

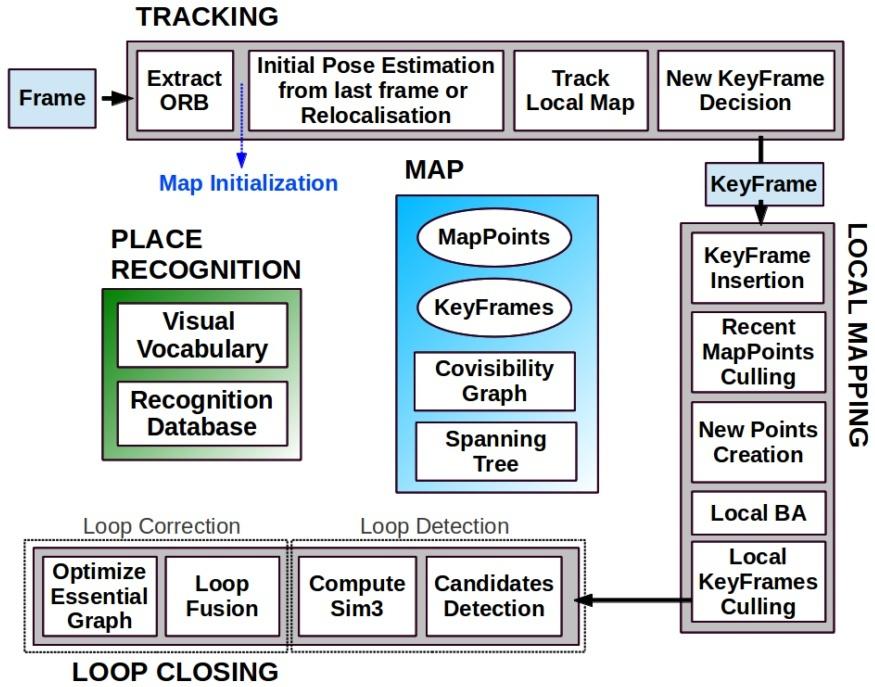
Frame是帧,也就是对应一帧图像,可以是单目、双目、RGBD,所以该类所包含的操作就是slam中以帧为单位进行的处理,主要包括以下方面:
1)读写该帧对应的相机位姿
2)处理帧和特征点之间的关系,包括判断特征点是否在视野内、获取该帧一定区域内的特征点、特征点校正等
3)恢复深度,如果有RGBD就直接读取深度值,如果有双目,就用SAD进行深度恢复
这些功能对应的函数如下图所示
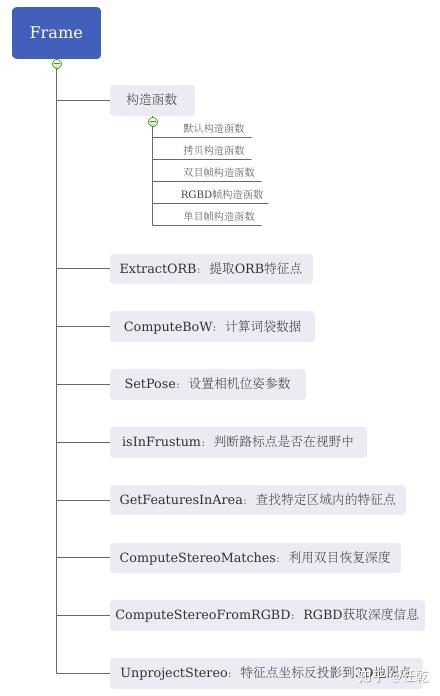
下面逐个解释这些函数:
1)构造函数
重点解释对应三种相机模型的三个构造函数,构造函数的主要功能类似,就是提取并校正特征,然后把特征点划分到网格中,这样做是为了让特征点在图像中分布得更均匀。
另外,还有深度问题,双目使用SAD去恢复深度,RGBD相机自身有深度值,而单目无法获得深度,所以相应变量直接赋值为-1,这些都在构造函数中完成。
- 双目相机
Frame::Frame(
const cv::Mat &imLeft, //左目图像
const cv::Mat &imRight, //右目图像
const double &timeStamp, //时间戳
ORBextractor* extractorLeft, //左目特征提取
ORBextractor* extractorRight, //右目特征提取
ORBVocabulary* voc, //词袋数据
cv::Mat &K, //相机内参
cv::Mat &distCoef, //图像校正参数
const float &bf, // bf=双目基线 * fx
const float &thDepth) //这是深度值的阈值,按照特征点深度值大于或小于这个值,把他们分为close和far两类
Frame::Frame(const cv::Mat &imLeft, const cv::Mat &imRight, const double &timeStamp, ORBextractor* extractorLeft, ORBextractor* extractorRight, ORBVocabulary* voc, cv::Mat &K, cv::Mat &distCoef, const float &bf, const float &thDepth)
:mpORBvocabulary(voc),mpORBextractorLeft(extractorLeft),mpORBextractorRight(extractorRight), mTimeStamp(timeStamp), mK(K.clone()),mDistCoef(distCoef.clone()), mbf(bf), mThDepth(thDepth),
mpReferenceKF(static_cast<KeyFrame*>(NULL))
{
// Frame ID
mnId=nNextId++;
// Scale Level Info
mnScaleLevels = mpORBextractorLeft->GetLevels();
mfScaleFactor = mpORBextractorLeft->GetScaleFactor();
mfLogScaleFactor = log(mfScaleFactor);
mvScaleFactors = mpORBextractorLeft->GetScaleFactors();
mvInvScaleFactors = mpORBextractorLeft->GetInverseScaleFactors();
mvLevelSigma2 = mpORBextractorLeft->GetScaleSigmaSquares();
mvInvLevelSigma2 = mpORBextractorLeft->GetInverseScaleSigmaSquares();
// ORB extraction
// 同时对左右目提特征
thread threadLeft(&Frame::ExtractORB,this,0,imLeft);
thread threadRight(&Frame::ExtractORB,this,1,imRight);
threadLeft.join();
threadRight.join();
N = mvKeys.size();
//mvKeys存放提取的特征点,如果没有特征点,则退出
if(mvKeys.empty())
return;
// 对特征点进行畸变校正
UndistortKeyPoints();
// 计算双目间的匹配, 匹配成功的特征点会计算其深度
// 深度存放在mvuRight 和 mvDepth 中
ComputeStereoMatches();
// 对应的mappoints
mvpMapPoints = vector<MapPoint*>(N,static_cast<MapPoint*>(NULL));
mvbOutlier = vector<bool>(N,false);
