

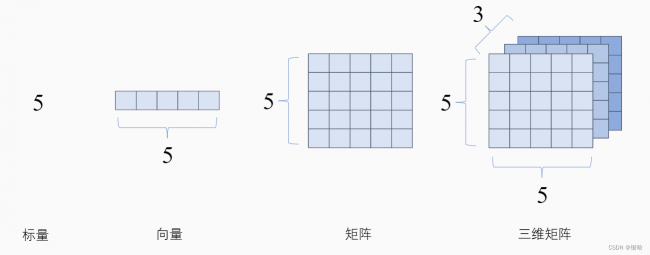
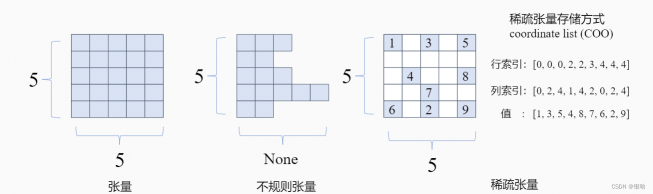
张量
定义:
-
张量是一种特殊的数据结构,与数组和矩阵非常相似。在 PyTorch 中,我们使用张量对模型的输入和输出以及模型的参数进行编码。
-
张量类似于 NumPy 的 ndarrays,不同之处在于张量可以在 GPU 或其他专用硬件上运行以加速计算。
三种方式创建张量Tensor:
直接来自数据
张量可以直接从数据中创建。数据类型是自动推断的。
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)来自 NumPy 数组
可以从 NumPy 数组创建张量
np_array = np.array(data)
x_np = torch.from_numpy(np_array)从另一个张量:
除非明确覆盖,否则新张量保留参数张量的属性(形状、数据类型)。
x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")张量属性
张量属性描述了它们的形状、数据类型和存储它们的设备。
tensor = torch.rand(3, 4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")张量运行
官方文档给出了100多种运算,这里举几个简单且重要的
- 索引和切片
tensor = torch.ones(4, 4)
tensor[:,1] = 0
print(tensor)- 连接
连接张量您可以使用torch.cat它沿给定维度连接一系列张量。另请参阅torch.stack,这是另一个与 op 略有不同的加入 op 的张量torch.cat。
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)- 张量乘法
# This computes the element-wise product
print(f"tensor.mul(tensor) \n {tensor.mul(tensor)} \n")
# Alternative syntax:
print(f"tensor * tensor \n {tensor * tensor}")
计算两个张量之间的矩阵乘法:
print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n")
# Alternative syntax:
print(f"tensor @ tensor.T \n {tensor @ tensor.T}")- 就地操作
就地操作 具有_后缀的操作是就地操作。例如:x.copy_(y), x.t_(), 将改变x
print(tensor, "\n")
tensor.add_(5)
print(tensor)注意点:
- 就地操作可以节省一些内存,但在计算导数时可能会出现问题,因为会立即丢失历史记录。因此,不鼓励使用它们。
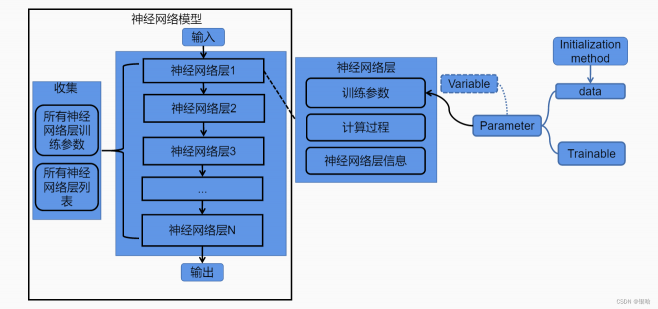
流程概括
数据处理:
首先,用户需要数据处理API来支持将数据集从磁盘读入。进一步,用户需要对读取的数据进行预处理,从而可以将数据输入后续的神经网络模型中。
模型结构:
完成数据的读取后,用户需要模型定义API来定义深度学习模型。这些模型带有模型参数,可以对给定的数据进行推理。
损失函数和优化算法:
模型的输出需要和用户的标记进行对比,这个对比差异一般通过损失函数(Loss function)来进行评估。因此,优化器定义API允许用户定义自己的损失函数,并且根据损失来引入(Import)和定义各种优化算法(Optimisation algorithms)来计算梯度(Gradient),完成对模型参数的更新。
训练过程:
给定一个数据集,模型,损失函数和优化器,用户需要训练API来定义一个循环(Loop)从而将数据集中的数据按照小批量(mini-batch)的方式读取出来,反复计算梯度来更新模型。这个反复的过程称为训练。
测试和调试:
训练过程中,用户需要测试API来对当前模型的精度进行评估。当精度达到目标后,训练结束。这一过程中,用户往往需要调试API来完成对模型的性能和正确性进行验证。

模型拆解
一个简单的前馈网络。它接受输入,一个接一个地通过几个层,然后最终给出输出。
一个典型的神经网络训练过程如下:
- 定义具有一些可学习参数(或权重)的神经网络
- 迭代输入数据集
- 通过网络处理输入
- 计算损失(输出与正确的距离有多远)
- 将梯度传播回网络参数
- 更新网络的权重,通常使用简单的更新规则:
weight = weight - learning_rate * gradient定义网络
以LeNet为例,让我们定义这个网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# 卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接操作: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 最大值的池化层 : a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果windowsize是方阵,一个数字就行 (2,2)= 2
