

0. 简介
作为SLAM中常用的方法,其原因是因为SLAM观测不只考虑到当前帧的情况,而需要加入之前状态量的观测。就比如一个在二维平面上移动的机器人,机器人可以使用一组传感器,例如车轮里程计或激光测距仪。从这些原始测量值中,我们想要估计机器人的轨迹并构建环境地图。为了降低问题的计算复杂度,位姿图方法将原始测量值抽象出来。具体来说,它创建了一个表示机器人姿态的节点图,以及表示两个节点之间的相对变换(增量位置和方向)的边。边缘是源自原始传感器测量值的虚拟测量值,例如通过集成原始车轮里程计或对齐从机器人获取的激光范围扫描。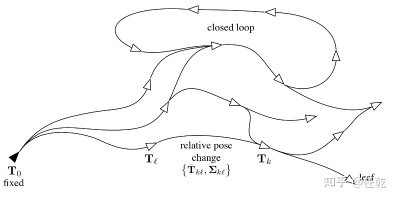
对上图的具体描述如下

1. Ceres-Solver的位姿图优化
1.1 Ceres-Solver的用法
之前作者已经已经在《SLAM本质剖析-Ceres》中详细的介绍了SLAM中对Ceres的使用。使用 Ceres Solver求解非线性优化问题,主要包括以下几部分:
- 构建代价函数
(cost function)或残差(residual) - 构建优化问题
(ceres::Problem):通过 AddResidualBlock 添加代价函数(cost function)、损失函数(loss function核函数) 和 待优化状态量 - 配置求解器
(ceres::Solver::Options) - 运行求解器
(ceres::Solve(options, &problem, &summary))
与g2o优化中直接在边上添加information(信息矩阵)不同,Ceres无法直接实现此功能。 由于Ceres只接受最小二乘优化就,即$min(r^{^{T}}r)$;若要对残差加权,使用马氏距离即$min (r^{^{T}}\Sigma r)$,则要对信息矩阵(协方差矩阵)$\Sigma$做Cholesky分解:$LL^{^{T}}=\Sigma$,则$r^{^{T}}\Sigma r=r^{^{T}}(LL^{^{T}})r=(L^{^{T}}r)^{T}(L^{T}r)$,令$r’=L^{T}r$,最终得到纯种的最小二乘优化:$min(r’^{^{T}}r’)$。
1.2 Ceres优化步骤
这一块的内容在前文中已经详细阐述了,这里就不详细分析了,下面直接贴一下每个部分的代码以及结构的组成。
Step1:构建Cost Function
(1)AutoDiffCostFunction(自动求导)
- 构造 代价函数结构体或代价函数类(例如:
struct CostFunctor),在其结构体内对模板括号()重载用来定义残差; - 在重载的
()函数形参中,最后一个为残差,前面几个为待优化状态量,注意:形参类型必须是模板类型。
struct CostFunctor {
template<typename T>
bool operator()(const T *const x, T *residual) const {
residual[0] = 10.0 - x[0]; // r(x) = 10 - x
return true;
}
};
- 利用ceres::CostFunction *cost_function=new ceres::AutoDiffCostFunction<functype,dimension1,dimension2>(new costFunc),获得Cost Function</functype,dimension1,dimension2>
模板参数分别是:代价结构体仿函数类型名,残差维度,第一个优化变量维度,第二个….;函数参数(new costFunc)是代价结构体(或类)对象,即此对象重载的
()函数的函数指针
(2)NumericDiffCostFunction(数值求导)
- 数值求导法 也是构造 代价函数结构体,也需要重载括号
()来定义残差,但在重载括号()时没有用模板;
struct CostFunctorNum {
bool operator()(const double *const x, double *residual) const {
residual[0] = 10.0 - x[0]; // r(x) = 10 - x
return true;
}
};
- 并且在实例化代价函数时也稍微有点区别,多了一个模板参数
ceres::CENTRAL
ceres::CostFunction *cost_function;
cost_function =new ceres::NumericDiffCostFunction<CostFunctorNum, ceres::CENTRAL, 1, 1>(new CostFunctorNum);
(3)自定义CostFunction
- 构建一个 继承自
ceres::SizedCostFunction<1,1>的类,同样,对于模板参数的数字,第一个为残差的维度,后面几个为待优化状态量的维度 ; - 重载虚函数
virtual bool Evaluate(double const* const* parameters, double *residuals, double **jacobians) const,根据 待优化变量,实现 残差和雅克比矩阵的计算(雅克比矩阵计算需要提供公式);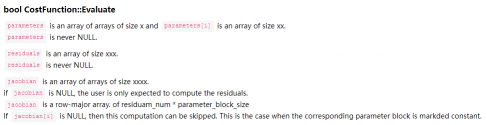
virtual bool Evaluate(double const* const* parameters, double* residuals, double** jacobians) const;:核心函数,跟自动求导中用仿函数中 operator() 类似,这里重写了基类中的 evaluate 函数,并且需要在其中定义误差和雅克比矩阵的计算方式:double const* const* parameters:参数块,主要是传入的各个节点,第一维度为节点的个数(这里是 6),第二维度则是对应节点的维度(这里两个节点的维度都是 6)double* residuals:残差,维度取决于误差的维度,这里是 6double** jacobians:雅克比矩阵,第一个维度为节点的个数(也就是要求解的雅克比矩阵的数量),第二个维度为对应雅克比矩阵的元素个数(这里两个雅克比矩阵的维度都是 6x6,因此维度是 36)
详细的解析可以看一下这篇博客Ceres 学习记录(一):2D 位姿图优化
class PoseGraphCFunc : public ceres::SizedCostFunction<6,6,6>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
PoseGraphCFunc(const Sophus::SE3 measure,const Matrix6d covariance):_measure(measure),_covariance(covariance){}
~PoseGraphCFunc(){}
virtual bool Evaluate(double const* const* parameters,
double *residuals,
double **jacobians)const
{
//创建带有参数的SE3
Sophus::SE3 pose_i=Sophus::SE3::exp(Vector6d(parameters[0]));//Eigen::MtatrixXd可以通过double指针来构造
