

机器学习之超参数优化 - 网格优化方法(随机网格搜索)
在讲解网格搜索时我们提到,伴随着数据和模型的复杂度提升,网格搜索所需要的时间急剧增加。以随机森林算法为例,如果使用过万的数据,搜索时间则会立刻上升好几个小时。因此,我们急需寻找到一种更加高效的超参数搜索方法。
首先,当所使用的算法确定时,决定枚举网格搜索运算速度的因子一共有两个:
1 参数空间的大小:参数空间越大,需要建模的次数越多
2 数据量的大小:数据量越大,每次建模时需要的算力和时间越多
因此,sklearn中的网格搜索优化方法主要包括两类,其一是调整搜索空间,其二是调整每次训练的数据。其中,调整参数空间的具体方法,是放弃原本的搜索中必须使用的全域超参数空间,改为挑选出部分参数组合,构造超参数子空间,并只在子空间中进行搜索。
以下图的二维空间为例,在这个n_estimators与max_depth共同组成的参数空间中,n_estimators的取值假设为[50,100,150,200,250,300],max_depth的取值假设为[2,3,4,5,6],则枚举网格搜索必须对30种参数组合都进行搜索。当我们调整搜索空间,我们可以只抽样出橙色的参数组合作为“子空间”,并只对橙色参数组合进行搜索。如此一来,整体搜索所需的计算量就大大下降了,原本需要30次建模,现在只需要8次建模。
在sklearn中,随机抽取参数子空间并在子空间中进行搜索的方法叫做随机网格搜索RandomizedSearchCV。由于搜索空间的缩小,需要枚举和对比的参数组的数量也对应减少,整体搜索耗时也将随之减少,因此:
当设置相同的全域空间时,随机搜索的运算速度比枚举网格搜索快很多。
当设置相同的训练次数时,随机搜索可以覆盖的空间比枚举网格搜索大很多。
同时,绝妙的是,随机网格搜索得出的最小损失与枚举网格搜索得出的最小损失很接近。
可以说,是提升了运算速度,又没有过多地伤害搜索的精度。
不过,需要注意的是,随机网格搜索在实际运行时,并不是先抽样出子空间,再对子空间进行搜索,而是仿佛“循环迭代”一般,在这一次迭代中随机抽取1组参数进行建模,下一次迭代再随机抽取1组参数进行建模,由于这种随机抽样是不放回的,因此不会出现两次抽中同一组参数的问题。我们可以控制随机网格搜索的迭代次数,来控制整体被抽出的参数子空间的大小,这种做法往往被称为“赋予随机网格搜索固定的计算量,当全部计算量被消耗完毕之后,随机网格搜索就停止”。
- 抽样出的子空间可以一定程度上反馈出全域空间的分布,且子空间相对越大(含有的参数组合数越多),子空间的分布越接近全域空间的分布
- 当全域空间本身足够密集时,很小的子空间也能获得与全域空间相似的分布
- 如果全域空间包括了理论上的损失函数最小值,那一个与全域空间分布高度相似的子空间很可能也包括损失函数的最小值,或包括非常接近最小值的一系列次小值
因此,只要子空间足够大,随机网格搜索的效果一定是高度逼近枚举网格搜索的。在全域参数空间固定时,随机网格搜索可以在效率与精度之间做权衡。子空间越大,精度越高,子空间越小,效率越高。
- 更大/更密集的全域空间
不过,由于随机网格搜索计算更快,所以在相同计算资源的前提下,我们可以对随机网格搜索使用更大的全域空间,因此随机搜索可能得到比网格搜索更好的效果:
class sklearn.model_selection.RandomizedSearchCV(estimator, param_distributions, *, n_iter=10, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, random_state=None, error_score=nan, return_train_score=False)
全部参数解读如下,其中加粗的是随机网格搜索独有的参数:
| Name | Description |
|---|---|
| estimator | 调参对象,某评估器 |
| param_distributions | 全域参数空间,可以是字典或者字典构成的列表 |
| n_iter | 迭代次数,迭代次数越多,抽取的子参数空间越大 |
| scoring | 评估指标,支持同时输出多个参数 |
| n_jobs | 设置工作时参与计算的线程数 |
| refit | 挑选评估指标和最佳参数,在完整数据集上进行训练 |
| cv | 交叉验证的折数 |
| verbose | 输出工作日志形式 |
| pre_dispatch | 多任务并行时任务划分数量 |
| random_state | 随机数种子 |
| error_score | 当网格搜索报错时返回结果,选择’raise’时将直接报错并中断训练过程,其他情况会显示警告信息后继续完成训练 |
| return_train_score | 在交叉验证中是否显示训练集中参数得分 |
import numpy as np
import pandas as pd
import sklearn
import matplotlib as mlp
import matplotlib.pyplot as plt
import seaborn as sns
import time
import re, pip, conda
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import cross_validate, KFold,RandomizedSearchCV
data = pd.read_csv(r"../datasets/House Price/train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
#创造参数空间 - 使用与网格搜索时完全一致的空间,以便于对比
param_grid_simple = {"criterion": ["squared_error","poisson"]
, 'n_estimators': [*range(20,100,5)]
, 'max_depth': [*range(10,25,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
, "min_impurity_decrease": [*np.arange(0,5,10)]
}
#建立回归器、交叉验证
reg = RFR(random_state=1412,verbose=True,n_jobs=-1)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
#定义随机搜索
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 800 #子空间的大小是全域空间的一半左右
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,random_state=1412
,n_jobs=-1
)
#训练随机搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
search.best_estimator_
abs(search.best_score_)**0.5
#根据最优参数重建模型
ad_reg = RFR(max_depth=24, max_features=16, min_impurity_decrease=0,
n_estimators=85, n_jobs=-1, random_state=1412,
verbose=True)
rebuild_on_best_param(ad_reg)
| HPO方法 | 默认参数 | 网格搜索 | 随机搜索 |
|---|---|---|---|
| 搜索空间/全域空间 | - | 1536/1536 | 800/1536 |
| 运行时间(分钟) | - | 6.36 | 2.83(↓) |
| 搜索最优(RMSE) | 30571.266 | 29179.698 | 29251.284 |
| 重建最优(RMSE) | - | 28572.070 | 28639.969(↑) |
很明显,在相同参数空间、相同模型的情况下,随机网格搜索的运算速度是普通网格搜索的一半,当然,这与子空间是全域空间的一半有很大的联系。由于随机搜索只是降低搜索的次数,并非影响搜索过程本身,因此其运行时间基本就等于n_iter/全域空间组合数 * 网格搜索的运行时间。
随机网格搜索的理论极限
虽然通过缩小子空间可以提升搜索的速度,但是随机网格搜索的精度看起来并没有削减太多,随机网格搜索可以得到和网格搜索一样好的结果吗?它也像网格搜索一样,可以得到最优的参数组合吗?为什么缩小参数空间之后,随机网格搜索的结果还与网格搜索一致?
