

使用DDPG训练摆锤系统
- 打开模型并创建环境接口
- 创建DDPG智能体
- 训练智能体
- DDPG仿真
此示例显示了如何建立钟摆模型并使用DDPG训练。
模型加载参考我上一篇使用DQN的博文。
打开模型并创建环境接口
打开模型
mdl = 'rlSimplePendulumModel';
open_system(mdl)
为钟摆创建一个预定义的环境界面。
env = rlPredefinedEnv('SimplePendulumModel-Continuous')
界面具有离散的操作空间,智能体可以在其中将三个可能的扭矩值之一施加到摆锤上:–2、0或2 N·m。
要将摆的初始条件定义为向下悬挂,请使用匿名函数句柄指定环境重置函数。 此重置功能将模型工作区变量thetaθ \thetaθ设置为pi。
numObs = 3;
set_param('rlSimplePendulumModel/create observations','ThetaObservationHandling','sincos');
要将摆的初始条件定义为向下悬挂,请使用匿名函数句柄指定环境重置函数。此重置功能将模型工作区变量设置theta0为pi。
env.ResetFcn = @(in)setVariable(in,'theta0',pi,'Workspace',mdl);
以秒为单位指定模拟时间Tf和代理采样时间Ts。
Ts = 0.05;
Tf = 20;
固定随机生成器种子以提高可重复性。
rng(0)
创建DDPG智能体
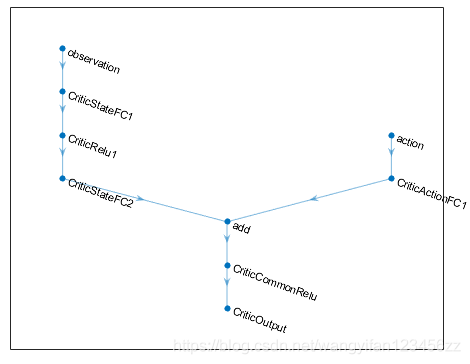
DDPG智能体使用评论者价值函数表示法,根据给定的观察和操作来估算长期奖励。 要创建评论者,首先要创建一个具有两个输入(状态和动作)和一个输出的深度神经网络。 有关创建深度神经网络值函数表示的更多信息,请参见创建策略和值函数表示。
statePath = [
featureInputLayer(numObs,'Normalization','none','Name','observation')
fullyConnectedLayer(400,'Name','CriticStateFC1')
reluLayer('Name', 'CriticRelu1')
fullyConnectedLayer(300,'Name','CriticStateFC2')];
actionPath = [
featureInputLayer(1,'Normalization','none','Name','action')
fullyConnectedLayer(300,'Name','CriticActionFC1','BiasLearnRateFactor',0)];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','CriticOutput')];
criticNetwork = layerGraph();
criticNetwork = addLayers(criticNetwork,statePath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticStateFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActionFC1','add/in2');
查看评论者网络配置。
figure
plot(criticNetwork)
使用rlRepresentationOptions指定评论者表示的选项。
criticOpts = rlRepresentationOptions('LearnRate',1e-03,'GradientThreshold',1);
使用指定的深度神经网络和选项创建评论者表示。 您还必须指定评论者的操作和观察信息,这些信息是从环境界面获得的。 有关更多信息,请参见rlQValueRepresentation。
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);
critic = rlQValueRepresentation(criticNetwork,obsInfo,actInfo,'Observation',{'observation'},'Action',{'action'},criticOpts);
要创建一个具有一个输入(观察)和一个输出(动作)的深度神经网络。
以类似于评论者的方式构造行动者。 有关更多信息,请参见rlDeterministicActorRepresentation。
actorNetwork = [
featureInputLayer(numObs,'Normalization','none','Name','observation')
fullyConnectedLayer(400,'Name','ActorFC1')
reluLayer('Name','ActorRelu1')
fullyConnectedLayer(300,'Name','ActorFC2')
reluLayer('Name','ActorRelu2')
fullyConnectedLayer(1,'Name','ActorFC3')
tanhLayer('Name','ActorTanh')
scalingLayer('Name','ActorScaling','Scale',max(actInfo.UpperLimit))];
actorOpts = rlRepresentationOptions('LearnRate',1e-04,'GradientThreshold',1);
actor = rlDeterministicActorRepresentation(actorNetwork,obsInfo,actInfo,'Observation',{'observation'},'Action',{'ActorScaling'},actorOpts);
要创建DDPG智能体,请首先使用rlDDPGAgentOptions指定DDPG代理选项。
agentOpts = rlDDPGAgentOptions(...
'SampleTime',Ts,...
'TargetSmoothFactor',1e-3,...
'ExperienceBufferLength',1e6,...
'DiscountFactor',0.99,...