Sophus::SE3 pose_j=Sophus::SE3::exp(Vector6d(parameters[1]));
Eigen::Map<Vector6d> residual(residuals);//Eigen::Map<typename MatrixX>(ptr)函数的作用是通过传入指针将c++数据映射为Eigen上的Matrix数据,有点与&相似
//通过LLT分解得到信息矩阵
residual=(_measure.inverse()*pose_i.inverse()*pose_j).log();
Matrix6d sqrt_info=Eigen::LLT<Matrix6d>(_covariance).matrixLLT().transpose();
//计算雅克比矩阵
if(jacobians)
{
if(jacobians[0])
{
Eigen::Map<Eigen::Matrix<double,6,6,Eigen::RowMajor>> jacobian_i(jacobians[0]);
Matrix6d Jr=JRInv(Sophus::SE3::exp(residual));
jacobian_i=(sqrt_info)*(-Jr)*pose_j.inverse().Adj();
}
if(jacobians[1])
{
Eigen::Map<Eigen::Matrix<double,6,6, Eigen::RowMajor>> jacobian_j(jacobians[1]);
Matrix6d J = JRInv(Sophus::SE3::exp(residual));
jacobian_j = sqrt_info * J * pose_j.inverse().Adj();
}
}
residual=sqrt_info*residual;
return true;
}
private:
const Sophus::SE3 _measure;
const Matrix6d _covariance;
};
- 如果待优化变量处于流形上则需自定义 一个继承于LocalParameterization的类,重载其中的Plus()函数实现迭代递增,重载computeJacobian()定义流形到切平面的雅克比矩阵
class Parameterization:public ceres::LocalParameterization
{
public:
Parameterization(){}
virtual ~Parameterization(){}
virtual bool Plus(const double* x,
const double * delta,
double *x_plus_delta)const
{
Vector6d lie(x);
Vector6d lie_delta(delta);
Sophus::SE3 T=Sophus::SE3::exp(lie);
Sophus::SE3 T_delta=Sophus::SE3::exp(lie_delta);
Eigen::Map<Vector6d> x_plus(x_plus_delta);
x_plus=(T_delta*T).log();
return true;
}
//流形到其切平面的雅克比矩阵
virtual bool ComputeJacobian(const double *x,
double * jacobian) const
{
ceres::MatrixRef(jacobian,6,6)=ceres::Matrix::Identity(6,6);//ceres::MatrixRef()函数也类似于Eigen::Map,通过模板参数传入C++指针将c++数据映射为Ceres::Matrix
return true;
}
//定义流形和切平面维度:在本问题中是李代数到李代数故都为6
virtual int GlobalSize()const{return 6;}
virtual int LocalSize()const {return 6;}
};
Step2:AddResidualBlock
- 声明
ceres::Problem problem; - 通过
AddResidualBlock将 代价函数(cost function)、损失函数(loss function) 和 待优化状态量 添加到problem
ceres::LossFunction *loss = new ceres::HuberLoss(1.0);
ceres::CostFunction *costfunc = new PoseGraphCFunc(measurement, covariance);//定义costfunction
problem.AddResidualBlock(costfunc, loss, param[vertex_i].se3, param[vertex_j].se3);//为整体代价函数加入快,ceres的优点就是直接在param[vertex_i].se3上优化
problem.SetParameterization(param[vertex_i].se3, local_param);//为待优化的两个位姿变量定义迭代递增方式
problem.SetParameterization(param[vertex_j].se3, local_param);
Step3:配置优化参数并优化Config&solve
- 定义ceres::Solver::Options options;对options成员进行赋值以配置优化参数;
- 定义ceres::Solver::Summary summary;用来存储优化输出;
- 求解:ceres::Solve(options, &problem, &summary);
ceres::Solver::Options options;//配置优化设置
options.linear_solver_type = ceres::SPARSE_NORMAL_CHOLESKY;
options.trust_region_strategy_type=ceres::LEVENBERG_MARQUARDT;
options.max_linear_solver_iterations = 50;
options.minimizer_progress_to_stdout = true;
ceres::Solver::Summary summary;//summary用来存储优化过程
ceres::Solve(options, &problem, &summary);//开始优化
1.3 Ceres代码详解
这里借鉴了这篇文章的信息。并结合自己的理解去进行分析,解决了作者未能解决的问题。
1.3.1.pose_graph_2d_error_term.h
这个文件中主要是实现了ceres计算残差需要的类,也就是之前自己定义的包含模板()运算符的结构体或类。并且在这个类的定义中,官方注释非常详细的解释了残差的计算公式,结合官网的教程很容易明白。
// Computes the error term for two poses that have a relative pose measurement
// between them. Let the hat variables be the measurement.
