

[toc]目录
一、直接法和光流
1.1 光流
1.2 直接法
二、后端
三、BA和图优化
一、直接法和光流
特征点VO做法:
- 在图像中提取特征点并计算特征描述,非常耗时,~10+ms in ORB
- 在不同图像中寻找特征匹配,非常耗时
in brute force matching
- 利用匹配点信息计算相机位姿,比较快<1ms
那么不使用特征匹配计算VO?
- 通过其他方式寻找配对点,光流
- 无配对点,直接法
1.1 光流
一般分为稀疏光流和稠密光流:本质上是估计像素在不同时刻图像中的运动。
- 稀疏以Lucas-Kanade(LK)光流为代表
- 稠密以Horn-Schunck(HS)光流为代表
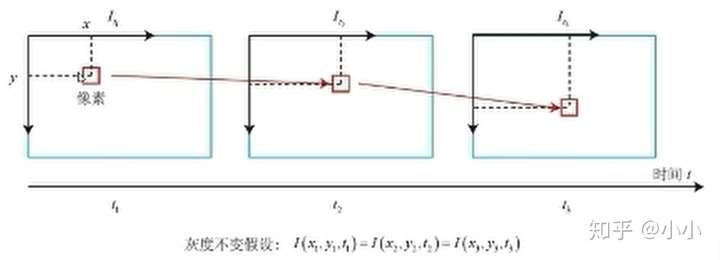
- 设
时刻位于
处像素点的灰度值为
- 在
时刻,该像素运动到了
,希望计算运动
- 灰度不变假设:
这里需要注意的是灰度不变是一种理想的假设,实际中由于高光/阴影、材质、曝光等不同,很可能不成立。
- 对
- 由于灰度不变,所以
- 进一步,有:
- 左侧是x方向和y方向梯度,右侧是随时间变化,希望求解
但是这个式子是一个二元一次线性方程,欠定。因此需要额外引入约束,假设一个窗口(WxW)内光度不变,通过超定最小二乘求得运动 。
注意:其实可以看作是最小像素误差的非线性优化,每次使用Taylor一阶近似,在距离优化点较远时效果不佳,往往需要迭代多次,运动较大时需要使用金字塔,可用于跟踪图像中稀疏关键点的运动轨迹。
1.2 直接法
由于光流仅仅估计了像素间的平移,但没有用到相机本身的几何机构,没有考虑到相机的旋转和图像的缩放,所以就有了直接法。
推导过程:
- 假设有两个帧,运动未知,但有初始估计
,第一帧上的
点,投影为
- 按照初始估计,
此处省略证明1w字。。。。。
直接法的直观解释:
- 像素灰度引导这优化的方向,要使得优化成立,则必须保证从初始估计到最优估计中间梯度下降,这很容易受到图像非凸性的影响。
二、后端
本质上是一个状态估计问题:从带有噪声的数据中估计内在状态Estimated the inner state from noisy data。
- 渐进式Inncremental
- 保持当前状态的估计,在加入新信息时,更新已有的估计(滤波)
- 批量式Batch
- 给定一定规模的数据,计算该数据下的最优估计(优化)
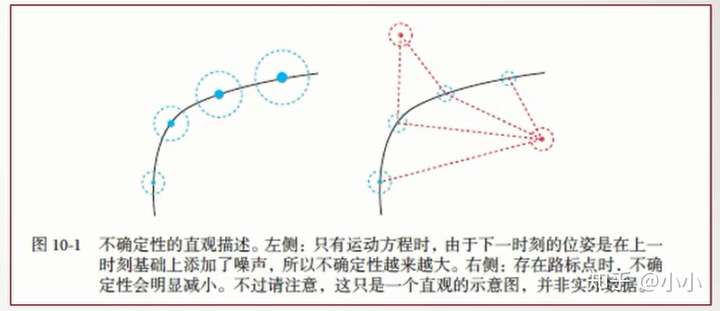
举个例子:
- 当蒙着眼睛走路:一开始还知道自己在哪,能粗略第估计每步的距离,不确定性随时间累计,导致自身的位置不确定性越来越大
- 某个时刻睁开眼睛时,能够观测到周围,尽管也有不确定性,但比估计步长小很多,能够将不确定性保持在一定范围内。
2.1 EKF(扩展卡尔曼滤波)滤波器形式后端
- 数学描述:
- 符号定义,
时间内,机器人的位姿为
到
,同时有路标
- 运动和观测方程记为:
需要注意:运动和观测都会收到噪声影响;另外也可以没有运动方程(纯视觉SLAM)
- 用随机变量表示状态,估计其概率分布
- k时刻所有带估计的量组成k时刻状态:
- k时刻观测统一记成:
- 根据过去0时刻到k时刻的数据,估计当前的状态:
- Bayes展开:
前面P(z_k|x_k)是似然,后面
是先验。
- 先验部分按条件概率展开:
- 分歧:
- 可以假设k时刻状态只和k-1时刻有关,也即是假设了一阶马尔科夫性
- 或者假设k时刻状态与先前所有时刻均有关,不假设马尔科夫性
如果假设一阶马尔科夫性:
于是,可以从k-1时刻的状态分布递推至k时刻的分布。
如果在线性模型、高斯状态分布下,可得到卡尔曼滤波器。
推导过程:略!
EKF的优点:
- 适用各种传感器形式,易于做多传感器融合
EKF缺点:
- 一阶马尔可夫性过于简单
- 可能会发散,要求数据不能有outliner
- 线性化误差
- 需要存储所有状态量的均值和方差,平方增长
三、BA和图优化
BA事实上是属于批量式的优化方法,给定多个相机位姿和观测数据,计算最优的状态估计。定义每个运动/观测方程的误差,并从初始估计开始寻找梯度下降。
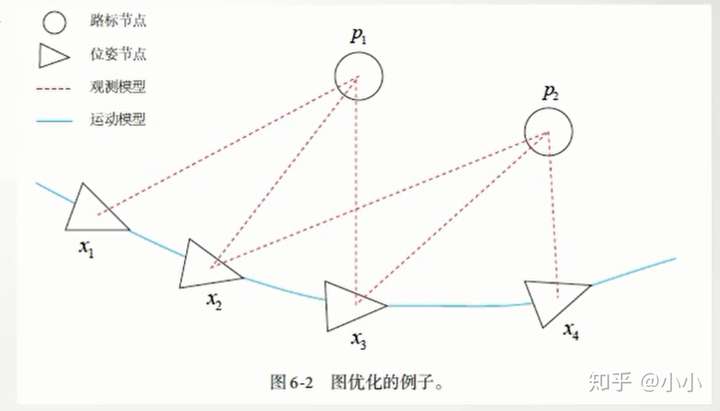
剩下的根本看不懂!!!!!!!!
就这样吧~为了应付一次presentation!
继续加油~!



评论(0)
您还未登录,请登录后发表或查看评论