
第十课训练机械臂时,把PPO算法换成DDPG后,一直出现warning:Warning: could not pickle state_dict. 我其他参数都没有改变,代码截图如下,已经研究好几天无法解决了,求老师帮忙看看!!!万分感谢!!!
from spinup import ppo_pytorch as ppo
from spinup import ddpg_pytorch as ddpg
from UR5_Controller import UR5_Controller
from spinup.utils.test_policy import load_policy_and_env, run_policy
import torch
TRAIN = 1
target = [0, -1.57, 1.57, 0, 0, 0]
env = lambda : UR5_Controller(target)
if TRAIN:
ac_kwargs = dict(hidden_sizes=[128,128,128], activation=torch.nn.ReLU)
logger_kwargs = dict(output_dir='log', exp_name='ur5_goToTarget')
ddpg(env, ac_kwargs=ac_kwargs, logger_kwargs=logger_kwargs,
steps_per_epoch=2000, epochs=4000)
else:
_, get_action = load_policy_and_env('log')
env_test = UR5_Controller(target)
run_policy(env_test, get_action)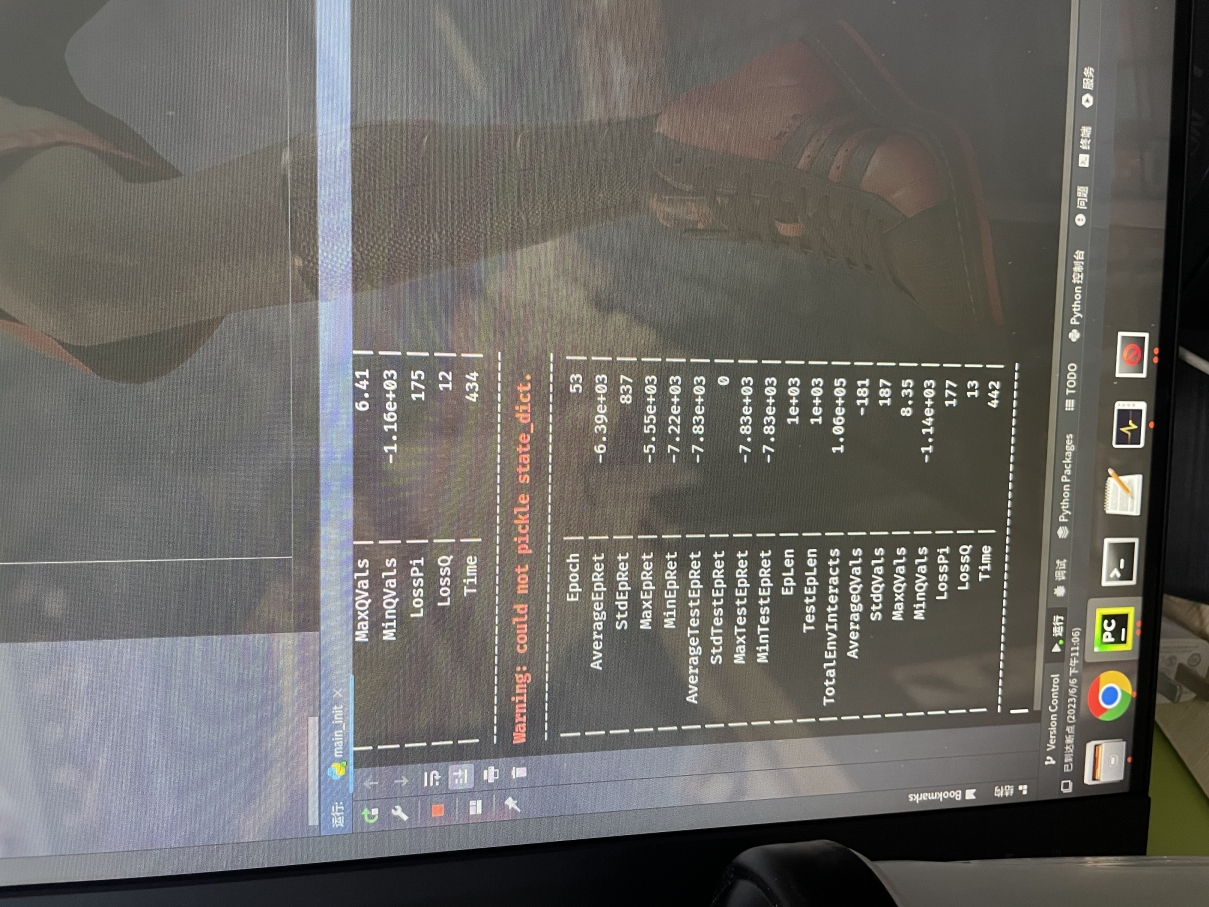




第三方账号登入
QQ 微博 微信