//
// residual = information^{1/2} * [ r_a^T * (p_b - p_a) - \hat{p_ab} ]
// [ Normalize(yaw_b - yaw_a - \hat{yaw_ab}) ]
//
// where r_a is the rotation matrix that rotates a vector represented in frame A
// into the global frame, and Normalize(*) ensures the angles are in the range
// [-pi, pi).
class PoseGraph2dErrorTerm {
public:
PoseGraph2dErrorTerm(double x_ab, // 这些都是实际观测值,也就是位姿图中的边
double y_ab,
double yaw_ab_radians,
const Eigen::Matrix3d& sqrt_information)
: p_ab_(x_ab, y_ab),
yaw_ab_radians_(yaw_ab_radians),
sqrt_information_(sqrt_information) {}
template <typename T>
// 括号运算符中传入的是节点的值,然后利用这些值计算估计的观测值,
// 和实际传入的观测值做差,得到残差
bool operator()(const T* const x_a,
const T* const y_a,
const T* const yaw_a,
const T* const x_b,
const T* const y_b,
const T* const yaw_b,
T* residuals_ptr) const {
const Eigen::Matrix<T, 2, 1> p_a(*x_a, *y_a);
const Eigen::Matrix<T, 2, 1> p_b(*x_b, *y_b);
// 为什么要声明为Map呢?经常操作,并且给它赋值的数据是Eigen的数据类型?
// map就像相当于C++中的数组,主要是为了和原生的C++数组交互
Eigen::Map<Eigen::Matrix<T, 3, 1>> residuals_map(residuals_ptr);
residuals_map.template head<2>() =
RotationMatrix2D(*yaw_a).transpose() * (p_b - p_a) - p_ab_.cast<T>();
residuals_map(2) = ceres::examples::NormalizeAngle(
(*yaw_b - *yaw_a) - static_cast<T>(yaw_ab_radians_));
// Scale the residuals by the square root information matrix to account for
// the measurement uncertainty.
residuals_map = sqrt_information_.template cast<T>() * residuals_map;
return true;
}
// 再次看到static,只是为了提高程序紧凑型,因为下面这个函数只给当前这个类用,类似一种全局函数
static ceres::CostFunction* Create(double x_ab,
double y_ab,
double yaw_ab_radians,
const Eigen::Matrix3d& sqrt_information) {
return (new ceres::
AutoDiffCostFunction<PoseGraph2dErrorTerm, 3, 1, 1, 1, 1, 1, 1>(
new PoseGraph2dErrorTerm(
x_ab, y_ab, yaw_ab_radians, sqrt_information)));
}
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
private:
// The position of B relative to A in the A frame.
const Eigen::Vector2d p_ab_;
// The orientation of frame B relative to frame A.
const double yaw_ab_radians_;
// The inverse square root of the measurement covariance matrix.