// This is done only for the first Frame (or after a change in the calibration)
//在第一次进入或者标定文件发生变化时调用该函数,重新计算相机相关参数
if(mbInitialComputations)
{
ComputeImageBounds(imLeft);
mfGridElementWidthInv=static_cast<float>(FRAME_GRID_COLS)/(mnMaxX-mnMinX);
mfGridElementHeightInv=static_cast<float>(FRAME_GRID_ROWS)/(mnMaxY-mnMinY);
fx = K.at<float>(0,0);
fy = K.at<float>(1,1);
cx = K.at<float>(0,2);
cy = K.at<float>(1,2);
invfx = 1.0f/fx;
invfy = 1.0f/fy;
mbInitialComputations=false;
}
mb = mbf/fx;
//把特征点划分到网格中,这种的好处是可以设置网格内特征点上限,从而使特征点分布更均匀
AssignFeaturesToGrid();
}
- RGBD相机
Frame::Frame(
const cv::Mat &imGray, //灰度图
const cv::Mat &imDepth, //深度值
const double &timeStamp, //时间戳
ORBextractor* extractor,//ORB特征提取
ORBVocabulary* voc, //词袋数据
cv::Mat &K, //相机内参
cv::Mat &distCoef, //图像校正参数
const float &bf, // bf=双目基线 * fx
const float &thDepth) //这是深度值的阈值,按照特征点深度值大于或小于这个值,把他们分为close 和 far两类
Frame::Frame(const cv::Mat &imGray, const cv::Mat &imDepth, const double &timeStamp, ORBextractor* extractor,ORBVocabulary* voc, cv::Mat &K, cv::Mat &distCoef, const float &bf, const float &thDepth)
:mpORBvocabulary(voc),mpORBextractorLeft(extractor),mpORBextractorRight(static_cast<ORBextractor*>(NULL)),
mTimeStamp(timeStamp), mK(K.clone()),mDistCoef(distCoef.clone()), mbf(bf), mThDepth(thDepth)
{
// Frame ID
mnId=nNextId++;
// Scale Level Info
mnScaleLevels = mpORBextractorLeft->GetLevels();
mfScaleFactor = mpORBextractorLeft->GetScaleFactor();
mfLogScaleFactor = log(mfScaleFactor);
mvScaleFactors = mpORBextractorLeft->GetScaleFactors();
mvInvScaleFactors = mpORBextractorLeft->GetInverseScaleFactors();
mvLevelSigma2 = mpORBextractorLeft->GetScaleSigmaSquares();
mvInvLevelSigma2 = mpORBextractorLeft->GetInverseScaleSigmaSquares();
// ORB extraction
//提取ORB特征点
ExtractORB(0,imGray);
N = mvKeys.size();
if(mvKeys.empty())
return;
// 对特征点进行畸变校正
UndistortKeyPoints();
//根据像素坐标获取深度信息,如果深度存在则保存下来,这里还计算了假想右图的对应特征点的横坐标
ComputeStereoFromRGBD(imDepth);
mvpMapPoints = vector<MapPoint*>(N,static_cast<MapPoint*>(NULL));
mvbOutlier = vector<bool>(N,false);
// This is done only for the first Frame (or after a change in the calibration)
if(mbInitialComputations)
{
ComputeImageBounds(imGray);
mfGridElementWidthInv=static_cast<float>(FRAME_GRID_COLS)/static_cast<float>(mnMaxX-mnMinX);
