

0. 简介
激光雷达地图中基于流的全局和度量雷达定位。自主机器人的定位是至关重要的。尽管基于相机和激光雷达的方法已经得到大量研究,但是它们会受到恶劣的光照和天气条件的影响。因此,最近雷达传感器由于其对这种条件固有的鲁棒性而受到关注。在《RaLF: Flow-based Global and Metric Radar Localization in LiDAR Maps》中,我们提出了RaLF,这是一种新型的基于深度神经网络的方法,用于在环境的激光雷达地图中定位雷达扫描,通过联合学习来解决位置识别和度量定位问题。RaLF由雷达和激光雷达特征编码器、生成全局描述子的位置识别头以及预测雷达扫描和地图之间3自由度变换的度量定位头组成。我们通过跨模态度量学习来学习两种模态之间的共享嵌入空间,从而解决位置识别任务。此外,我们通过预测将查询雷达扫描与激光雷达地图对齐的像素级流向量来执行度量定位。我们在多个现实世界驾驶数据集上广泛评估本文方法,并且表明RaLF在位置识别和度量定位方面均达到了最先进的性能。此外,我们证明,与训练期间使用的传感器设置相比,本文方法可以有效地泛化到不同的城市和传感器设置。代码已经在https://ralf.cs.uni-freiburg.de/上开源了。
1. 主要贡献
本文的主要贡献如下:
- 本文提出了一种用于先验激光雷达地图中雷达定位的新型RaLF,其解决了位置识别和度量定位任务;
- 本文提出了通过预测雷达和激光雷达鸟瞰图(BEV)图像之间流场形式的像素级匹配来解决度量定位任务;
- 本文在三个现实世界数据集上评估了RaLF相比于最先进的位置识别和度量定位方法的性能;
- 本文通过在不同的城市评估本文方法,并且使用与训练过程中不同的传感器设置来研究本文方法的泛化能力;
- 本文开源了代码和训练模型。
2. 总括
在本节中,我们描述了我们提出的用于LiDAR地图中的地点识别和度量雷达定位的RaLF。RaLF的概述如图2所示。我们的方法的架构基于RAFT [30],这是一个用于光流估计的最先进的网络。RaLF包括三个主要组件:特征提取、位置识别头和度量定位头。在本节的其余部分,我们详细介绍每个组件和相应的损失函数,然后描述推理过程。
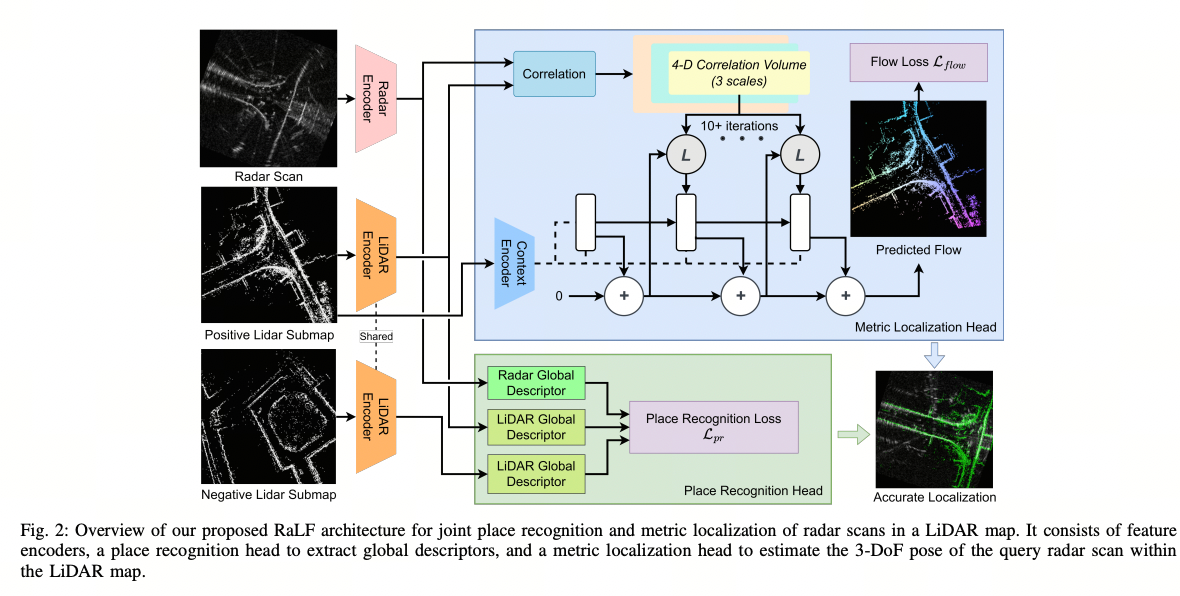
图2:我们提出的RaLF架构用于雷达扫描在LiDAR地图中的联合地点识别和度量定位的概述。它由特征编码器、位置识别头部提取全局描述符和度量定位头部估计查询雷达扫描在LiDAR地图中的3自由度姿态组成。
3. 特征提取
两个编码器的架构,即雷达编码器和LiDAR编码器,基于RAFT [30]的特征编码器,它由一个步长为2的卷积层组成,后面跟着六个残差层,在第二和第四层之后进行下采样。与RAFT的原始特征编码器不同,RaLF为每种模态使用单独的特征提取器,因为雷达和LiDAR数据的性质不同。形式上,给定雷达BEV图像R ∈ \mathbb{R}^{H×W×1}和LiDAR BEV图像L ∈ \mathbb{R}^{H×W×1},两个编码器g_r和g_l在原始分辨率的1/8处提取特征g_r, g_l: \mathbb{R}^{H×W×1} → \mathbb{R}^{H/8×W/8×D}。两个编码器提取的特征在位置识别头和度量定位头之间共享。
4. 位置识别头
地点识别头具有两个目的:首先,它将特征提取器中的特征图聚合成全局描述符。其次,它将雷达和激光雷达数据的特征映射到共享嵌入空间中,其中可以将雷达扫描和激光雷达子地图的全局描述符相互比较。位置识别头的架构是一个由四个卷积层组成的浅层卷积神经网络,特征大小分别为(256,128,128,128)。每个卷积层后面都跟着批归一化和ReLU激活。与特征编码器不同,位置识别头在雷达和激光雷达模态之间是共享的。