const Eigen::Matrix3d sqrt_information_;
};
注意上面程序中的几个细节:
-
还是原来的套路,类的形参传入的是实际观测的数据点,也就是g2o中的边,传入的这些数据值会赋值给类的成员变量,在
()运算中计算残差的时候会用到这些成员变量, 也就是观测的数据值。而对于()运算符,传入的是顶点的值,就是g2o中的顶点,或者说是要被优化的值。然后在()运算中,先利用这些顶点值得到计算的观测值,然后和实际的观测值相减,就得到了残差。 -
这个类中再次出现了static函数,这个函数就是返回new出来的一个自动求导对象指针。这样写在类里的好处是让程序更加紧凑,因为自动求导对象里的构造参数是和我们定义的这个类数据紧密相关的。
-
在
()运算中定义残差的时候,使用到了eigen中的map类。实际上map类是为了兼容eigen的矩阵操作与C++的数组操作。
(1)看程序中有一句EIGEN_MAKE_ALIGNED_OPERATOR_NEW声明内存对齐,这在自定义的类中使用Eigen的数据类型时是必要的,还有的时候能看到在std::vector中插入Eigen的变量后面要加一个Eigen::Aligend...,也是为了声明Eigen的内存对齐,这样才能使用STL容器。所以这里要清楚,Eigen为了实现矩阵运算,其内存和原生的C++内存分配出现了差别,很多时候都需要声明一下。
(2)再回到map类,这个类就是为了实现和C++中数组一样的内存分配方式,比如使用指针可以快速访问;但是同时他又可以支持Eigen的矩阵运算,所以在需要对矩阵元素频繁操作或者访问的时候,声明为map类是一个很好的选择。再来看这里为什么要声明为map类?首先频繁操作,要把算出来的残差存到这个矩阵中;其次计算的结果(=右边)都是eigen的数据类型,所以也要和Eigen的数据类型兼容。所以满足使用map的两个情况,因此使用map类很合适。
(3)详细资料参见:Eigen库中的Map类到底是做什么的(4) map.[template中template](http://eigen.tuxfamily.org/dox-3.2/classEigen_1_1SparseMatrixBase.html)是由于block是模板化成员,如果矩阵类型也是模板参数,则必须使用关键字模板
residuals_map.template head<2>() =
RotationMatrix2D(*yaw_a).transpose() * (p_b - p_a) - p_ab_.cast<T>();
residuals_map(2) = ceres::examples::NormalizeAngle(
(*yaw_b - *yaw_a) - static_cast<T>(yaw_ab_radians_));
1.3.2.pose_graph_2d.h
这个文件就是主文件,主要就是实现添加残差块。对于每一个观测数据,都需要添加残差块。然后其中还有官网说的那个Normalize限制旋转角度的范围的问题。
其次还有一个比较重要的问题,就是程序中最后把最开始的那个位姿设置成了常量,不优化它,也就是那段长注释解释的,具体我没有看的很懂。
// The pose graph optimization problem has three DOFs that are not fully
// constrained. This is typically referred to as gauge freedom. You can apply
// a rigid body transformation to all the nodes and the optimization problem
// will still have the exact same cost. The Levenberg-Marquardt algorithm has
// internal damping which mitigate this issue, but it is better to properly
// constrain the gauge freedom. This can be done by setting one of the poses
// as constant so the optimizer cannot change it.
位姿图优化问题具有三个未完全约束的自由度。这通常称为规范自由度。您可以对所有节点应用刚体变换,优化问题仍然具有完全相同的成本。 Levenberg-Marquardt 算法具有内部阻尼来缓解这个问题,但最好适当地约束规范自由度。这可以通过将其中一个姿势设置为常量来完成,这样优化器就无法更改它。
// Constructs the nonlinear least squares optimization problem from the pose
// graph constraints.
// Constraint2d 2D的约束,是一个自定义的结构体类,描述了顶点之间的位姿约束,也就是g2o中的边
void BuildOptimizationProblem(const std::vector<Constraint2d>& constraints,
std::map<int, Pose2d>* poses,
ceres::Problem* problem) {
CHECK(poses != NULL);
CHECK(problem != NULL);
if (constraints.empty()) {
LOG(INFO) << "No constraints, no problem to optimize.";
return;
}
// LossFunction就是和函数,这里不使用核函数
ceres::LossFunction* loss_function = NULL;
// 局部参数化:
// Lastly, we use a local parameterization to normalize the orientation in the range which is normalized between【-pi,pi)
ceres::LocalParameterization* angle_local_parameterization =
AngleLocalParameterization::Create();
// 使用常量迭代器访问容器,得到容器中的所有元素
for (std::vector<Constraint2d>::const_iterator constraints_iter =
constraints.begin();
constraints_iter != constraints.end();
++constraints_iter) {
const Constraint2d& constraint = *constraints_iter; // 得到当前访问的约束元素
std::map<int, Pose2d>::iterator pose_begin_iter =
poses->find(constraint.id_begin); // 根据约束的顶点Id号得到指向顶点1的迭代器
CHECK(pose_begin_iter != poses->end()) // 找到了
<< "Pose with ID: " << constraint.id_begin << " not found.";
std::map<int, Pose2d>::iterator pose_end_iter = // 根据约束的顶点Id号得到指向顶点2的迭代器
poses->find(constraint.id_end);
CHECK(pose_end_iter != poses->end())
<< "Pose with ID: " << constraint.id_end << " not found.";
const Eigen::Matrix3d sqrt_information =
// llt = LL^T,cholesky分解,然后matrixL是cholesky因子组成的矩阵
constraint.information.llt().matrixL(); // 信息矩阵,即协方差矩阵的逆
// Ceres will take ownership of the pointer.
