动态目标检测
图像物体分类重在分析图像中存在的物体是什么,便于机器理解看到的环境信息,另外一种场景,机器不仅要识别某一物体,还要知道这个物体所在的位置,当物体在运动时,更要快速连续的跟踪,这就是目标检测,重在分析识别到物体在图像中的位置。
目标检测原理
假设我们要识别图像中这只狗的位置,以最为常用的YOLO算法为例,它会运用单个卷积神经网络(CNN) ,将图像分成网格,并预测每个网格的对象概率和边界框
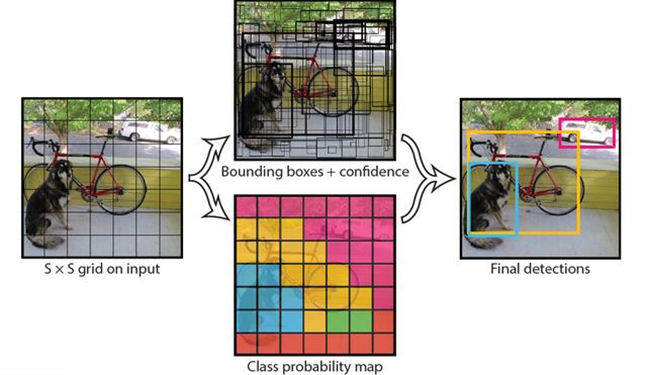
比如,对于这个图像,Yolo的CNN网络将输入的图片分割成7x7的网格,然后每个网格负责去检测那些中心点落在该格子内的目标,比如,小狗这个目标的中心点在左下角的网格中,那该网格就负责预测狗这个对象。
每个网格中将有多个边界框,在训练时,我们希望每个对象只有一个边界框,比如最终只有一个边界框把这只狗包起来。因此,我们根据哪个边界框与之前标注的重叠度最高,预测对象的位置和概率。
最终包围对象的边界框,就是识别的结果,使用四个描述符进行说明:
1. 边界框的中心位置
2. 边界框的高度
3. 边界框的宽度
4. 识别到对象所属的类
这样就完成了对目标的实时检测,拿到目标的信息之后,就可以进行后续的机器人行为控制了。
我们对目标检测系统运行速度的要求一般都比较高,可以实时处理视频流,比如车辆行驶的动态监测、自然环境中的目标识别,有着非常广泛的应用价值

回到TogetherROS和旭日X3派的开发板,我们来看下这套软硬件结合的目标检测系统,效率如何。
MIPI相机目标检测
接下来,我们要利用MIPI相机,动态识别图像中各种各样的物体以及他们所在的位置,推理过程使用的是基于COCO数据集训练的80个类别,也就是可以识别80种常用的物体位置。

运行例程
bash
$ cd /app/ai_inference/03_mipi_camera_sample/
$ python3 ./mipi_camera.py

