

自2012年深度学习火起来后,AlexNet,vgg16,vgg19,gooGleNet,caffeNet,faster RCNN等,各种模型层出不群,颇有文艺复兴时的形态。
在各种顶会论文中,对年龄和性别的检测的论文还是比较少的。而本文将要讲解的是2015年的一篇cvpr,Age and Gender Classification using Convolutional Neural Networks。官方链接为http://www.openu.ac.il/home/hassner/projects/cnn_agegender/
理论基础:
其整体结构如下图所示,输入一幅图片,然后经过3个卷基层,2个全链接层,最后经过svm分类器分类,输出相应的结果。

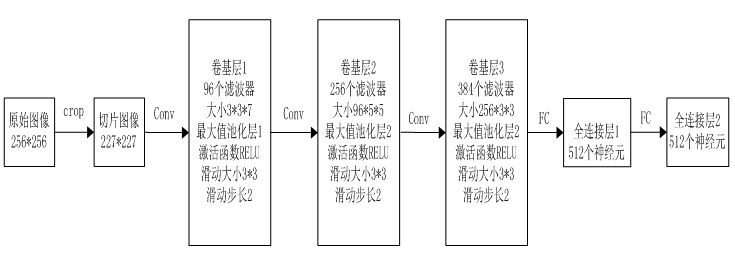
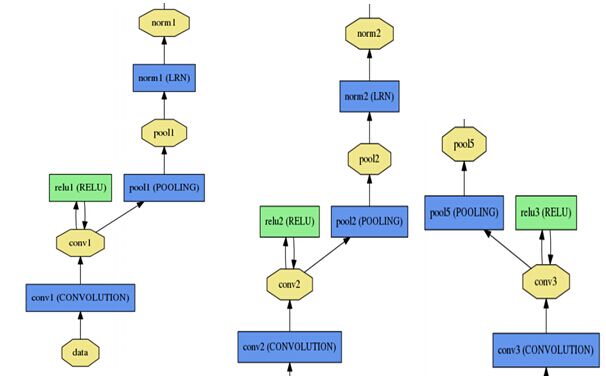
详细结构如下图所示,其中norm层为了提高模型的泛化能力,drop层是为了防止过拟合。
其中左中右分别为第一二三个卷基层,下面的为第六七八个全连接层。
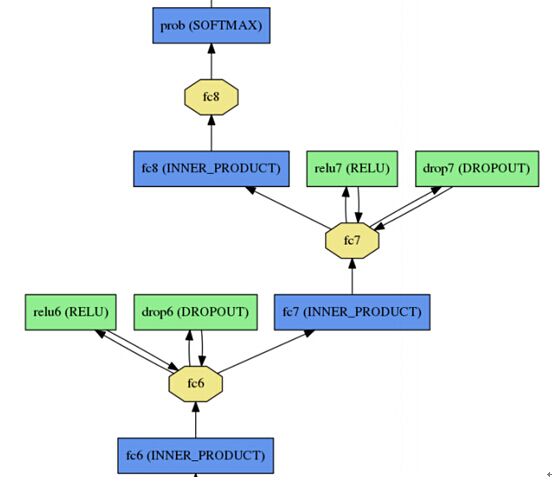
程序运行:
可以写一个简单的shell脚本来进行运行测试,touch一个.sh文件,随便起个名字,输入如下的脚本,然后命令行运行就可以输出结果。其中路径名换成自己电脑的实际路径名。
#!/bin/bash
#directed by watersink(watersink2016@gmail.com)
echo "Begin gender....."
./build/examples/cpp_classification/classification.bin \
models/cnn_age_gender/deploy_gender.prototxt \
models/cnn_age_gender/gender_net.caffemodel \
data/cnn_age_gender/mean.binaryproto \
data/cnn_age_gender/genderlabels.txt \
data/cnn_age_gender/example_image.jpg
echo "Begin age....."
./build/examples/cpp_classification/classification.bin \
models/cnn_age_gender/deploy_age.prototxt \
models/cnn_age_gender/age_net.caffemodel \
data/cnn_age_gender/mean.binaryproto \
data/cnn_age_gender/agelabels.txt \
data/cnn_age_gender/example_image.jpg
echo "Done.
classification.bin为caffe自带的二进制文件,用于实现分类。
deploy_gender.prototxt,deploy_age.prototxt分别为性别,年龄部署或者测试时候的模型文件
gender_net.caffemodel,age_net.caffemodel分别为性别,年龄训练好的权值文件
mean.binaryproto,为训练的样本的均值文件,减均值时使用,可以达到更好的检测效果
genderlabels.txt,agelabels.txt为性别,年龄的标签文件,具体内容如下
genderlabels.txt中的内容:
male 1
female 0agelabels.txt中的内容:
0-2 0
4-6 1
8-13 2
15-20 3
25-32 4
38-43 5
48-53 6
60- 7
example_image.jpg,为随便一张想要测试的图片
实验结果:
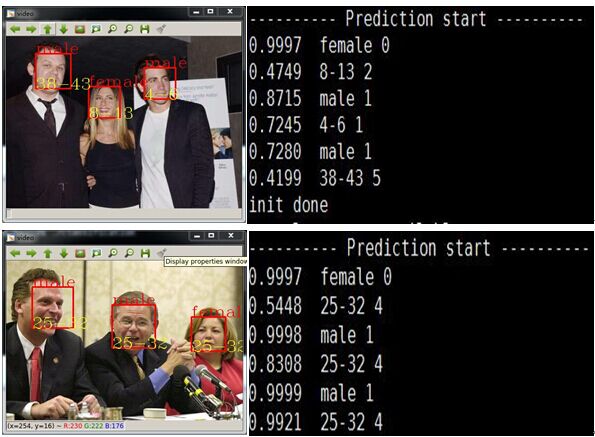
性别识别率:

年龄识别率:
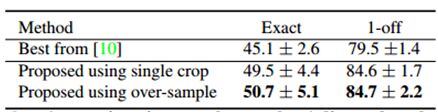
训练自己的模型:
论文的原作者给出了自己的5-folder训练文件,首先我们对原作者的训练数据进行分析。
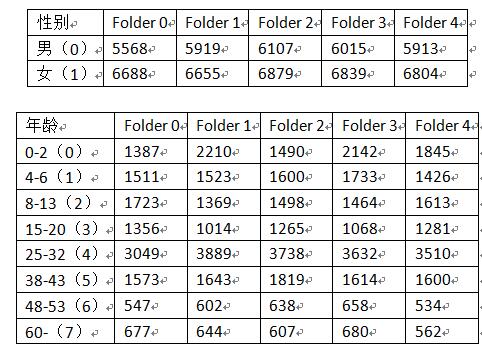
通过上面的数据可以看出,性别数据反面基本是1:1比例进行的。而年龄方面并没有执行大概的1:1:1:1:1:1:1:1比例,而是3:3:3:3:6:3:1:1,对于这样的训练比例,我个人认为是很不科学和合理的,所谓的mini-batch,应该是每个batch中的属性和整体的基本是一样的才可以。
简单的说,任意给一张图像,这张图像中人物属于哪一个年龄段是都有可能的,也就是是平均概率的。(个人见解,如有错误,希望大家指正)
下面通过一个简单的c++程序来获得和作者一样的txt文件。
int main()
{
vector<string>file_folder;
file_folder.push_back("fold_0_data.txt");
file_folder.push_back("fold_1_data.txt");
file_folder.push_back("fold_2_data.txt");
file_folder.push_back("fold_3_data.txt");
file_folder.push_back("fold_4_data.txt");
ofstream file_stream_gender_out("gender.txt", ios::app);
ofstream file_stream_age_out("age.txt", ios::app);
char buffer[500];
char str1[50], str2[50], str3[50], str4[50], str5[50], str6[50];
for (int i = 0; i < file_folder.size();i++)
{
ifstream file_stream_in(file_folder[i]);
file_stream_in.getline(buffer, 400);//提取标题
while (!file_stream_in.eof())
{
file_stream_in.getline(buffer,400);
sscanf(buffer, "%s %s %s %s %s %s", &str1, &str2, &str3, &str4, &str5, &str6);
string tmp1 = str3, tmp2 = str2;
string address = "F:\\MydataSet\\Adience\\aligned\\landmark_aligned_face." + tmp1 + "." + tmp2;
Mat image = imread(address);
if (image.data)
{
if (str4[0] == '(')
file_stream_age_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str4 << " " << str5 << endl;
if (strcmp(str6, "f") == 0 || strcmp(str6, "m") == 0 )
file_stream_gender_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str6<<endl;
else
{
if(strcmp(str5, "f") == 0 || strcmp(str5, "m") == 0)
file_stream_gender_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str5 << endl;
}
}
}
file_stream_in.close();
}
file_stream_gender_out.close();
file_stream_age_out.close();
return 0;
}int main()
{
vector<string>file_folder;
file_folder.push_back("fold_0_data.txt");
file_folder.push_back("fold_1_data.txt");
file_folder.push_back("fold_2_data.txt");
file_folder.push_back("fold_3_data.txt");
file_folder.push_back("fold_4_data.txt");
ofstream file_stream_gender_out("gender.txt", ios::app);
ofstream file_stream_age_out("age.txt", ios::app);
char buffer[500];
char str1[50], str2[50], str3[50], str4[50], str5[50], str6[50];
for (int i = 0; i < file_folder.size();i++)
{
ifstream file_stream_in(file_folder[i]);
file_stream_in.getline(buffer, 400);//提取标题
while (!file_stream_in.eof())
{
file_stream_in.getline(buffer,400);
sscanf(buffer, "%s %s %s %s %s %s", &str1, &str2, &str3, &str4, &str5, &str6);
string tmp1 = str3, tmp2 = str2;
string address = "F:\\MydataSet\\Adience\\aligned\\landmark_aligned_face." + tmp1 + "." + tmp2;
Mat image = imread(address);
if (image.data)
{
if (str4[0] == '(')
file_stream_age_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str4 << " " << str5 << endl;
if (strcmp(str6, "f") == 0 || strcmp(str6, "m") == 0 )
file_stream_gender_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str6<<endl;
else
{
if(strcmp(str5, "f") == 0 || strcmp(str5, "m") == 0)
file_stream_gender_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str5 << endl;
}
}
}
file_stream_in.close();
}
file_stream_gender_out.close();
file_stream_age_out.close();
return 0;
}程序运行结束后,将会生成age.txt和gender.txt
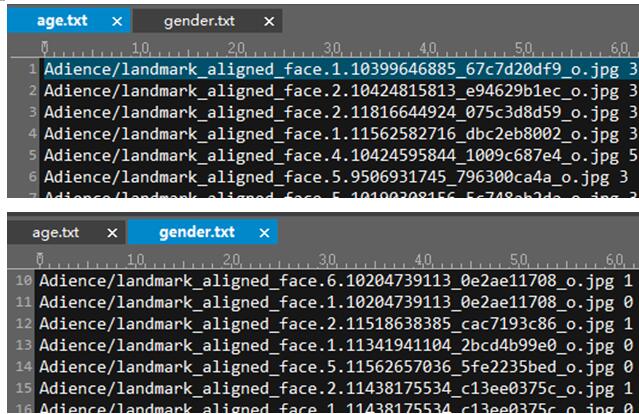
有了这2个文件就可以进行相应的训练工作了。当然为了得到更好的效果,可以考虑以下3点建议。
(1)对txt中的数据平均分配,不要好多相同的标签在一起,如果不这样做的话,需要在输入层设置shuffle,同样可以达到相同的效果。
(2)增加一定的样本,使得年龄的每一个阶段数量都大致相同
(3)将图像缩放到256*256,并做aligement
本人处理后数据如下图所示,大小256*256,做了aligement