// PoseGraph2dErrorTerm是专门定义的一个用于2D位姿图优化的类,相当于这个类中已经定义好了残差块的()运算符
// 和之前自己写计算残差的结构体或者类是一样的。costfunction是添加参数块的时候必须使用的
ceres::CostFunction* cost_function = PoseGraph2dErrorTerm::Create(
constraint.x, constraint.y, constraint.yaw_radians, sqrt_information);
// 对每一个观测值,都添加残差块
problem->AddResidualBlock(cost_function,
loss_function,
&pose_begin_iter->second.x, // 因为这是一个map的迭代器,map中first就是key值,second就是value值
&pose_begin_iter->second.y, // 因为key存的是pose的id号,这里用的是顶点的pose,所以是value的值
&pose_begin_iter->second.yaw_radians,
&pose_end_iter->second.x,
&pose_end_iter->second.y,
&pose_end_iter->second.yaw_radians);
// 设置参数化,这里设置边的两个顶点的pose的旋转角度为 local_parameterization
problem->SetParameterization(&pose_begin_iter->second.yaw_radians,
angle_local_parameterization);
problem->SetParameterization(&pose_end_iter->second.yaw_radians,
angle_local_parameterization);
}
// The pose graph optimization problem has three DOFs that are not fully
// constrained. This is typically referred to as gauge freedom. You can apply
// a rigid body transformation to all the nodes and the optimization problem
// will still have the exact same cost. The Levenberg-Marquardt algorithm has
// internal damping which mitigate this issue, but it is better to properly
// constrain the gauge freedom. This can be done by setting one of the poses
// as constant so the optimizer cannot change it.
std::map<int, Pose2d>::iterator pose_start_iter = poses->begin();
CHECK(pose_start_iter != poses->end()) << "There are no poses.";
problem->SetParameterBlockConstant(&pose_start_iter->second.x);
problem->SetParameterBlockConstant(&pose_start_iter->second.y);
problem->SetParameterBlockConstant(&pose_start_iter->second.yaw_radians);
}
2. G2O的位姿图优化
G2O这部分也在我们的系列文章《SLAM本质剖析-G2O》中详细的阐述了。这里不详细的去写了。G2O本身就是经常被用于位姿图优化的,所以这里我们直接给出例子。算法的整个流程:1、构造g2o优化问题并执行优化;2、每次优化完成后,对地图点是否为外点进行卡方检验,检验到为内点的加入下次优化,否则下次不优化;3、得到优化后的当前帧的位姿(此函数只优化当前帧位姿)
int Optimizer::PoseOptimization(Frame *pFrame)
{
// Step 1:这里先构造了大boss--g2o稀疏优化器, BlockSolver_6_3表示:位姿为6维,路标点是3维
g2o::SparseOptimizer optimizer;//图模型
g2o::BlockSolver_6_3::LinearSolverType * linearSolver;//线性求解器声明
// 创建一个线性求解器
linearSolver = new g2o::LinearSolverDense<g2o::BlockSolver_6_3::PoseMatrixType>();
// 创建一个矩阵求解器并用上述线性求解器初始化
g2o::BlockSolver_6_3 * solver_ptr = new g2o::BlockSolver_6_3(linearSolver);
//创建一个总的求解器,并用上述矩阵求解器初始化,可以看到这里使用了LM算法
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg(solver_ptr);
//设置求解器
optimizer.setAlgorithm(solver);
// 输入的帧中,有效的,参与优化过程的2D-3D点对
int nInitialCorrespondences=0;
// Step 2:添加顶点:待优化当前帧的位姿
g2o::VertexSE3Expmap * vSE3 = new g2o::VertexSE3Expmap();//创建一个顶点
vSE3->setEstimate(Converter::toSE3Quat(pFrame->mTcw));//转化成四元数+平移向量得形式
// 设置id
vSE3->setId(0);
// 要优化的变量,所以不能固定
vSE3->setFixed(false);
optimizer.addVertex(vSE3);//添加顶点到优化器
// 地图点得个数,也就是要往优化器里添加得地图点个数。用于计算误差边(重投影误差)
const int N = pFrame->N;
vector<ORB_SLAM3::EdgeSE3ProjectXYZOnlyPose*> vpEdgesMono;
vector<ORB_SLAM3::EdgeSE3ProjectXYZOnlyPoseToBody *> vpEdgesMono_FHR;
vector<size_t> vnIndexEdgeMono, vnIndexEdgeRight;
vpEdgesMono.reserve(N);
vpEdgesMono_FHR.reserve(N);
vnIndexEdgeMono.reserve(N);