代码解析
mipi_camera.py:
python
#!/usr/bin/env python3
import numpy as np
import cv2
import colorsys
# Camera API libs
from hobot_vio import libsrcampy as srcampy
from hobot_dnn import pyeasy_dnn as dnn
# detection model class names
def get_classes():
return np.array(["person", "bicycle", "car",
"motorcycle", "airplane", "bus",
"train", "truck", "boat",
"traffic light", "fire hydrant", "stop sign",
"parking meter", "bench", "bird",
"cat", "dog", "horse",
"sheep", "cow", "elephant",
"bear", "zebra", "giraffe",
"backpack", "umbrella", "handbag",
"tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball",
"kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket",
"bottle", "wine glass", "cup",
"fork", "knife", "spoon",
"bowl", "banana", "apple",
"sandwich", "orange", "broccoli",
"carrot", "hot dog", "pizza",
"donut", "cake", "chair",
"couch", "potted plant", "bed",
"dining table", "toilet", "tv",
"laptop", "mouse", "remote",
"keyboard", "cell phone", "microwave",
"oven", "toaster", "sink",
"refrigerator", "book", "clock",
"vase", "scissors", "teddy bear",
"hair drier", "toothbrush"])
def bgr2nv12_opencv(image):
height, width = image.shape[0], image.shape[1]
area = height * width
yuv420p = cv2.cvtColor(image, cv2.COLOR_RGB2YUV_I420).reshape((area * 3 // 2,))
y = yuv420p[:area]
uv_planar = yuv420p[area:].reshape((2, area // 4))
uv_packed = uv_planar.transpose((1, 0)).reshape((area // 2,))
nv12 = np.zeros_like(yuv420p)
nv12[:height * width] = y
nv12[height * width:] = uv_packed
return nv12
def get_hw(pro):
if pro.layout == "NCHW":
return pro.shape[2], pro.shape[3]
else:
return pro.shape[1], pro.shape[2]
def postprocess(model_output,
model_hw_shape,
origin_image=None,
origin_img_shape=None,
score_threshold=0.5,
nms_threshold=0.6,
dump_image=False):
input_height = model_hw_shape[0]
input_width = model_hw_shape[1]
if origin_image is not None:
origin_image_shape = origin_image.shape[0:2]
else:
origin_image_shape = origin_img_shape
prediction_bbox = decode(outputs=model_output,
score_threshold=score_threshold,
origin_shape=origin_image_shape,
input_size=512)
prediction_bbox = nms(prediction_bbox, iou_threshold=nms_threshold)
prediction_bbox = np.array(prediction_bbox)
topk = min(prediction_bbox.shape[0], 1000)
if topk != 0:
idx = np.argpartition(prediction_bbox[..., 4], -topk)[-topk:]
prediction_bbox = prediction_bbox[idx]
if dump_image and origin_image is not None:
draw_bboxs(origin_image, prediction_bbox)
return prediction_bbox
def draw_bboxs(image, bboxes, gt_classes_index=None, classes=get_classes()):
"""draw the bboxes in the original image
"""
num_classes = len(classes)
image_h, image_w, channel = image.shape
hsv_tuples = [(1.0 * x / num_classes, 1., 1.) for x in range(num_classes)]
colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
colors))
fontScale = 0.5
bbox_thick = int(0.6 * (image_h + image_w) / 600)
for i, bbox in enumerate(bboxes):
coor = np.array(bbox[:4], dtype=np.int32)
if gt_classes_index == None:
class_index = int(bbox[5])
score = bbox[4]
else:
class_index = gt_classes_index[i]
score = 1
bbox_color = colors[class_index]
c1, c2 = (coor[0], coor[1]), (coor[2], coor[3])
cv2.rectangle(image, c1, c2, bbox_color, bbox_thick)
classes_name = classes[class_index]
bbox_mess = '%s: %.2f' % (classes_name, score)
t_size = cv2.getTextSize(bbox_mess,
0,
fontScale,
thickness=bbox_thick // 2)[0]
cv2.rectangle(image, c1, (c1[0] + t_size[0], c1[1] - t_size[1] - 3),
bbox_color, -1)
cv2.putText(image,
bbox_mess, (c1[0], c1[1] - 2),
cv2.FONT_HERSHEY_SIMPLEX,
fontScale, (0, 0, 0),
bbox_thick // 2,
lineType=cv2.LINE_AA)
print("{} is in the picture with confidence:{:.4f}, bbox:{}".format(
classes_name, score, coor))
# cv2.imwrite("demo.jpg", image)
return image
def decode(outputs, score_threshold, origin_shape, input_size=512):
def _distance2bbox(points, distance):
x1 = points[..., 0] - distance[..., 0]
y1 = points[..., 1] - distance[..., 1]
x2 = points[..., 0] + distance[..., 2]
y2 = points[..., 1] + distance[..., 3]
return np.stack([x1, y1, x2, y2], -1)
def _scores(cls, ce):
cls = 1 / (1 + np.exp(-cls))
ce = 1 / (1 + np.exp(-ce))
return np.sqrt(ce * cls)
def _bbox(bbox, stride, origin_shape, input_size):
h, w = bbox.shape[1:3]
yv, xv = np.meshgrid(np.arange(h), np.arange(w))
xy = (np.stack((yv, xv), 2) + 0.5) * stride
bbox = _distance2bbox(xy, bbox)
# opencv read, shape[1] is w, shape[0] is h
scale_w = origin_shape[1] / input_size
scale_h = origin_shape[0] / input_size
scale = max(origin_shape[0], origin_shape[1]) / input_size