mfGridElementHeightInv=static_cast<float>(FRAME_GRID_ROWS)/static_cast<float>(mnMaxY-mnMinY);
fx = K.at<float>(0,0);
fy = K.at<float>(1,1);
cx = K.at<float>(0,2);
cy = K.at<float>(1,2);
invfx = 1.0f/fx;
invfy = 1.0f/fy;
mbInitialComputations=false;
}
mb = mbf/fx;
//把特征点划分到网格中,这种的好处是可以设置网格内特征点上限,从而使特征点分布更均匀
AssignFeaturesToGrid();
}
- 单目相机
Frame::Frame(
const cv::Mat &imGray, //灰度图
const double &timeStamp, //时间戳
ORBextractor* extractor,//ORB特征提取
ORBVocabulary* voc, //词袋数据
cv::Mat &K, //相机内参
cv::Mat &distCoef, //图像校正参数
const float &bf, // bf=双目基线 * fx
const float &thDepth)//这是深度值的阈值,按照特征点深度值大于或小于这个值,把他们分为close和far两类
Frame::Frame(const cv::Mat &imGray, const double &timeStamp, ORBextractor* extractor,ORBVocabulary* voc, cv::Mat &K, cv::Mat &distCoef, const float &bf, const float &thDepth)
:mpORBvocabulary(voc),mpORBextractorLeft(extractor),mpORBextractorRight(static_cast<ORBextractor*>(NULL)),
mTimeStamp(timeStamp), mK(K.clone()),mDistCoef(distCoef.clone()), mbf(bf), mThDepth(thDepth)
{
// Frame ID
mnId=nNextId++;
// Scale Level Info
mnScaleLevels = mpORBextractorLeft->GetLevels();
mfScaleFactor = mpORBextractorLeft->GetScaleFactor();
mfLogScaleFactor = log(mfScaleFactor);
mvScaleFactors = mpORBextractorLeft->GetScaleFactors();
mvInvScaleFactors = mpORBextractorLeft->GetInverseScaleFactors();
mvLevelSigma2 = mpORBextractorLeft->GetScaleSigmaSquares();
mvInvLevelSigma2 = mpORBextractorLeft->GetInverseScaleSigmaSquares();
// ORB extraction
ExtractORB(0,imGray);
N = mvKeys.size();
if(mvKeys.empty())
return;
UndistortKeyPoints();
// Set no stereo information
//没有右目,所以全都赋值为-1
mvuRight = vector<float>(N,-1);
mvDepth = vector<float>(N,-1);
mvpMapPoints = vector<MapPoint*>(N,static_cast<MapPoint*>(NULL));
mvbOutlier = vector<bool>(N,false);
// This is done only for the first Frame (or after a change in the calibration)
if(mbInitialComputations)
{
ComputeImageBounds(imGray);
mfGridElementWidthInv=static_cast<float>(FRAME_GRID_COLS)/static_cast<float>(mnMaxX-mnMinX);
mfGridElementHeightInv=static_cast<float>(FRAME_GRID_ROWS)/static_cast<float>(mnMaxY-mnMinY);
fx = K.at<float>(0,0);
fy = K.at<float>(1,1);
cx = K.at<float>(0,2);
cy = K.at<float>(1,2);