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)-
只需定义forward函数,backward 函数(计算梯度的地方)会自动为您使用autograd. forward您可以在函数中使用任何 Tensor 操作。
-
模型的可学习参数由net.parameters()
尝试一个随机的 32x32 输入。
注意:此网络 (LeNet) 的预期输入大小为 32x32。要在 MNIST 数据集上使用此网络,请将数据集中的图像调整为 32x32。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)使用随机梯度将所有参数和反向传播的梯度缓冲区归零:
net.zero_grad()
out.backward(torch.randn(1, 10))注意:
torch.nn仅支持小批量。整个torch.nn 包只支持一小批样本的输入,而不是单个样本。
例如,nn.Conv2d将采用 的 4D 张量 。
(nSamples , nChannels , Height , Width)
如果您只有一个样本,只需使用它input.unsqueeze(0)来添加一个假批次维度。
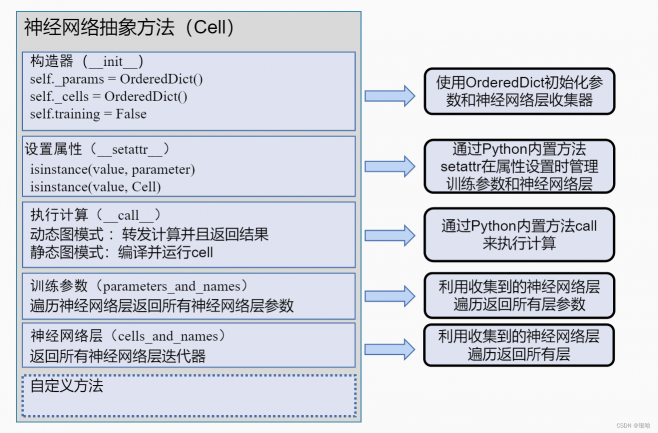
以上涉及到的点小结:
-
torch.Tensor-支持 autograd 操作的多维数组backward(),例如. 还保存张量的梯度。
-
nn.Module- 神经网络模块。封装参数的便捷方式,带有帮助程序将它们移动到 GPU、导出、加载等。
-
nn.Parameter- 一种张量,当作为属性分配给 a 时自动注册为参数 Module。
-
autograd.Function- 实现autograd 操作的前向和后向定义。每个Tensor操作至少创建一个Function节点,该节点连接到创建 aTensor并对其历史进行编码的函数。
最重要的两点:
-
定义神经网络
-
处理输入并向后调用
只要这两步不出问题,就本身代码跑起来出结果问题不大
损失函数
损失函数采用 (output, target) 对输入,并计算一个值来估计输出与目标的距离。
nn 包下有几种不同 的损失函数。一个简单的损失是:nn.MSELoss计算输出和目标之间的均方误差。
例如:
output = net(input)
target = torch.randn(10)
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)- 现在,如果您loss使用它的属性向后看 .grad_fn,您将看到如下所示的计算图DAG:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> flatten -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss当我们调用时loss.backward(),整个图根据神经网络参数进行微分,并且图中所有 requires_grad=True具有的张量都将.grad用梯度累加它们的张量。
- 可以倒退打印一下各层的累加梯度
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU反向传播
要反向传播loss,我们所要做的就是loss.backward(). 但是,您需要清除现有的梯度,否则渐变将累积到现有的梯度中。
现在我们将调用loss.backward(),并查看 conv1 在向后前后的偏置梯度。
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)教程中详细罗列了各种损失函数
注意:
各种不同的损失函数对应不同的任务,要根据任务选择损失函数,如果损失函数选择的不对,会出现loss=nan的情况
更新权重
实践中使用的最简单的更新规则是随机梯度下降 (SGD):
weight = weight - learning_rate * gradient我们可以使用简单的 Python 代码来实现它:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)- 定义神经网络时,可使用各种不同的更新规则,例如 SGD、Nesterov-SGD、Adam、RMSProp 等。为了实现这一点,
torch.optim它实现了所有这些方法。使用它非常简单:
import torch.optim as optim
# 创建优化器
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 在训练函数中定义:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # 权重更新- 手动将梯度缓冲区设置为零 optimizer.zero_grad()。这是因为梯度是累积的,每一轮迭代结束就清空
流程汇总:
我所遇到的问题
Conv2d中的out_channels代表什么?