vnIndexEdgeRight.reserve(N);
vector<g2o::EdgeStereoSE3ProjectXYZOnlyPose*> vpEdgesStereo;
vector<size_t> vnIndexEdgeStereo;
vpEdgesStereo.reserve(N);
vnIndexEdgeStereo.reserve(N);
// 下面涉及卡方分布去除外点的知识,这里不做讲解
// 自由度为2的卡方分布,显著性水平为0.05,对应的临界阈值5.991
const float deltaMono = sqrt(5.991);
// 自由度为3的卡方分布,显著性水平为0.05,对应的临界阈值7.815
const float deltaStereo = sqrt(7.815);
// Step 3:添加一元边(因为此函数只优化当前位姿)
{
// 锁定地图点。因为系统是多线程,所以在取数据时要加锁才能保证线程安全。
// 另一方面,需要使用地图点来构造顶点和边,因此不希望在构造的过程中部分地图点被改写造成不一致甚至是段错误
unique_lock<mutex> lock(MapPoint::mGlobalMutex);
// 遍历当前地图中的所有地图点
for(int i=0; i<N; i++)
{
MapPoint* pMP = pFrame->mvpMapPoints[i];
// 如果这个地图点存在
if(pMP)
{
if(!pFrame->mpCamera2)
{
// 单目情况
if(pFrame->mvuRight[i]<0)
{
nInitialCorrespondences++;
pFrame->mvbOutlier[i] = false;// 先默认此地图点不是外点
// 对这个地图点的观测
Eigen::Matrix<double,2,1> obs;
const cv::KeyPoint &kpUn = pFrame->mvKeysUn[i];
obs << kpUn.pt.x, kpUn.pt.y;
// 新建边,这个边只优化位姿Pose
ORB_SLAM3::EdgeSE3ProjectXYZOnlyPose* e = new ORB_SLAM3::EdgeSE3ProjectXYZOnlyPose();
e->setVertex(0, dynamic_cast<g2o::OptimizableGraph::Vertex*>(optimizer.vertex(0)));
e->setMeasurement(obs);//设置测量值
// 这个点的置信度,其与特征点所在的图层有关。用信息矩阵(协方差矩阵得逆)来表示。
const float invSigma2 = pFrame->mvInvLevelSigma2[kpUn.octave];
e->setInformation(Eigen::Matrix2d::Identity()*invSigma2);
// 在这里使用了鲁棒核函数
g2o::RobustKernelHuber* rk = new g2o::RobustKernelHuber;
e->setRobustKernel(rk);
rk->setDelta(deltaMono);
// 设置相机内参
e->pCamera = pFrame->mpCamera;
// 地图点的空间位置,作为迭代的初始值
cv::Mat Xw = pMP->GetWorldPos();
e->Xw[0] = Xw.at<float>(0);
e->Xw[1] = Xw.at<float>(1);
e->Xw[2] = Xw.at<float>(2);
optimizer.addEdge(e);//将此边加入优化器
vpEdgesMono.push_back(e);//记录边属于单目情况
vnIndexEdgeMono.push_back(i);//记录索引
}
else // Stereo observation
{
nInitialCorrespondences++;
pFrame->mvbOutlier[i] = false;
// 观测多了一项右目的坐标
Eigen::Matrix<double,3,1> obs;
const cv::KeyPoint &kpUn = pFrame->mvKeysUn[i];
const float &kp_ur = pFrame->mvuRight[i];
obs << kpUn.pt.x, kpUn.pt.y, kp_ur;
// 新建节点,注意这里也是只优化位姿
g2o::EdgeStereoSE3ProjectXYZOnlyPose* e = new g2o::EdgeStereoSE3ProjectXYZOnlyPose();
e->setVertex(0, dynamic_cast<g2o::OptimizableGraph::Vertex*>(optimizer.vertex(0)));
e->setMeasurement(obs);
// 置信程度主要是看左目特征点所在的图层
const float invSigma2 = pFrame->mvInvLevelSigma2[kpUn.octave];
Eigen::Matrix3d Info = Eigen::Matrix3d::Identity()*invSigma2;
e->setInformation(Info);
g2o::RobustKernelHuber* rk = new g2o::RobustKernelHuber;
e->setRobustKernel(rk);
rk->setDelta(deltaStereo);
//获得内参和地图点坐标作为初始值
e->fx = pFrame->fx;
e->fy = pFrame->fy;
e->cx = pFrame->cx;
e->cy = pFrame->cy;
e->bf = pFrame->mbf;
cv::Mat Xw = pMP->GetWorldPos();
e->Xw[0] = Xw.at<float>(0);
e->Xw[1] = Xw.at<float>(1);
e->Xw[2] = Xw.at<float>(2);
optimizer.addEdge(e);
vpEdgesStereo.push_back(e);
vnIndexEdgeStereo.push_back(i);
}
}
}
}
}
// 如果没有足够的匹配点,那么就只好放弃了
//cout << "PO: vnIndexEdgeMono.size() = " << vnIndexEdgeMono.size() << " vnIndexEdgeRight.size() = " << vnIndexEdgeRight.size() << endl;
if(nInitialCorrespondences<3)
return 0;
// Step 4:开始优化,总共优化四次,每次优化迭代10次,每次优化后,将观测分为outlier和inlier,outlier不参与下次优化
// 基于卡方检验计算出的阈值(假设测量有一个像素的偏差)
const float chi2Mono[4]={5.991,5.991,5.991,5.991}; // 单目
