

论文题目:PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation
一、整体介绍
这篇论文所提出的网络模型都很简洁,作者的文笔也很清晰,所以我们就不废话了,都在图里了
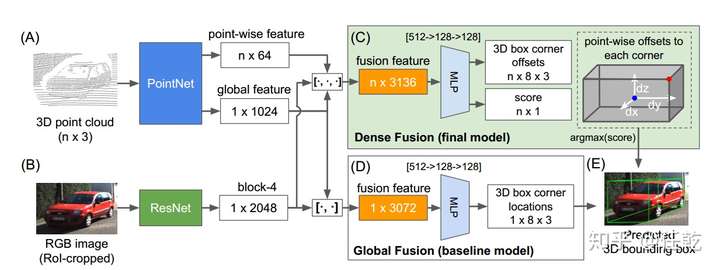
图中A、B、C、D、E都标好了,我们逐个讲解就是了
A)使用PointNet提取点云的特征,包括全局特征和单个点的特征
B)使用ResNet提取图像特征
C)全局特征和单个点特征一起融合,预测边界框,该方法在文章中被称为“dense”
D)只融合全局特征,预测边界框,该方法在文章中被称为“global”
E)就是边界框喽
有的细心的读者会问,为啥要有C和D两个结构嘞?
其实实际使用中,作者只用了C这一个结构,D的存在只是为了和它做对比,通过对比实验效果证明在网络中加入单个点的特征会更有效。
二、细节补充
下面补充一些细节吧
- 对PointNet的改进
主要包括两方面:
1)去掉了batch normalization层,作者认为能够边界框的预测精度
2)把T-net改成了旋转矩阵Rc
2. 对比了两种损失函数
这两种损失函数是:
1)有监督的损失函数
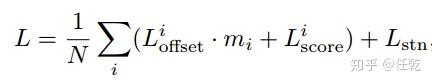
2)无监督的损失函数
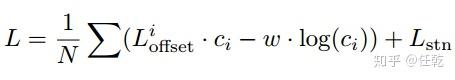
三、实验结果
最后看看实验结果,从论文里我们能够看出,这个作者喜欢在解决一个问题的时候提出多个方法,然后通过实验结果来对比他们的好坏,虽然最后只会选择一个,但是其他方法作为对比放在那里会更有说服力。
下面我们先看看作者都列出了哪些对比选项:
1)final:网络用dense(还记得dense和global吗,不记得就网上翻哦),损失函数用无监督
2)dense:网络用dense,损失函数用有监督
3)dense-no-im:它应该叫denso no image,谜底就在谜面上,就是dense+有监督,但是不输入图像,只用点云
4)global:就是global呀
5)global-no-im:global不加图像
6)rgb-d:这个就有意思了,它把PointNet用一个“generic CNN”替换掉,把输入改成rgb-d的彩色深度图,用来对比
下面就给出实验结果
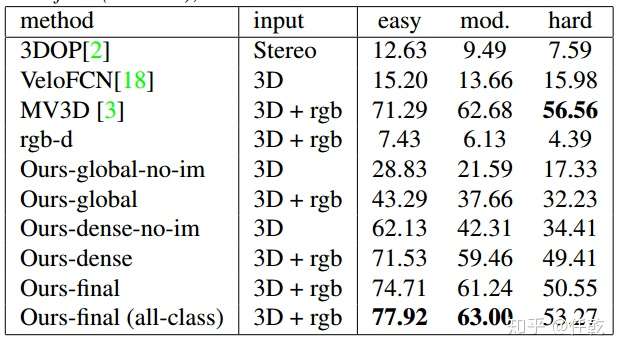
这张表内容太多了,我们得分析一下,然后给出结论才行:
1)global和global-no-im对比,说明图像有用(只在mod和hard中,不清楚easy为啥更差)
2)global和dense对比,说明单点的特征有用
3)dense和final对比,说明无监督损失函数比有监督损失函数好
4)final(all-class)和MV3D对比,各有优劣吧,easy和mod更好,但是hard更差

评论(0)
您还未登录,请登录后发表或查看评论