invfx = 1.0f/fx;
invfy = 1.0f/fy;
mbInitialComputations=false;
}
mb = mbf/fx;
//把特征点划分到网格中,这种的好处是可以设置网格内特征点上限,从而使特征点分布更均匀
AssignFeaturesToGrid();
}
2)ExtractORB:提取特征点
这个函数就是把opencv自带的ORB提取功能多封装了一层,增加了一个flag,这个flag决定提取的是左目还是右目,从而调用不同的特征提取器。
void Frame::ExtractORB(int flag, const cv::Mat &im)
{
if(flag==0)
(*mpORBextractorLeft)(im,cv::Mat(),mvKeys,mDescriptors);
else
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}3)ComputeBoW:计算词袋数据
如果没有传入已有的词袋数据,则就用当前的描述子重新计算生成词袋数据
void Frame::ComputeBoW()
{
if(mBowVec.empty())
{
vector<cv::Mat> vCurrentDesc = Converter::toDescriptorVector(mDescriptors);
mpORBvocabulary->transform(vCurrentDesc,mBowVec,mFeatVec,4);
}
}4)SetPose:设置相机外参
设置相机外参,并计算光心位置
void Frame::SetPose(cv::Mat Tcw)
{
mTcw = Tcw.clone();
UpdatePoseMatrices();
}
void Frame::UpdatePoseMatrices()
{
mRcw = mTcw.rowRange(0,3).colRange(0,3);
mRwc = mRcw.t();
mtcw = mTcw.rowRange(0,3).col(3);
mOw = -mRcw.t()*mtcw;//计算光心三维坐标
}5)isInFrustum:判断一个MapPoint是否在当前帧视野中
先计算MapPoint在相机坐标系下的坐标,用该点和光心的连线即可知道它在相机的哪个视角范围内(即该连线和相机正前方的夹角),如果这个角度大于设定值,那么就认为该点不在视野内,反之则在,在的时候就计算该MapPoint在该帧图像上的坐标,以便跟踪时使用。
bool Frame::isInFrustum(MapPoint *pMP, float viewingCosLimit)
{
pMP->mbTrackInView = false;
// 3D in absolute coordinates
cv::Mat P = pMP->GetWorldPos();
// 3D in camera coordinates
// 3D点P在相机坐标系下的坐标
const cv::Mat Pc = mRcw*P+mtcw;
const float &PcX = Pc.at<float>(0);
const float &PcY= Pc.at<float>(1);
const float &PcZ = Pc.at<float>(2);
// Check positive depth
if(PcZ<0.0f)
return false;
// Project in image and check it is not outside
// 将MapPoint投影到当前帧
const float invz = 1.0f/PcZ;
const float u=fx*PcX*invz+cx;
const float v=fy*PcY*invz+cy;
//判断投影后的坐标是否在图像内
if(u<mnMinX || u>mnMaxX)
return false;
if(v<mnMinY || v>mnMaxY)
return false;
// Check distance is in the scale invariance region of the MapPoint
// 计算MapPoint到相机中心的距离, 并判断是否在尺度变化的距离内
// 每一个地图点都是对应于若干尺度的金字塔提取出来的,具有一定的有效深度
const float maxDistance = pMP->GetMaxDistanceInvariance();
const float minDistance = pMP->GetMinDistanceInvariance();
// 世界坐标系下,相机到3D点P的向量, 向量方向由相机指向3D点P
const cv::Mat PO = P-mOw;
const float dist = cv::norm(PO);
if(dist<minDistance || dist>maxDistance)
return false;
// Check viewing angle
// 计算当前视角和平均视角夹角的余弦值, 若小于cos(60), 即夹角大于60度则返回