const float chi2Stereo[4]={7.815,7.815,7.815, 7.815}; // 双目
const int its[4]={10,10,10,10};// 四次迭代,每次迭代的次数
// bad 的地图点个数
int nBad=0;
// 一共进行四次优化
for(size_t it=0; it<4; it++)
{
//这里面计算了重投影误差。
vSE3->setEstimate(Converter::toSE3Quat(pFrame->mTcw));
// 其实就是初始化优化器,这里的参数0就算是不填写,默认也是0,也就是只对level为0的边进行优化
optimizer.initializeOptimization(0);
// 开始优化,优化10次
optimizer.optimize(its[it]);
nBad=0;
// 优化结束,开始遍历参与优化的每一条误差边(单目),其实就是重投影误差
for(size_t i=0, iend=vpEdgesMono.size(); i<iend; i++)
{
ORB_SLAM3::EdgeSE3ProjectXYZOnlyPose* e = vpEdgesMono[i];
const size_t idx = vnIndexEdgeMono[i];
// 下面是卡方检验
// 由于每次优化后是对所有的观测进行卡方检验outlier和inlier判别,因此之前被判别为outlier有可能变成inlier,反之亦然
// 如果这条误差边是来自于outlier
if(pFrame->mvbOutlier[idx])
{
e->computeError();
}
// 就是error*\Omega*error,表征了这个点的误差大小(考虑置信度以后)
const float chi2 = e->chi2();
//检验不通过
if(chi2>chi2Mono[it])
{
pFrame->mvbOutlier[idx]=true;
e->setLevel(1); // 设置为outlier , level 1 对应为外点,上面的过程中我们设置其为不优化
nBad++;
}
else
{
pFrame->mvbOutlier[idx]=false;
e->setLevel(0); // 设置为inlier, level 0 对应为内点,上面的过程中我们就是要优化这些关系
}
if(it==2)
e->setRobustKernel(0); // 除了前两次优化需要RobustKernel以外, 其余的优化都不需要 -- 因为重投影的误差已经有明显的下降了
}
// ……
// Step 5 得到优化后的当前帧的位姿
g2o::VertexSE3Expmap* vSE3_recov = static_cast<g2o::VertexSE3Expmap*>(optimizer.vertex(0));
g2o::SE3Quat SE3quat_recov = vSE3_recov->estimate();
cv::Mat pose = Converter::toCvMat(SE3quat_recov);
pFrame->SetPose(pose);// 设置优化后得位姿
//cout << "[PoseOptimization]: initial correspondences-> " << nInitialCorrespondences << " --- outliers-> " << nBad << endl;
// 并且返回内点数目
return nInitialCorrespondences-nBad;
}
3. GTSAM的位姿图优化
GTSAM这部分也在我们的系列文章《SLAM本质剖析-GTSAM》中详细的阐述了。这里不详细的去写了。GTSAM本身和G2O一样,经常被用于位姿图优化的,所以这里我们直接给出例子。算法的整个流程:1、构建因子图模型;2、初始化顶点值;3、固定第一个顶点,添加一个系统先验,一元因子;4、添加位姿间约束,二元因子;5、添加回环间约束,二元因子;6、问题求解,这里用的是高斯牛顿法;7、边缘化,计算每个变量的协方差矩阵。下面是LeGo-LOAM中的因子图优化逻辑
1)系列头文件
#include <gtsam/geometry/Rot3.h>
#include <gtsam/geometry/Pose3.h>
#include <gtsam/slam/PriorFactor.h>
#include <gtsam/slam/BetweenFactor.h>
#include <gtsam/nonlinear/NonlinearFactorGraph.h>
#include <gtsam/nonlinear/LevenbergMarquardtOptimizer.h>
#include <gtsam/nonlinear/Marginals.h>
#include <gtsam/nonlinear/Values.h>
#include <gtsam/nonlinear/ISAM2.h>
2)系列声明与初始化
using namespace gtsam;
NonlinearFactorGraph gtSAMgraph;
Values initialEstimate;
Values optimizedEstimate;
ISAM2 *isam;
Values isamCurrentEstimate;
noiseModel::Diagonal::shared_ptr priorNoise;
noiseModel::Diagonal::shared_ptr odometryNoise;
noiseModel::Diagonal::shared_ptr constraintNoise;
//初始化
ISAM2Params parameters;
parameters.relinearizeThreshold = 0.01;
parameters.relinearizeSkip = 1;
isam = new ISAM2(parameters);
gtsam::Vector Vector6(6);
Vector6 << 1e-6, 1e-6, 1e-6, 1e-8, 1e-8, 1e-6;
priorNoise = noiseModel::Diagonal::Variances(Vector6);
odometryNoise = noiseModel::Diagonal::Variances(Vector6);
3)在回环检测线程中,当找到闭环,就添加回环因子
gtsam::Pose3 poseFrom = Pose3(Rot3::RzRyRx(roll, pitch, yaw), Point3(x, y, z));
gtsam::Pose3 poseTo = pclPointTogtsamPose3(cloudKeyPoses6D->points[closestHistoryFrameID]);
gtsam::Vector Vector6(6);
float noiseScore = icp.getFitnessScore();
