

0. 简介
我们知道激光雷达作为自动驾驶中最为精准的传感器,它可以在绝大多数场景下提供较为精准的定位信息,同时也有很多工作用激光做重定位工作。而《 CVTNet: A Cross-View Transformer Network for Place Recognition Using LiDAR Data》 这个工作就是基于激光雷达的地点识别(LPR)来完成在没有GPS的环境中识别以前行驶过的地点。现有的LPR方法大多采用单一的输入点云表示,没有考虑不同的投影试图,这可能无法充分利用激光雷达传感器的信息。本文提出了一种基于跨视图的Transformer网络,称为CVTNet,用于融合激光雷达数据生成的距离像视图(RIVs)和鸟瞰视图(BEVs)。它使用Intra-Transformer提取视图本身内部的相关性,使用Inter-Transformer提取两个不同视图之间的相关性。在此基础上,本文提出的CVTNet为每个激光帧端到端在线生成一个偏航角不变的全局描述子,并通过当前查询帧与预先构建的数据库之间的描述子匹配来检索以行驶过的位置。相关代码已经在Github上开源了。

图1:RIV和BEV之间的对应关系导致了我们提出的CVTNet使用的对齐特征句子。
1. 主要贡献
文中提出了三个观点,证明该方法能够取得良好的效果
- 利用多视角 LiDAR 数据在室外大规模环境中实现最先进的位置识别和环路闭合检测;
- 基于提出的偏航角不变架构,能够在不同视角下很好地识别位置;
- 实现在线操作,运行时间少于50毫秒,比典型的 LiDAR 帧率更快。所有的观点都得到了我们在多个数据集上的实验评估的支持。
我们提出的方法概述如图2所示。CVTNet由三个模块组成,即多视角多层生成器(MMG)、对齐特征编码器(AFE)和多视角融合模块(MVF)。MMG首先按范围和高度间隔分割区域,分别进行球形和自上而下的投影来生成多层输入数据(参见第2节)。接下来的AFE将多层RIV和BEV作为输入,使用完全卷积编码器生成类似于句子的特征。然后,它应用内部变压器来提取每个视图的压缩特征之间的内部相关性(参见第3节)。最后,增强的特征体积被送入MVF模块。它首先使用内部变压器来融合来自不同视角的对齐特征,然后在单视图和融合特征上应用NetVLAD和多层感知器(MLPs)来生成最终的1-D全局描述符(参见第4节)。最终描述符对偏航角旋转不变(参见第5节)。我们使用三元组损失和重叠标签训练我们的网络,以更好地区分正负例子(参见第6节)。
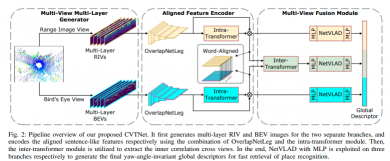
图2:我们提出的CVTNet的管道概述。它首先为两个分离的分支生成多层RIV和BEV图像,并分别使用OverlapNetLeg和内部变压器模块组合编码对齐的类似句子的特征。然后,利用内部变压器模块提取跨视图的内部相关性。最后,分别在三个分支上利用NetVLAD和MLP生成偏航角不变的全局描述符,以便快速检索地点识别。
2. 多视角多层生成器 (重点内容)
从不同的扫描中提取有区别的特征对于LPR方法非常重要。现有的方法使用单个球形或自上而下的投影来获取RIV或BEV会导致数据丢失,从而降低检索性能。为了充分利用LiDAR数据中的所有信息,同时保持快速速度,我们提出使用不同范围/高度的多个投影,并基于空间分割形成多层输入。通过这样做,我们提出的网络学习以不同的范围/高度加权信息,从而提取更具代表性的特征。具体而言,我们提出了多视角多层生成器。对于球坐标系中的RIV,它首先通过预设的范围间隔{s_0,s_1,s_2,s_3,…,s_q}离散化区域,得到分裂空间E^r = {E^r_1,E^r_2,E^r_3,…,E^r_q}。然后,它将不同范围间隔内的激光点应用于球形投影,生成多层范围图像。同样,对于欧几里得坐标中的BEV,它通过高度间隔{t_0,t_1,t_2,t_3,…,t_q}离散空间,得到E^b = {E^b_1,E^b_2,E^b_3,…,E^b_q},并为所有间隔生成多层BEV图像。
一个LiDAR点p_k∈P,p_k=(x_k,y_k,z_k)与相应的RIV R_i中的像素坐标(u^r_k,v^r_k)之间的对应关系可以表示为:

其中r_k = ||p_k||_2∈[s_{i−1}, s_i]是相应点的测距,f = f_{up} + f_{down}是传感器的垂直视场,w和h是生成的范围图像的宽度和高度。 我们通过自上而下的投影将相同的LiDAR点投影到BEV上。同一LiDAR点p_k∈P与相应BEV图像B_j中的像素坐标(u^b_k,v^b_k)之间的对应关系可以表示为:
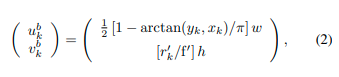
其中r’_k = ||(x_k,y_k)||_2∈[t_{j−1},t_j],f’是最大感知范围。 在这项工作中,我们让RIV和BEV图像具有相同的宽度和高度,以便更好地对齐,从而导致u^r_k = u^b_k。 这导致RIV和BEV图像具有相同索引的列都来自相同的空间扇区,如图1所示。最后,MMG生成多层RIVs \mathbb{R} = {R_i}和多层BEVs \mathbb{B} = {B_j},如图3所示。
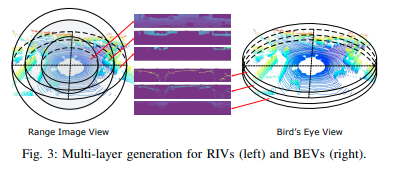
图3:RIVs(左)和BEVs(右)的多层生成。
4. 对齐特征编码器(重点内容)
为了更好地融合LiDAR数据的不同表示,我们的CVTNet利用对齐特征编码器提取每个表示的粗略特征并将它们对齐以便于后续融合。它首先沿着通道维度连接所有RIVs \mathbb{R}和BEVs \mathbb{B},得到大小为q×h×w的R和B。然后,它应用两个具有相同架构的OverlapNetLeg[1],[3]模块将输入压缩成类似句子的特征。OverlapNetLeg是一个完全卷积编码器,仅在垂直维度上压缩RIVs和BEVs而不改变宽度维度,以避免对偏航等变性的离散化误差。然后,每个分支的输出粗略特征通过内部变换器进行增强。我们将增强后的特征表示为A^r_0 = AFE_r(R)表示RIV分支,A^b_0 = AFE_b(B)表示BEV分支,两者都具有c×1×w的大小,其中c是特征通道数。正如我们以前的工作[3]所证明的,RIV分支的特征具有偏航角等变性:
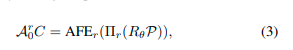
其中Πr(·)是在方程(1)中详细说明的球面投影,C表示通过矩阵右乘的特征列移位,θ是偏航角变化,R_θ是点云P的偏航旋转矩阵。在本文中,我们进一步展示了我们提出的BEV分支也具有偏航角等变性。根据在方程(2)中详细说明的自上而下投影Πb(·),点的偏航旋转对应于BEV上的特定水平移位:
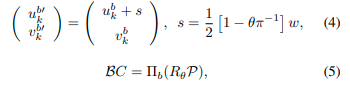
其中C和R_θ是相同的列移位和偏航旋转。由于OverlapNetLeg和内部变换器已被证明具有偏航角等变性[3],因此对于BEV分支,我们也获得了偏航角等变性特征:
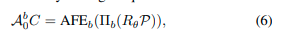
在使用交叉变换器融合不同视图并提取交叉模态相关性之前,将来自不同模态的特征对齐非常重要[35],[36]。为此,我们首先确保两个不同视图的交互变换器的输入在空间上对齐。我们让输入的RIV和BEV图像具有相同的宽度和高度,因此像在III-A节中所澄清的那样,u^r_k = u^b_k。同一激光点投影到两幅图像的同一列,导致一个空间扇区对应于两幅图像的相同列索引。为了保持对齐,我们进一步设计我们的网络结构仅压缩高度维度,并将一个空间扇区的信息维度聚合到两个输出特征的相同列中。我们沿通道维度连接OverlapNetLeg的输出特征和由内部变换器增强的特征。因此,AFE的输出特征A^r_0和A^b_0被设计为在宽度维度上对齐。
5. 多视角融合模块
我们的CVTNet在设计的多视角融合模块中融合多视角特征。如图2所示,它由一个交互变换器和三个NetVLAD-MLP组合[22]组成。它首先使用所提出的交互变换器模块融合来自不同视图的两个分支的特征,如图4所详细说明。在交互变换器模块中,也有两个分支,其中包含l_{th}堆叠的变换器块,通过使用一个视图的查询特征和另一个视图的键和值特征来提取不同视图的相关性。对于RIV分支,我们将l_{th}变换器块的多头自我注意力(MHSA)提取的特征体积表示为A^r_l,变换器的交叉注意机制可以表示为: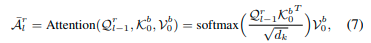
其中Q^r_{l-1}实质上是来自RIV的A^r_{l-1}经过层归一化后的查询分裂,而A^r_0是RIV分支中AFE的输出特征。K^b_0,V^b_0是经过层归一化的A^b_0的键和值分裂,A^b_0是BEV分支中AFE的输出特征。d_k表示分裂的维度。\tilde{A}^r_l然后被馈送到前馈网络(FFN)和层归一化(LN)中,以生成第l个变换器块的注意力增强特征A^r_l,可以表示为:

对于BEV分支,我们对称地进行相同的操作:
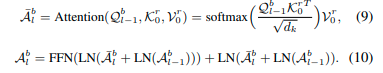
然后我们将A^r_l和最后一个变换器块的A^b_l连接起来,得到中间融合特征A^f_l。
最后,我们的MVF在RIV和BEV特征A^r_0和A^b_0以及交叉融合特征A^f_l上使用NetVLAD-MLPs组合。NetVLAD-MLPs已经广泛用于LPR [16],[29],[4]中生成全局描述符。我们还利用三个NetVLAD-MLPs组合将两个内部变换器和一个交叉视图间变换器的特征压缩成全局描述符[g^r, g^b, g^f]。

6. 偏航角不变性
我们进一步数学证明了CVTNet生成的多视角融合描述符是偏航角不变的,这使得我们的方法对视角变化非常鲁棒。我们在第III-B节中已经证明了对齐特征编码器的输出在公式(3)和(6)中是偏航角等变的。正如[9]所介绍的,NetVLAD是置换不变的,其输入由原始点云的偏航旋转引起的列移可以视为一组沿通道维度的1-D向量的重新排序[3]。因此,RIV和BEV分支中NetVLAD的输出不会受到偏航旋转的影响,全局描述符g_r和g_b是偏航角不变的。接下来,我们证明融合的交叉视图特征g_f也是偏航角不变的。
请注意,A^r_0和A^b_0由一个LiDAR数据的偏航旋转引起的移位C是相同的,这已在第III-B节中介绍。因此,对于旋转后的第一个变换器块,公式(7)变为:
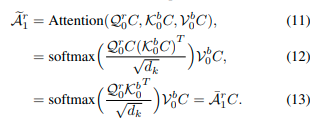
同样地,对于以下堆叠的交叉变换器块,我们也有:
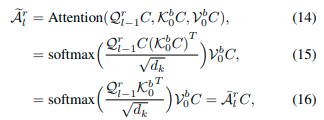
这意味着交叉视图变换器块的MHSA输出具有偏航角等变性。由于FFN和LN对于特征也具有偏航角等变性[3],而最后的串联是在通道维度上操作的,因此交叉视图的互相转换器输出具有偏航角等变性的特征体积。然后使用带有MLP的NetVLAD生成偏航角不变的全局描述符g^f。由于三个部分都具有偏航角不变性,我们的最终全局描述符也具有偏航角不变性。



评论(0)
您还未登录,请登录后发表或查看评论