// 每一个地图都有其平均视角,是从能够观测到地图点的帧位姿中计算出
cv::Mat Pn = pMP->GetNormal();
const float viewCos = PO.dot(Pn)/dist;
if(viewCos<viewingCosLimit)
return false;
// Predict scale in the image
// 根据深度预测尺度(对应特征点在一层)
const int nPredictedLevel = pMP->PredictScale(dist,this);
// Data used by the tracking
// 如果在视野范围内,在tracking中会被用到,此处要把用到的量赋值
pMP->mbTrackInView = true;//标志位置为true,在函数开头默认置为false
pMP->mTrackProjX = u;
pMP->mTrackProjXR = u - mbf*invz;//该3D点投影到双目右侧相机上的横坐标
pMP->mTrackProjY = v;
pMP->mnTrackScaleLevel= nPredictedLevel;
pMP->mTrackViewCos = viewCos;
return true;
}
6)GetFeaturesInArea:获得特定区域内的坐标点
其作用是找到在 以x, y为中心,边长为2r的方形内且在[minLevel, maxLevel]的特征点
vector<size_t> Frame::GetFeaturesInArea(const float &x, const float &y, const float &r, const int minLevel, const int maxLevel) const
{
vector<size_t> vIndices;
vIndices.reserve(N);
//接下来计算方形的四边在哪在mGrid中的行数和列数
//nMinCellX是方形左边在mGrid中的列数,如果它比mGrid的列数大,说明方形内肯定没有特征点,于是返回
const int nMinCellX = max(0,(int)floor((x-mnMinX-r)*mfGridElementWidthInv));
if(nMinCellX>=FRAME_GRID_COLS)
return vIndices;
const int nMaxCellX = min((int)FRAME_GRID_COLS-1,(int)ceil((x-mnMinX+r)*mfGridElementWidthInv));
if(nMaxCellX<0)
return vIndices;
const int nMinCellY = max(0,(int)floor((y-mnMinY-r)*mfGridElementHeightInv));
if(nMinCellY>=FRAME_GRID_ROWS)
return vIndices;
const int nMaxCellY = min((int)FRAME_GRID_ROWS-1,(int)ceil((y-mnMinY+r)*mfGridElementHeightInv));
if(nMaxCellY<0)
return vIndices;
const bool bCheckLevels = (minLevel>0) || (maxLevel>=0);
for(int ix = nMinCellX; ix<=nMaxCellX; ix++)
{
for(int iy = nMinCellY; iy<=nMaxCellY; iy++)
{
const vector<size_t> vCell = mGrid[ix][iy];
if(vCell.empty())
continue;
for(size_t j=0, jend=vCell.size(); j<jend; j++)
{
const cv::KeyPoint &kpUn = mvKeysUn[vCell[j]];
if(bCheckLevels)
{
if(kpUn.octave<minLevel)
continue;
if(maxLevel>=0)
if(kpUn.octave>maxLevel)
continue;
}
const float distx = kpUn.pt.x-x;
const float disty = kpUn.pt.y-y;
//把区域内所有特征点放入容器中返回
if(fabs(distx)<r && fabs(disty)<r)
vIndices.push_back(vCell[j]);
}
}
}
return vIndices;
}
7)ComputeStereoMatches:从双目中恢复深度
其作用是为左图的每一个特征点在右图中找到匹配点,根据基线(有冗余范围)上描述子距离找到匹配,再进行SAD精确定位,最后对所有SAD的值进行排序, 剔除SAD值较大的匹配对,然后利用抛物线拟合得到亚像素精度的匹配,匹配成功后会更新 mvuRight 和 mvDepth
