

一、每处理器
在多处理器系统中,每处理器变量为每个处理器生成一个变量副本,每个处理器访问自己的副本;
优点:避免处理器之间和处理器缓存之间的同步,提高程序的执行速度。
二、编程接口
1、静态
DEFINE_PER_CPU(type,name);//定义
DECLARE_PER_CPU(type,name);//声明
宏定义展开
_ attribute ((section(".data .. percpu"))) _ typeof_ (type) name
每处理器变量放在.data..percpu中
DEFINE_PER_CPU_FIRST(type, name) ;//定义必须出现在每处理器变量集合中最先出现的每处理器变量
DEFINE_PER_CPU_SHARED_ALLGNED(type,name);//定义和处理器缓存行对齐的每处理器变量,仅在SMP系统中需要
DEFINE_PER_CPU_ALLGNED(type,name);//定义和处理器缓存行对齐的每处理器变量,都需要对齐
DEFINE_PER_CPU_PAGE_ALIGNED(type,name);//定义和页长度对齐的每处理器变量;
DEFINE_PER_CPU_READ_MOSTLY(type,name)定义以读为主的每处理器变量;
允许任何模块引用 EXPORT_PER_CPU_SYMBOL(var);把静态每处理器变量导出到符号表;
只允许使用GPL许可的内核模块引用,使用EXPORT_PER_CPU_SYMBOL_GPL(var)
2、动态
void _percpu•_ alloc_percpu_gfp (size size, size_t align, gfp t gfp);
宏 alloc_percpu_gfp(type,gfp),是上一个的简化形式,参数size取sizeof(type);
_alloc_percpu
宏 alloc_percpu(type)是函数__alloc_percpu 的简化形式
//常用
alloc__percpu(type)
//释放
void free_percpu(void _percpu *_pdata);
3、访问每处理器变量
宏 this_cpu_ptr(ptr)用来得到当前处理器的变量副本的地址,展开如下;
unsigned long _ ptr;
_ptr = (unsigned long) (ptr);
(typeof (ptr)) (_ptr + percpu_offset (raw_smp_processor_id ()));
当前处理器的变量副本的地址等于基准地址加上当前处理器的偏移;
宏 get_cpu_var(var)用来得到当前处理器的变量副本的值;
per_cpu_ptr(ptr, cpu) 用来得到指定处理器的变量副本的地址;
per_cpu(var,cpu)用来得到指定处理器的变量副本的值;
get_cpu_ptr(var) 禁止内核抢占并且返回当前处理器的变量副本的地址;
put_cpu_ptr(var)开启内核抢占;与上一个成对使用,确保当前进程在内核模式下访问当前处理器的变量副本的时候不会被其他进程抢占
get_cpu_var(var) 禁止内核抢占并且返回当前处理器的变量副本的值,
pur_cpu_var(var) 开启内核抢占;与上一个成对使用,确保当前访问处理器变量副本的时候不会被其他进程抢占
三、每处理器的内存如何分配的
每处理器区域是按块分配的,每个块分为多个长度相同的单元(unit),每个处理器对应一个单元;
在NUMA系统上,把单元按内存节点分组,同一个内存节点的所有处理器对应的单元属于同一组;
块分配
1、vmalloc;从虚拟地址空间分配虚拟内存区域,然后映射到物理页;适用于 多处理器系统
2、基于内核内存的块分配。直接从页分配器分配,使用直接映射的内核虚拟地址;适用于单处理器系统