将cafferoot/examples/imagenet/ (cafferoot为自己的caffe的根目录)下的create_imagenet.sh,
make_imagenet_mean.sh,train_caffenet.sh复制到自己的工程下,分别改名为,create_age.sh,make_age_mean.sh,train_age.sh,再复制一份,改名为,create_gender.sh,make_gender_mean.sh,train_gender.sh,并对其中的参数做相应的修改。(如果这一步有疑问,请留言)
年龄的训练:
执行create_age.sh,
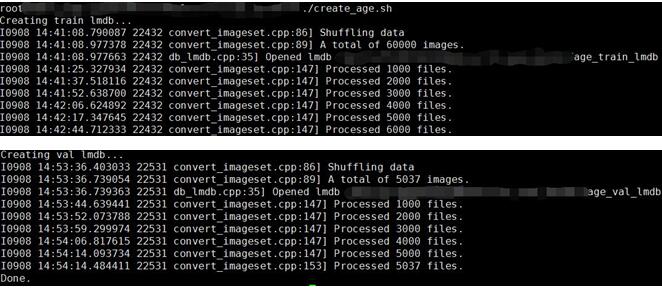
执行,make_age_mean.sh,

执行,train_age.sh,可以看到得到了68.95%的识别率
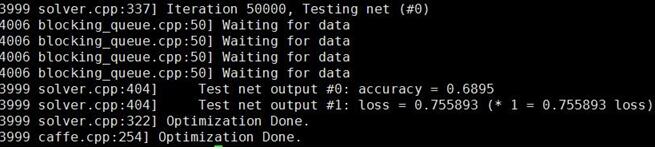
性别的训练:
执行create_gender.sh,
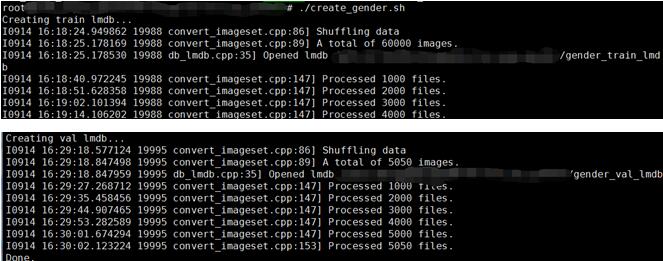
执行,make_gender_mean.sh,

执行,train_gender.sh,可以看到得到了95.75%的识别率
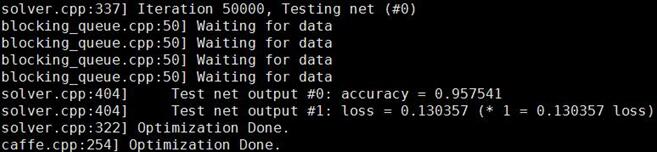
本人实际在ubuntu14.04+corei7cpu+TitanX上跑的cpu进行年龄或者性别判断的时间为150ms左右,gpu的时间为2-3ms左右。
在windows7+XeonE3上测试,cpu+debug为120ms左右,cpu+release为30ms左右。
欢迎大家指证与交流……
————————————————



评论(0)
您还未登录,请登录后发表或查看评论