理论上来说,枚举网格搜索的上限和随机网格搜索的上限哪个高?
从直觉上来说,我们很难回答这些问题,但我们可以从数学的随机过程的角度来理解这个问题。在机器学习算法当中,有非常多通过随机来提升运算速度(比如Kmeans,随机挑选样本构建簇心,小批量随机梯度下降,通过随机来减少每次迭代需要的样本)、或通过随机来提升模型效果的操作(比如随机森林,比如极度随机树)。两种随机背后的原理完全不同,而随机网格搜索属于前者,这一类机器学习方法总是伴随着“从某个全数据集/全域中进行抽样”的操作,而这种操作能够有效的根本原因在于:
- 抽样出的子空间可以一定程度上反馈出全域空间的分布,且子空间相对越大(含有的参数组合数越多),子空间的分布越接近全域空间的分布
- 当全域空间本身足够密集时,很小的子空间也能获得与全域空间相似的分布
- 如果全域空间包括了理论上的损失函数最小值,那一个与全域空间分布高度相似的子空间很可能也包括损失函数的最小值,或包括非常接近最小值的一系列次小值
#创造参数空间 - 让整体参数空间变得更密
param_grid_simple = {'n_estimators': [*range(80,100,1)]
, 'max_depth': [*range(10,25,1)]
, "max_features": [*range(10,20,1)]
, "min_impurity_decrease": [*np.arange(0,5,10)]
}
#建立回归器、交叉验证
reg = RFR(random_state=1412,verbose=True,n_jobs=-1)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
#定义随机搜索
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 1536 #使用与枚举网格搜索类似的拟合次数
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,random_state=1412
,n_jobs=-1)
#训练随机搜索评估器
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
end = time.time() - start
print(end/60)
#查看最佳评估器
search.best_estimator_
#查看最终评估指标
abs(search.best_score_)**0.5
rebuild_on_best_param(search.best_estimator_)| HPO方法 | 默认参数 | 网格搜索 | 随机搜索 | 随机搜索 (大空间) |
|---|---|---|---|---|
| 搜索空间/全域空间 | - | 1536/1536 | 800/1536 | 1536/3000 |
| 运行时间(分钟) | - | 6.36 | 2.83(↓) | 3.86(↓) |
| 搜索最优(RMSE) | 30571.266 | 29179.698 | 29251.284 | 29012.905(↓) |
| 重建最优(RMSE) | - | 28572.070 | 28639.969(↑) | 28346.673(↓) |
可以发现,当全域参数空间增大之后,随即网格搜索可以使用与小空间上的网格搜索相似或更少的时间,来探索更密集/更大的空间,从而获得更好的结果。除了可以容忍更大的参数空间之外,随机网格搜索还可以接受连续性变量作为参数空间的输入。
连续型的参数空间
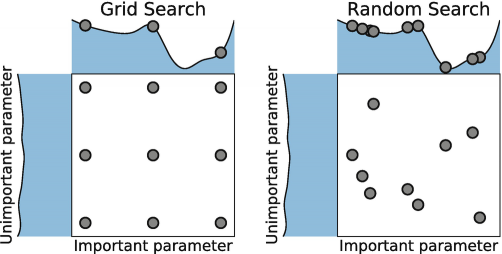
对于网格搜索来说,参数空间中的点是分布均匀、间隔一致的,因为网格搜索无法从某种“分布”中提取数据,只能使用组合好的参数组合点,而随机搜索却可以接受“分布”作为输入。如上图所示,对于网格搜索来说,损失函数的最低点很不幸的、位于两组参数之间,在这种情况下,枚举网格搜索是100%不可能找到最小值的。但对于随机网格搜索来说,由于是一段分布上随机选择参数点,因此在同样的参数空间中,取到更好的值的可能性更大。



评论(1)
您还未登录,请登录后发表或查看评论