void Frame::ComputeStereoMatches()
{
mvuRight = vector<float>(N,-1.0f);
mvDepth = vector<float>(N,-1.0f);
const int thOrbDist = (ORBmatcher::TH_HIGH+ORBmatcher::TH_LOW)/2;
const int nRows = mpORBextractorLeft->mvImagePyramid[0].rows;
//Assign keypoints to row table
// 步骤1:建立特征点搜索范围对应表,一个特征点在一个带状区域内搜索匹配特征点
// 匹配搜索的时候,不仅仅是在一条横线上搜索,而是在一条横向搜索带上搜索,简而言之,原本每个特征点的纵坐标为1,这里把特征点体积放大,纵坐标占好几行
// 例如左目图像某个特征点的纵坐标为20,那么在右侧图像上搜索时是在纵坐标为18到22这条带上搜索,搜索带宽度为正负2,搜索带的宽度和特征点所在金字塔层数有关
// 简单来说,如果纵坐标是20,特征点在图像第20行,那么认为18 19 20 21 22行都有这个特征点
// vRowIndices[18]、vRowIndices[19]、vRowIndices[20]、vRowIndices[21]、vRowIndices[22]都有这个特征点编号
vector<vector<size_t> > vRowIndices(nRows,vector<size_t>());
for(int i=0; i<nRows; i++)
vRowIndices[i].reserve(200);
const int Nr = mvKeysRight.size();
//把所有特征点对应的y值都设置一个搜索带,然后把这个搜索带内所有的y坐标都和其对应的特征点做关联
for(int iR=0; iR<Nr; iR++)
{
const cv::KeyPoint &kp = mvKeysRight[iR];
const float &kpY = kp.pt.y;
// 计算匹配搜索的纵向宽度,尺度越大(层数越高,距离越近),搜索范围越大
// 如果特征点在金字塔第一层,则搜索范围为:正负2
// 尺度越大其位置不确定性越高,所以其搜索半径越大
const float r = 2.0f*mvScaleFactors[mvKeysRight[iR].octave];
const int maxr = ceil(kpY+r);
const int minr = floor(kpY-r);
for(int yi=minr;yi<=maxr;yi++)
vRowIndices[yi].push_back(iR);
}
// Set limits for search
const float minZ = mb;// NOTE bug mb没有初始化,mb的赋值在构造函数中放在ComputeStereoMatches函数的后面
const float minD = 0;// 最小视差, 设置为0即可
const float maxD = mbf/minZ;// 最大视差, 对应最小深度 mbf/minZ = mbf/mb = mbf/(mbf/fx) = fx
// For each left keypoint search a match in the right image
vector<pair<int, int> > vDistIdx;
vDistIdx.reserve(N);
// 步骤2:对左目相机每个特征点,通过描述子在右目带状搜索区域找到匹配点, 再通过SAD做亚像素匹配
// 注意:这里是校正前的mvKeys,而不是校正后的mvKeysUn
// KeyFrame::UnprojectStereo和Frame::UnprojectStereo函数中不一致
for(int iL=0; iL<N; iL++)
{
const cv::KeyPoint &kpL = mvKeys[iL];
const int &levelL = kpL.octave;
const float &vL = kpL.pt.y;
const float &uL = kpL.pt.x;
// 可能的匹配点
const vector<size_t> &vCandidates = vRowIndices[vL];
if(vCandidates.empty())
continue;
const float minU = uL-maxD;// 最小匹配范围
const float maxU = uL-minD;// 最大匹配范围
if(maxU<0)
continue;
int bestDist = ORBmatcher::TH_HIGH;
size_t bestIdxR = 0;
// 每个特征点描述子占一行,建立一个指针指向iL特征点对应的描述子
const cv::Mat &dL = mDescriptors.row(iL);
// Compare descriptor to right keypoints
// 步骤2.1:遍历右目所有可能的匹配点,找出最佳匹配点(描述子距离最小)