this_cpu_ptr(ptr)访问每处理器变量,ptr是每处理器变量分配内存时返回的虚拟地址;
this_cpu_ptr (ptr)
= ptr + __per_cpu offset[cpu] ;• cpu是当前处理器的编号*/
= ptr +(delta+ pcpu_unit_offsets[cpu])
= (ptr + delta) + pcpu unit offsets[cpu]
= (chunk->base addr + offset) + pcpu_unit_offse 七 s[cpu]
= (chunk->base_addr + pcpu_unit_offsets[cpu]) + offset
pcpu_unit_offsets[cpu]是处理器对应的单元的偏移;
chunk->base_addr + pcpu_unit_offsets[cpu] 处理器对应单元的起始地址
offset 内部单元的偏移,就是变量副本的地址
分配图,放在每个小块的偏移和分配状态,使用最低位表示小块的分配状态;
假设系统有4个处理器,一个块分为4个单元,
分配图的初始状态,第一项存放第一个小块的偏移0,空闲,第二项存放单元的结束标记,偏移单元长度pcpu_unit_size,最低位被设置;块的初始状态,空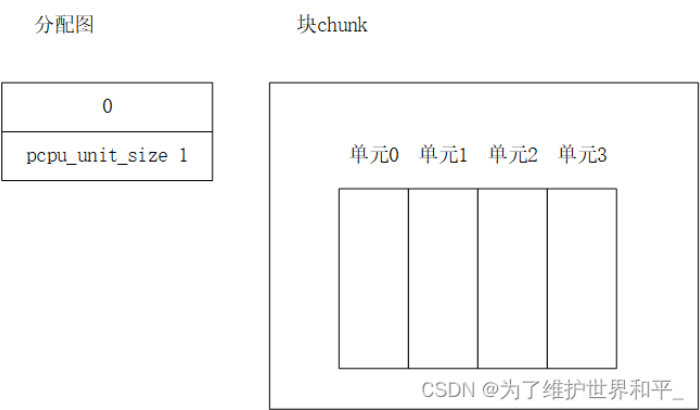
分配一个长度32字节的动态每处理器变量以后,
分配图使用三项:第一项存放第一个小块的偏移0,已分配;第二块存放第二个小块的偏移32,空闲;第三项存放单元的结束标记,偏移是单元长度pcpu_uint_size,最低被设置。
块的状态,每个单元中偏移0,长度32字节的小块被分配出去;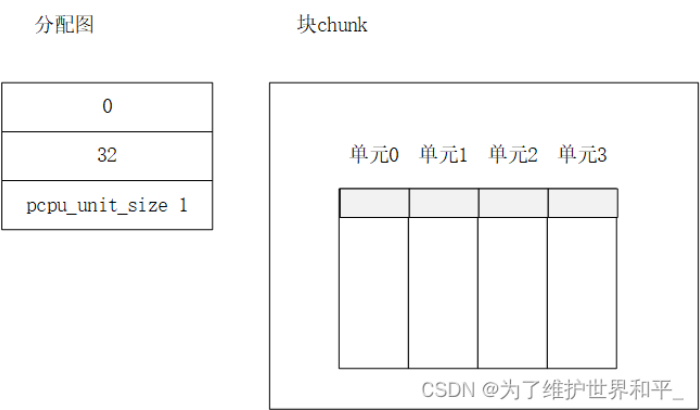
分配器根据空闲长度把块组织成链表,把每条链表称为块插槽,插槽数量是pcpu_nr_slots,
1、根据长度n计算插槽号的方法
1、如果空闲长度小于整数长度,或者最大的连续空闲字节数小于整数长度,那么插槽号是0;
2、如果块全部空闲,那么取最后一个插槽号,即pcpu_nr_slots - 1
3、其他情况:插槽号 = fln(n) - 3,并且不能小于1,fls(n)取n被设置的最高位。减3的目的是让空闲长度是1~15字节的块共享插槽1
2、确定块的参数
start_kernel -> setup__per_cpu_areas -> pcpu_embed_first_chunk -> pcpu_build_alloc i nfo
pcpu_build_alloc_info 计算分组信息和单元长度;
- 静态长度:内核中所有静态每处理器变量的长度总和;数据段结束地址 - 起始地址 即(per_cpu_end - per_cpu_start)
- 保留长度:为内核模块的静态每处理器变量保留,使用宏PERCPU_MODULE_RESERVE定义,值是8KB
- 动态长度:为动态每处理器准备,使用宏PERCPU_DYNAMIC_RESERVE定义,在64位系统中值是28KB
size_sum = 静态长度 + 保留长度 + 动态长度
最小单元长度 min_unit_size = size_sum,并且不允许小于宏PCPU_MIN_UNIT_SIZE 值是32KB
分配长度 alloc_size = min_unit_size向上对齐到原子长度的整数倍,原子长度是页长度;
最大倍数 max = alloc_size / min_unit_size
单元长度 = alloc_size / 倍数 n,需要从最大倍数max到最小倍数1中找到一个最优的倍数n
学习链接:
参考
https://course.0voice.com/v1/course/intro?courseId=2&agentId=0
")


评论(0)
您还未登录,请登录后发表或查看评论