'MiniBatchSize',128);
agentOpts.NoiseOptions.Variance = 0.6;
agentOpts.NoiseOptions.VarianceDecayRate = 1e-5;
然后使用指定的行动者表示,评论者表示和智能体选项创建DDPG智能体。 有关更多信息,请参见rlDDPGAgent。
agent = rlDDPGAgent(actor,critic,agentOpts);
训练智能体
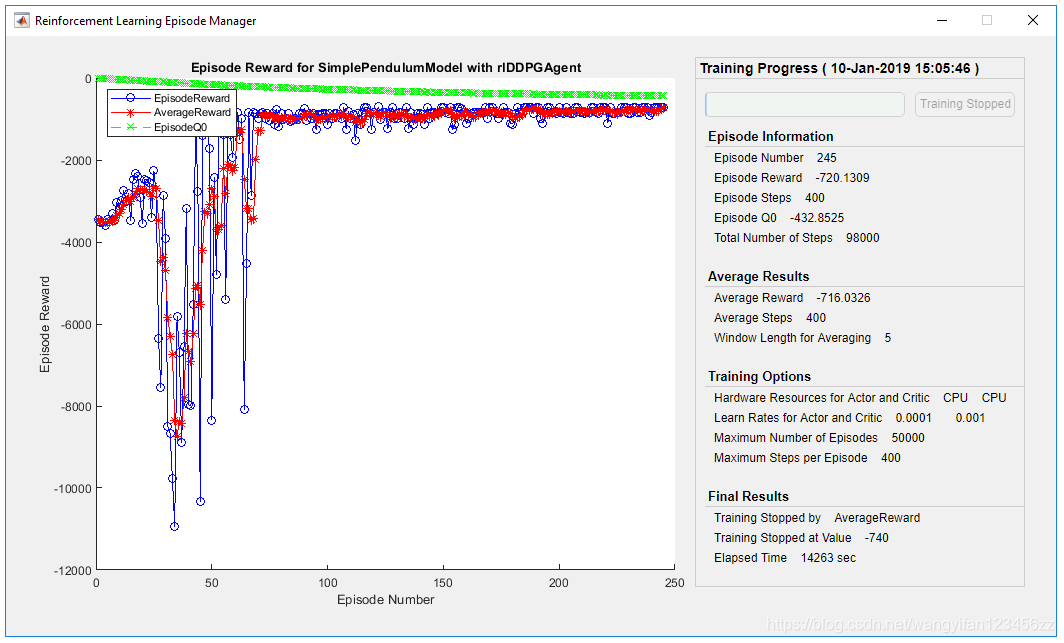
要训练智能体,请首先指定训练选项。对于此示例,使用以下选项。
进行最多50000次的训练,每集持续最多的ceil(Tf/Ts)时间步长。
在“情节管理器”对话框中显示训练进度(设置Plots选项),并禁用命令行显示(将Verbose选项设置为false)。
当特工连续五个情节获得的平均累积奖励大于–740时,请停止训练。在这一点上,代理可以以最小的控制力快速地使摆锤处于直立位置。
为累积奖励大于–740的每个情节保存代理的副本。
有关更多信息,请参见rlTrainingOptions。
maxepisodes = 5000;
maxsteps = ceil(Tf/Ts);
trainOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'ScoreAveragingWindowLength',5,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',-740,...
'SaveAgentCriteria','EpisodeReward',...
'SaveAgentValue',-740);
使用训练函数训练智能体。 训练此智能体是一个计算密集型过程,需要几分钟才能完成。 为了节省运行本示例的时间,请通过将doTraining设置为false来加载预训练的智能体。 要自己训练智能体,请将doTraining设置为true。
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainOpts);
else
% Load the pretrained agent for the example.
load('SimulinkPendulumDDPG.mat','agent')
end
DDPG仿真
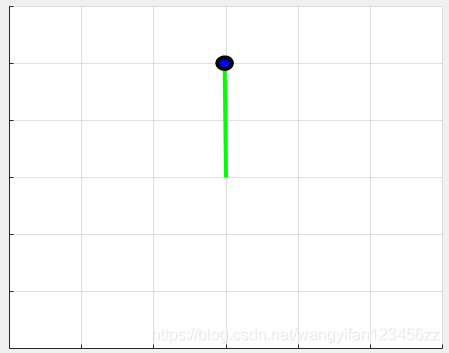
要验证以训练的智能体的表现,请在摆环境中对其进行仿真。 有关智能体模拟的更多信息,请参见rlSimulationOptions和sim。
simOptions = rlSimulationOptions('MaxSteps',500);
experience = sim(env,agent,simOptions);




评论(0)
您还未登录,请登录后发表或查看评论