for(size_t iC=0; iC<vCandidates.size(); iC++)
{
const size_t iR = vCandidates[iC];
const cv::KeyPoint &kpR = mvKeysRight[iR];
// 仅对近邻尺度的特征点进行匹配
if(kpR.octave<levelL-1 || kpR.octave>levelL+1)
continue;
const float &uR = kpR.pt.x;
//此处找出的bestIdxR就是最匹配的特征点,bestDist是该特征点对应的描述向量距离
if(uR>=minU && uR<=maxU)
{
const cv::Mat &dR = mDescriptorsRight.row(iR);
const int dist = ORBmatcher::DescriptorDistance(dL,dR);
if(dist<bestDist)
{
bestDist = dist;
bestIdxR = iR;
}
}
}
// Subpixel match by correlation
// 步骤2.2:通过SAD匹配提高像素匹配修正量bestincR
if(bestDist<thOrbDist)
{
// coordinates in image pyramid at keypoint scale
// kpL.pt.x对应金字塔最底层坐标,将最佳匹配的特征点对尺度变换到尺度对应层 (scaleduL, scaledvL) (scaleduR0, )
const float uR0 = mvKeysRight[bestIdxR].pt.x;
const float scaleFactor = mvInvScaleFactors[kpL.octave];
const float scaleduL = round(kpL.pt.x*scaleFactor);
const float scaledvL = round(kpL.pt.y*scaleFactor);
const float scaleduR0 = round(uR0*scaleFactor);
// sliding window search
const int w = 5;// 滑动窗口的大小11*11 注意该窗口取自resize后的图像
cv::Mat IL = mpORBextractorLeft->mvImagePyramid[kpL.octave].rowRange(scaledvL-w,scaledvL+w+1).colRange(scaleduL-w,scaleduL+w+1);
IL.convertTo(IL,CV_32F);
IL = IL - IL.at<float>(w,w) *cv::Mat::ones(IL.rows,IL.cols,CV_32F);
int bestDist = INT_MAX;
int bestincR = 0;
const int L = 5;
vector<float> vDists;
vDists.resize(2*L+1);
// 滑动窗口的滑动范围为(-L, L),提前判断滑动窗口滑动过程中是否会越界
const float iniu = scaleduR0+L-w;
const float endu = scaleduR0+L+w+1;
if(iniu<0 || endu >= mpORBextractorRight->mvImagePyramid[kpL.octave].cols)
continue;
for(int incR=-L; incR<=+L; incR++)
{
// 横向滑动窗口
cv::Mat IR = mpORBextractorRight->mvImagePyramid[kpL.octave].rowRange(scaledvL-w,scaledvL+w+1).colRange(scaleduR0+incR-w,scaleduR0+incR+w+1);
IR.convertTo(IR,CV_32F);
//窗口中的每个元素减去正中心的那个元素,简单归一化,减小光照强度影响
IR = IR - IR.at<float>(w,w) *cv::Mat::ones(IR.rows,IR.cols,CV_32F);
float dist = cv::norm(IL,IR,cv::NORM_L1);// 一范数,计算差的绝对值
if(dist<bestDist)
{
bestDist = dist;// SAD匹配目前最小匹配偏差
bestincR = incR;// SAD匹配目前最佳的修正量
}
vDists[L+incR] = dist;
}
// 整个滑动窗口过程中,SAD最小值不是以抛物线形式出现,SAD匹配失败,同时放弃求该特征点的深度
if(bestincR==-L || bestincR==L)
continue;
// Sub-pixel match (Parabola fitting)
// 步骤2.3:做抛物线拟合找谷底得到亚像素匹配deltaR