为了训练位置识别头,我们使用了众所周知的三元组技术[31],其中选择由(锚点,正样本,负样本)组成的三元组来计算三元组损失。正样本是一个描绘与锚点样本相同地点的BEV图像,而负样本是一个不同地点的BEV图像。通常情况下,这种技术用于比较同一模态的样本三元组,但在我们的情况下,样本可以来自不同的模态。例如,给定一个锚点雷达扫描R^a,一个正样本激光雷达子地图L^p,和一个负样本激光雷达子地图L^n,我们定义三元组损失L^{RLL}_{tr}为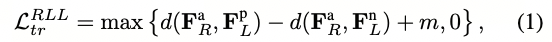
其中F^a_R、F^p_L和F^n_L分别是R^a、L^p和L^n的全局描述符;m是三元组间隔,d(·)是给定的距离函数。L^{RLL}_{tr}的上标表示(anchor, positive, negative)样本的模态,本例中为(radar, LiDAR, LiDAR)。我们将相同的损失应用于所有八种可能的模态组合,得到最终的地点识别损失: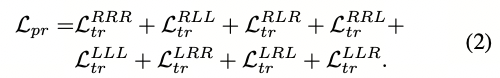
为了选择组成一个批次的三元组,我们首先为每个锚点样本随机抽样一个正样本。我们定义一个样本为锚点样本的正样本,如果它们之间的位置距离小于一个正阈值τ_p。此外,我们从当前网络处理的样本批次中选择最难的负样本,确保其位置与锚点的距离大于一个负阈值τ_n。这种技术被称为在线最难负样本挖掘。
5. 度量定位头
为了对雷达扫描进行与LiDAR地图M的度量定位,我们提出了学习像素级匹配的流向量的方法。这个决策背后的直觉是,雷达BEV图像和在相同位置拍摄的LiDAR BEV图像应该对齐良好,如图2右下部分所示。因此,对于LiDAR BEV图像中的每个像素,我们的度量定位头预测雷达BEV图像中对应的像素。
更正式地说,给定雷达BEV图像R和由位置识别头预测的初始粗略姿态T_{init},我们生成以T_{init}为中心的LiDAR BEV图像L。度量定位头将两个BEV图像R和L作为输入,并预测对齐这两个图像的密集流向图f。流向图f中的每个像素(u, v)包含将像素L(u,v)映射到像素R_{(u+∆u,v+∆v)}的流向量(∆u, ∆v)。我们的度量定位头的架构基于RAFT [30],它首先计算两个编码器提取的特征之间的4-D相关性体积,如第III-A节所述。然后,将相关性体积输入到一个门控循环单元(GRU)中,该GRU迭代地细化估计的流向图。GRU的每个迭代i更新输出一个流更新∆f_i,将其添加到先前的流估计f_{i−1}中以获得更新后的流向图f_i。根据[30],我们使用一个额外的上下文编码器,仅从LiDAR BEV图像中提取特征,并将其额外输入到GRU中。为了生成地面真实流向图f_{GT},我们首先将初始姿态T_{init}中的LiDAR地图点进行变换,并计算它们在相对BEV图像L中的像素位置,如下所示: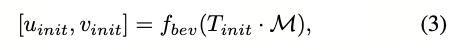
f_{bev}是将3D点云投影到BEV图像的函数。同样地,当使用地面真实姿态T_{GT}变换地图时,我们计算投影的像素位置。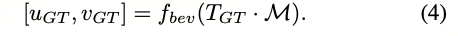
最后,我们通过比较使用初始位姿和真实位姿投影的点来计算地面真实光流图f_{GT}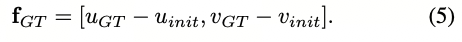
为了训练度量定位模块,我们使用了RAFT [30]中最初提出的损失函数,该函数在GRU的每次迭代中监督预测的光流图f_i
其中γ = 0.8为后续迭代提供指数级增长的权重。由于BEV图像的稀疏性,我们只在L中计算非零像素的损失。RaLF的最终损失函数是在方程(2)和方程(6)中定义的各个损失函数的总和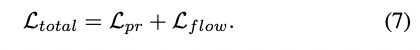

评论(0)
您还未登录,请登录后发表或查看评论