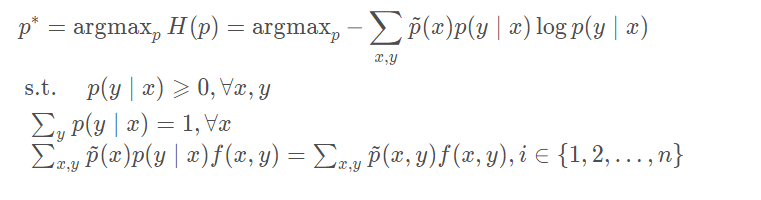
那怎么求
p 呢?采用拉格朗日乘子法,得到拉格朗日函数
ξ ( p , Λ , γ ):
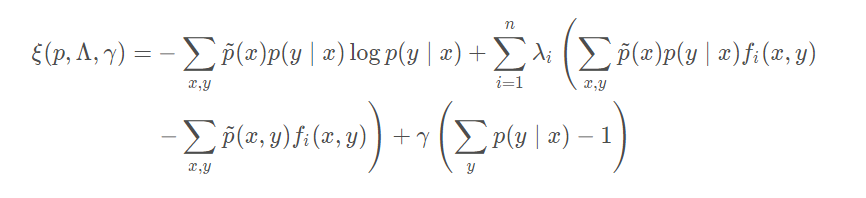
其中
Λ 表示乘子
λ 1 , ⋯ , λ n 的集合。假设
Λ 和
γ 不变,对
p 求导,可以得到:
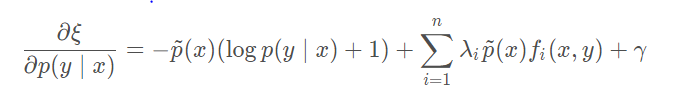
令导数为
0,可以得到
p 的极值:

整理得到:
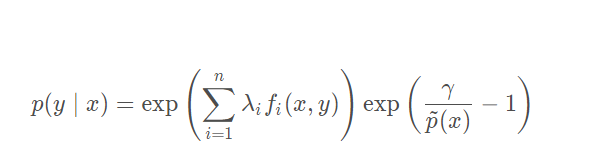
再次使用之前关于概率总和为
1的约束
∑ y p ( y ∣ x ) = 1 , ∀ x ∀x,代入求得:
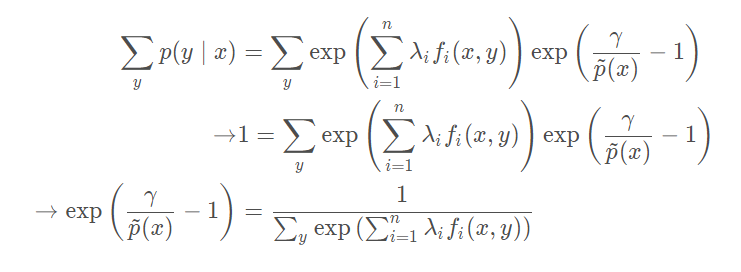
此时
p ( y ∣ x ) 可表示为:
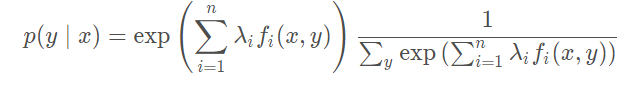
令
Z ( x ) 为:
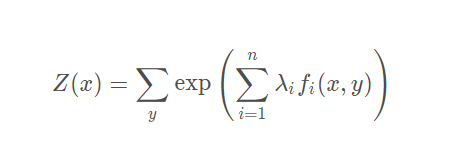
模型最优解为:
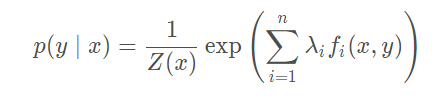
经过拉格朗日乘子法计算,变量由模型
p pp变成了乘子
λ,此时的乘子
λ 更像是每一个特征的权重项,为每个特征乘一个权重判断数据所属的
y 的概率值。
最大似然求解
那如何来求取参数
λ呢?采用最大似然法求解,模型展开为:
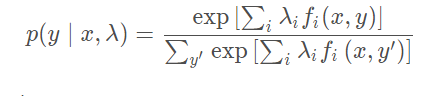
最大化对数似然
log p ( y ∣ x , λ ) ,可以得到:
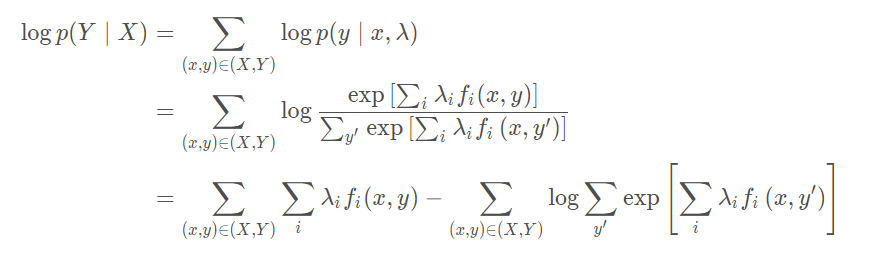
对公式进行求导,可以得到:
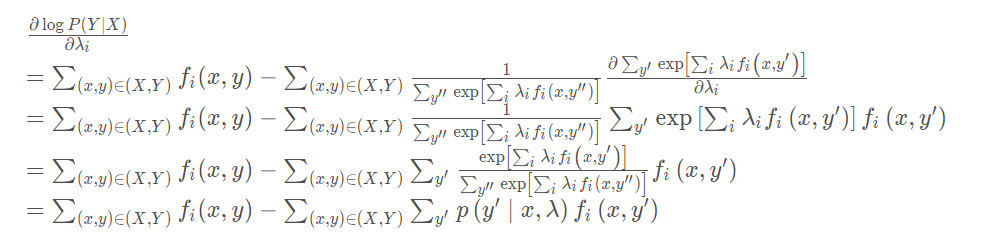
可以看出,
最大似然的梯度等于训练数据分布的特征期望与模型的特征期望的差。当梯度为0时,刚好满足约束条件:
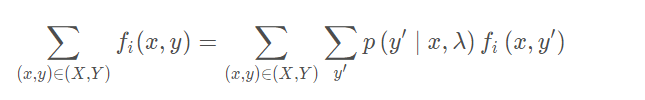
所以可以通过梯度下降法,不断迭代更新参数
λ 。
最大熵似然法
上文已经求出了最大熵模型的目标梯度。令
X 的数量为
d i m x ,
Y 的数量为
d i m y ,于是我们可以定义
d i m x × d i m y 个特征,每一个特征可以指示一组数据是否存在:

模型拥有
d i m x × d i m y 个参数
λ i , j ,每一个参数表示对应特征的权重。如果一个样本拥有
N 个特征,那么我们可以得到某个样本
x 关于结果
y i 的概率:
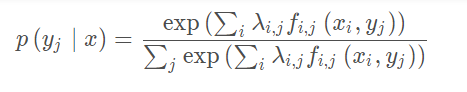
知道了这个概率,就能计算出一个样本对所有特征的累积量,其中每一个特征累积量为:
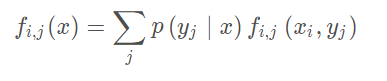
也就可以求出一批样本对所有特征的累积量,其中每一个特征累积量为:
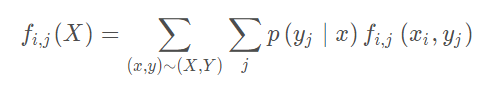
完整算法如下所示:

参考





评论(0)
您还未登录,请登录后发表或查看评论