// (bestincR,dist) (bestincR-1,dist) (bestincR+1,dist)三个点拟合出抛物线
// bestincR+deltaR就是抛物线谷底的位置,相对SAD匹配出的最小值bestincR的修正量为deltaR
const float dist1 = vDists[L+bestincR-1];
const float dist2 = vDists[L+bestincR];
const float dist3 = vDists[L+bestincR+1];
const float deltaR = (dist1-dist3)/(2.0f*(dist1+dist3-2.0f*dist2));
// 抛物线拟合得到的修正量不能超过一个像素,否则放弃求该特征点的深度
if(deltaR<-1 || deltaR>1)
continue;
// Re-scaled coordinate
// 通过描述子匹配得到匹配点位置为scaleduR0
// 通过SAD匹配找到修正量bestincR
// 通过抛物线拟合找到亚像素修正量deltaR
float bestuR = mvScaleFactors[kpL.octave]*((float)scaleduR0+(float)bestincR+deltaR);
// 这里是disparity,根据它算出depth
float disparity = (uL-bestuR);
// 最后判断视差是否在范围内
if(disparity>=minD && disparity<maxD)
{
if(disparity<=0)
{
disparity=0.01;
bestuR = uL-0.01;
}
// depth 是在这里计算的
// depth=baseline*fx/disparity
mvDepth[iL]=mbf/disparity;// 深度
mvuRight[iL] = bestuR; // 匹配对在右图的横坐标
vDistIdx.push_back(pair<int,int>(bestDist,iL));// 该特征点SAD匹配最小匹配偏差
}
}
}
// 步骤3:剔除SAD匹配偏差较大的匹配特征点
// 前面SAD匹配只判断滑动窗口中是否有局部最小值,这里通过对比剔除SAD匹配偏差比较大的特征点的深度
sort(vDistIdx.begin(),vDistIdx.end());// 根据所有匹配对的SAD偏差进行排序, 距离由小到大
const float median = vDistIdx[vDistIdx.size()/2].first;
const float thDist = 1.5f*1.4f*median;// 计算自适应距离, 大于此距离的匹配对将剔除
for(int i=vDistIdx.size()-1;i>=0;i--)
{
if(vDistIdx[i].first<thDist)
break;
else
{
mvuRight[vDistIdx[i].second]=-1;
mvDepth[vDistIdx[i].second]=-1;
}
}
}8)ComputeStereoFromRGBD:从RGBD相机中获得深度
根据像素坐标获取深度信息,如果深度存在则保存下来,这里还计算了假想右图的对应特征点的横坐标
void Frame::ComputeStereoFromRGBD(const cv::Mat &imDepth)
{
mvuRight = vector<float>(N,-1);
mvDepth = vector<float>(N,-1);
for(int i=0; i<N; i++)
{
const cv::KeyPoint &kp = mvKeys[i];
const cv::KeyPoint &kpU = mvKeysUn[i];
const float &v = kp.pt.y;
const float &u = kp.pt.x;
const float d = imDepth.at<float>(v,u);
if(d>0)
{
mvDepth[i] = d;
mvuRight[i] = kpU.pt.x-mbf/d;
}
}
}
9)UnprojectStereo:计算特征点在三维空间的坐标
其作用是将特征点坐标反投影到3D地图点(世界坐标),在已知深度的情况下,则可确定二维像素点对应的尺度,最后获得3D中点坐标
cv::Mat Frame::UnprojectStereo(const int &i)
{
const float z = mvDepth[i];
if(z>0)
{
const float u = mvKeysUn[i].pt.x;
const float v = mvKeysUn[i].pt.y;
const float x = (u-cx)*z*invfx;
const float y = (v-cy)*z*invfy;
cv::Mat x3Dc = (cv::Mat_<float>(3,1) << x, y, z);
return mRwc*x3Dc+mOw;
}
else
return cv::Mat();
}


评论(0)
您还未登录,请登录后发表或查看评论