

这里主要通过对人脸的分析,得出,年龄,性别,种族,表情,魅力值等属性。
所有的这些问题中,有分类问题也有回归问题,准确的说是一个多标签的分类+回归问题。
对于多标签问题,对于caffe有2种处理思路,一种是使用HDF5格式,另一种就是修改caffe源码。
1.数据准备
这里同时进行2种方式的说明。
(1)修改源码,主要修改cafferoot/tools/convert_imageset.cpp。使得其支持多标签的读取。下载链接:http://download.csdn.net/detail/qq_14845119/9864928
修改完,重新编译后,caffe的LMDB读取方式就支持多标签了。这里将需要分类的标签都存储在LMDB中。
生成图片和用于分类的标签的LMDB
../../build/tools/convert_imageset --resize_height=96 --resize_width=96 /dataSet/myPIC/img_align_96_96/ /dataSet/myPIC/train_class.txt ./img_train_lmdb ./img_train_label_lmdb 5
../../build/tools/convert_imageset --resize_height=96 --resize_width=96 /dataSet/myPIC/img_align_96_96/ /dataSet/myPIC/val_class.txt ./img_val_lmdb ./img_val_label_lmdb 5
(2)将用于回归的标签存储在HDF5中,因为HDF5支持小数格式的标签。例如将年龄,魅力值存储在HDF5中,
traindata=importdata('/dataSet/myPIC/train_regress.txt');
valdata=importdata('/dataSet/myPIC/val_regress.txt');
traindata=traindata/100;
valdata=valdata/100;
% train
h5create('train.h5','/label_age',[1 size(traindata,1)],'Datatype','single');
h5create('train.h5','/label_attractive',[1 size(traindata,1)],'Datatype','single');
age_label = reshape(traindata(:,1),[1 size(traindata,1)]);
attractive_label = reshape(traindata(:,2),[1 size(traindata,1)]);
h5write('train.h5' ,'/label_age', single(age_label));
h5write('train.h5' ,'/label_attractive', single(attractive_label));
% val
h5create('val.h5','/label_age',[1 size(valdata,1)],'Datatype','single');
h5create('val.h5','/label_attractive',[1 size(valdata,1)],'Datatype','single');
age_label = reshape(valdata(:,1),[1 size(valdata,1)]);
attractive_label = reshape(valdata(:,2),[1 size(valdata,1)]);
h5write('val.h5' ,'/label_age', single(age_label));
h5write('val.h5' ,'/label_attractive', single(attractive_label));
2.网络设计
网络结构图,

3.开始训练
下面就可以进行训练操作了,
../../build/tools/caffe train --solver=solver.prototxt --gpu=0
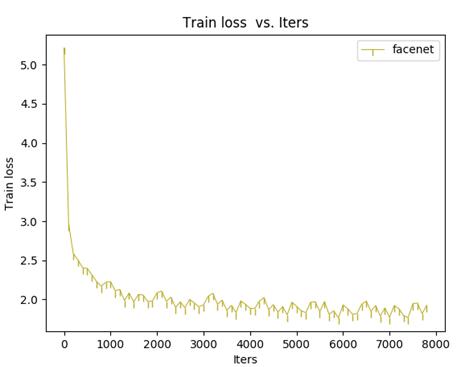
从曲线上还是可以看出数据不够干净,有噪声在里面,不过整体还是很会的收敛了。
4.实验效果:

————————————————



评论(0)
您还未登录,请登录后发表或查看评论