Vector6 << noiseScore, noiseScore, noiseScore, noiseScore, noiseScore, noiseScore;
constraintNoise = noiseModel::Diagonal::Variances(Vector6);
/* add constraints*/
std::lock_guard<std::mutex> lock(mtx);
gtSAMgraph.add(BetweenFactor<Pose3>(latestFrameIDLoopCloure, closestHistoryFrameID, poseFrom.between(poseTo), constraintNoise));
isam->update(gtSAMgraph);
isam->update();
gtSAMgraph.resize(0);
4)在保存关键帧和因子中,先是添加固定先验因子
if (cloudKeyPoses3D->points.empty())
{
gtSAMgraph.add(PriorFactor<Pose3>(0, Pose3(Rot3::RzRyRx(transformTobeMapped[2], transformTobeMapped[0], transformTobeMapped[1]),Point3(transformTobeMapped[5], transformTobeMapped[3], transformTobeMapped[4])), priorNoise));
initialEstimate.insert(0, Pose3(Rot3::RzRyRx(transformTobeMapped[2], transformTobeMapped[0], transformTobeMapped[1]),Point3(transformTobeMapped[5], transformTobeMapped[3], transformTobeMapped[4])));
for (int i = 0; i < 6; ++i)
transformLast[i] = transformTobeMapped[i];
}
5)随后添加位姿间的二元因子
else
{
gtsam::Pose3 poseFrom = Pose3(Rot3::RzRyRx(transformLast[2], transformLast[0], transformLast[1]),Point3(transformLast[5], transformLast[3], transformLast[4]));
gtsam::Pose3 poseTo = Pose3(Rot3::RzRyRx(transformAftMapped[2], transformAftMapped[0], transformAftMapped[1]),Point3(transformAftMapped[5], transformAftMapped[3], transformAftMapped[4]));
gtSAMgraph.add(BetweenFactor<Pose3>(cloudKeyPoses3D->points.size()-1, cloudKeyPoses3D->points.size(), poseFrom.between(poseTo), odometryNoise));
initialEstimate.insert(cloudKeyPoses3D->points.size(), Pose3(Rot3::RzRyRx(transformAftMapped[2], transformAftMapped[0], transformAftMapped[1]),Point3(transformAftMapped[5], transformAftMapped[3], transformAftMapped[4])));
}
6)更新isam和计算位姿
/*** update iSAM*/
isam->update(gtSAMgraph, initialEstimate);
isam->update();
gtSAMgraph.resize(0);
initialEstimate.clear();
/** save key poses*/
PointType thisPose3D;
PointTypePose thisPose6D;
Pose3 latestEstimate;
isamCurrentEstimate = isam->calculateEstimate();//计算出最终矫正后结果存放的地方
7)访问最终矫正后的位姿
int numPoses = isamCurrentEstimate.size();
for (int i = 0; i < numPoses; ++i)
{
cloudKeyPoses3D->points[i].x = isamCurrentEstimate.at<Pose3>(i).translation().y();
cloudKeyPoses3D->points[i].y = isamCurrentEstimate.at<Pose3>(i).translation().z();
cloudKeyPoses3D->points[i].z = isamCurrentEstimate.at<Pose3>(i).translation().x();
cloudKeyPoses6D->points[i].x = cloudKeyPoses3D->points[i].x;
cloudKeyPoses6D->points[i].y = cloudKeyPoses3D->points[i].y;
cloudKeyPoses6D->points[i].z = cloudKeyPoses3D->points[i].z;
cloudKeyPoses6D->points[i].roll = isamCurrentEstimate.at<Pose3>(i).rotation().pitch();
cloudKeyPoses6D->points[i].pitch = isamCurrentEstimate.at<Pose3>(i).rotation().yaw();
cloudKeyPoses6D->points[i].yaw = isamCurrentEstimate.at<Pose3>(i).rotation().roll();
}
4. 参考链接
https://blog.csdn.net/Curryfun/article/details/105894863
https://blog.csdn.net/qq_42731705/article/details/120723600
https://blog.csdn.net/ljtx200888/article/details/114278683
https://xiaotaoguo.com/p/ceres-usage/
https://blog.csdn.net/Walking_roll/article/details/119817174
https://blog.csdn.net/lzy6041/article/details/107658568



评论(0)
您还未登录,请登录后发表或查看评论