# origin img is pad resized
#bbox = bbox * scale
# origin img is resized
bbox = bbox * [scale_w, scale_h, scale_w, scale_h]
return bbox
bboxes = list()
strides = [8, 16, 32, 64, 128]
for i in range(len(strides)):
cls = outputs[i].buffer
bbox = outputs[i + 5].buffer
ce = outputs[i + 10].buffer
scores = _scores(cls, ce)
classes = np.argmax(scores, axis=-1)
classes = np.reshape(classes, [-1, 1])
max_score = np.max(scores, axis=-1)
max_score = np.reshape(max_score, [-1, 1])
bbox = _bbox(bbox, strides[i], origin_shape, input_size)
bbox = np.reshape(bbox, [-1, 4])
pred_bbox = np.concatenate([bbox, max_score, classes], axis=1)
index = pred_bbox[..., 4] > score_threshold
pred_bbox = pred_bbox[index]
bboxes.append(pred_bbox)
return np.concatenate(bboxes)
def nms(bboxes, iou_threshold, sigma=0.3, method='nms'):
def bboxes_iou(boxes1, boxes2):
boxes1 = np.array(boxes1)
boxes2 = np.array(boxes2)
boxes1_area = (boxes1[..., 2] - boxes1[..., 0]) * \
(boxes1[..., 3] - boxes1[..., 1])
boxes2_area = (boxes2[..., 2] - boxes2[..., 0]) * \
(boxes2[..., 3] - boxes2[..., 1])
left_up = np.maximum(boxes1[..., :2], boxes2[..., :2])
right_down = np.minimum(boxes1[..., 2:], boxes2[..., 2:])
inter_section = np.maximum(right_down - left_up, 0.0)
inter_area = inter_section[..., 0] * inter_section[..., 1]
union_area = boxes1_area + boxes2_area - inter_area
ious = np.maximum(1.0 * inter_area / union_area,
np.finfo(np.float32).eps)
return ious
classes_in_img = list(set(bboxes[:, 5]))
best_bboxes = []
for cls in classes_in_img:
cls_mask = (bboxes[:, 5] == cls)
cls_bboxes = bboxes[cls_mask]
while len(cls_bboxes) > 0:
max_ind = np.argmax(cls_bboxes[:, 4])
best_bbox = cls_bboxes[max_ind]
best_bboxes.append(best_bbox)
cls_bboxes = np.concatenate(
[cls_bboxes[:max_ind], cls_bboxes[max_ind + 1:]])
iou = bboxes_iou(best_bbox[np.newaxis, :4], cls_bboxes[:, :4])
weight = np.ones((len(iou),), dtype=np.float32)
assert method in ['nms', 'soft-nms']
if method == 'nms':
iou_mask = iou > iou_threshold
weight[iou_mask] = 0.0
if method == 'soft-nms':
weight = np.exp(-(1.0 * iou ** 2 / sigma))
cls_bboxes[:, 4] = cls_bboxes[:, 4] * weight
score_mask = cls_bboxes[:, 4] > 0.
cls_bboxes = cls_bboxes[score_mask]
return best_bboxes
def print_properties(pro):
print("tensor type:", pro.tensor_type)
print("data type:", pro.dtype)
print("layout:", pro.layout)
print("shape:", pro.shape)
if __name__ == '__main__':
models = dnn.load('../models/fcos_512x512_nv12.bin')
# 打印输入 tensor 的属性
print_properties(models[0].inputs[0].properties)
# 打印输出 tensor 的属性
print(len(models[0].outputs))
for output in models[0].outputs:
print_properties(output.properties)
# 获取 Camera 句柄
cam = srcampy.Camera()
# 打开 f37 摄像头,并且把输出突出缩小成算法模型的输入尺寸
h, w = get_hw(models[0].inputs[0].properties)
# 打开 F37, 初始化视频 pipeline 0 ,设置帧率30fps,缩放图像为 512 x 512
cam.open_cam(0, 1, 30, w, h)
# Get HDMI display object
disp = srcampy.Display()
# For the meaning of parameters, please refer to the relevant documents of HDMI display
disp.display(0, 1920, 1080)
input_shape = (h, w)
while True:
# 从相机获取分辨率为 512x512 的nv12格式的图像数据, 参数 2 代表从硬件模块IPU中获取
img = cam.get_img(2, 512, 512)
# 把图像数据转成 numpy 数据类型
img = np.frombuffer(img, dtype=np.uint8)
# 模型推理
outputs = models[0].forward(img)
# 对算法结果进行过滤,去掉执行度低的检测框,计算检测框的交并比去除冗余框,把检测框的坐标还原到原图位置上
prediction_bbox = postprocess(outputs, input_shape, origin_img_shape=(1080,1920))
# 从新获取一张图像,大小缩放成与显示器的分辨率一样的 1920 x 1080, 并且转换成 bgr格式,方便进行绘图操作
origin_image = cam.get_img(2, 1920, 1080)
origin_nv12 = np.frombuffer(origin_image, dtype=np.uint8).reshape(1620, 1920)
origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2BGR)
# 把算法运行后得到的物体检测框绘制到图像上
box_bgr = draw_bboxs(origin_bgr, prediction_bbox)
# X3 的HDMI输出模块的输入图像格式需要是NV12的,所以需要先把bgr格式转成NV12
box_nv12 = bgr2nv12_opencv(box_bgr)
# 把 NV12 格式的图像输出给显示器
disp.set_img(box_nv12.tobytes())
cam.close_cam()
USB相机目标检测
如果大家手上没有MIPI接口的相机,使用USB相机也可以实现同样的功能。

运行例程
bash
$ cd /app/ai_inference/02_usb_camera_sample/
$ python3 ./usb_camera_fcos.py

动态目标检测
大家如果没有HDMI显示器的话,也没有问题,刚才的例程,也可以这样来运行,我们通过统一网络环境中的浏览器就可以动态看到结果啦。
bash
# 启动webserver服务
$ cd /opt/tros/lib/websocket/webservice/
$ chmod +x ./sbin/nginx && ./sbin/nginx -p .
bash
# 运行例程
$ source /opt/tros/setup.bash
$ cp -r /opt/tros/lib/dnn_node_example/config/ .
$ cp -r /opt/tros/lib/dnn_benchmark_example/config/runtime/ ./config/
$ ros2 launch /opt/tros/share/dnn_node_example/launch/hobot_dnn_node_example.launch.py config_file:=config/fcosworkconfig.json image_width:=480 image_height:=272




评论(0)
您还未登录,请登录后发表或查看评论