- 这是卷积神经网络的代码
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()我的疑问:
这是否意味着我拥有的卷积核数量为 6?在这种情况下,这意味着我将获得的特征图总数是6*3==18?但如果是这样的话,为什么conv2我input_channels=6要插入 18,因为那是前一个卷积层的输出,我不应该输入18 吗?
找到的解答:
- out_channels代表输出通道的数量,因此代表默认设置中的卷积核数量。
- 你会得到out_channels激活图(3*6=18),因为每个卷积核使用所有输入通道来创建一个输出激活图,也就是输出之前会进行一个分组合并的操作
多输出通道
每一层有多个输出通道是至关重要的。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。
- 直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。
- 因此,多输出通道并不仅是学习多个单通道的检测器。
用 c i c_i ci和 c 0 c_0 c0分别表示输入和输出通道的数目,并让 k h k_h kh和 k w k_w kw为卷积核的高度和宽度。为
了获得多个通道的输出,我们可以为每个输出通道创建一个形状为的卷积核张量 c i ∗ k h ∗ k w c_i*k_h*k_w ci∗kh∗kw,这样卷积核的形状是 c 0 ∗ c i ∗ k h ∗ k w c_0*c_i*k_h*k_w c0∗ci∗kh∗kw。
- 在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果
多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。
多输入运算步骤:
- 每个通道的输入与对应通道的卷积核进行互相关运算
- 最后对各通道的运算结果进行求和
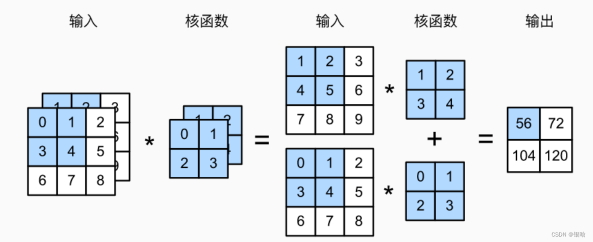
多输出通道
每一层有多个输出通道是至关重要的。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。
直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。
- 因此,多输出通道并不仅是学习多个单通道的检测器。
用 c i c_i ci和 c 0 c_0 c0分别表示输入和输出通道的数目,并让 k h k_h kh和 k w k_w kw为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为的卷积核张量 c i ∗ k h ∗ k w c_i*k_h*k_w ci∗kh∗kw,这样卷积核的形状是 c 0 ∗ c i ∗ k h ∗ k w c_0*c_i*k_h*k_w c0∗ci∗kh∗kw。
在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果
卷积的个人理解
卷积的本质是有效提取相邻像素间的相关特征,所以卷积操作看成是提取特征的方式,卷积核神经元就是图像处理中的滤波器,卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集
合。
这种提取特征方式与位置无关(就如why-conv里说的平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为"平移不变"。
性”)。
个人理解:
- 这种不变性是基于物理实际的,即相同的特征模式对应于一种物理实际,比如物体间的边缘界面理论上是可以通过空间图像的差异区分(体现在图像颜色上就是色差值和色差梯度等这些指标,当然前提是图像有足够高的锐度),那么这种提取后的特征也应该适用于图像的其它部分。所以对图像的各个输入,单个二维卷积张量,也就是一个 K h ∗ k w K_h*k_w Kh∗kw矩阵是权值共享的,偏置项也是如此。
针对多通道操作的小理解:
可以理解成加权相加。是对多个上层输出通道识别出来的patten的一个聚合。只是这里的加权值是可以融合到卷积核里的
小结几个要命的点:
- 卷积的结果是特征图,卷积是升维的
- 池化是降维的
- 想对特征图做全连接,此时需要把特征图平铺成一维向量,这步操作称为Flatten
- 全连接的结果是一维的,且全连接后再全连接可缩短一维tensor长度
计算图
- 计算图是用来表示深度学习网络模型在训练与推理过程中计算逻辑与状态的工具.
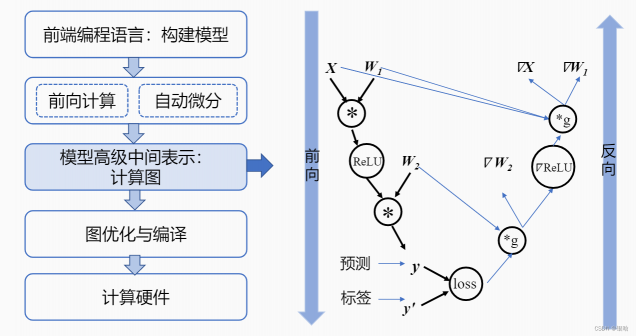
我们需要一个更加通用的技术来执行任意机器学习模型,计算图应运而生。综合来看,计算图对于一个机器学习框架提供了以下几个关键作用:
-
对于输入数据、算子和算子执行顺序的统一表达。 机器学习框架用户可以用多种高层次编程语言(Python,Julia和C++)来编写训练程序。这些高层次程序需要统一的表达成框架底层C和C++算子的执行。因此,计算图的第一个核心作用是可以作为一个统一的数据结构来表达用户用不同语言编写的训练程序。这个数据结构可以准确表述用户的输入数据、模型所带有的多个算子,以及算子之间的执行顺序。
-
定义中间状态和模型状态。 在一个用户训练程序中,用户会生成中间变量(神经网络层之间传递的激活值和梯度)来完成复杂的训练过程。而这其中,只有模型参数需要最后持久化,从而为后续的模型推理做准备。通过计算图,机器学习框架可以准确分析出中间状态的生命周期(一个中间变量何时生成,以及何时销毁),从而帮助框架更好的管理内存。
-
自动化计算梯度。 用户给定的训练程序仅仅包含了一个机器学习模型如何将用户输入(一般为训练数据)转化为输出(一般为损失函数)的过程。而为了训练这个模型,机器学习框架需要分析任意机器学习模型和其中的算子,找出自动化计算梯度的方法。计算图的出现让自动化分析模型定义和自动化计算梯度成为可能。
-
优化程序执行。 用户给定的模型程序往往是“串行化”地连接起来多个神经网络层。通过利用计算图来分析模型中算子的执行关系,机器学习框架可以更好地发现将算子进行异步执行的机会,从而以更快的速度完成模型程序的执行。
以激活函数ReLU为例:
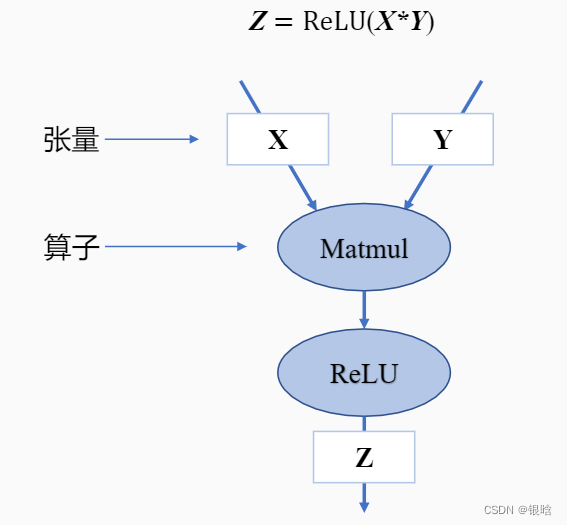
计算框架在后端会将前端语言构建的神经网络模型前向计算与反向梯度计算以计算图的形式来进行表示。计算图由基本数据结构:张量(Tensor)和基本运算单元:算子(Operator)构成。
- 在计算图中通常使用节点来表示算子,节点间的有向线段来表示张量状态,同时也描述了计算间的依赖关系。
数据流将根据图中流向与算子进行前向计算和反向梯度计算来更新图中张量状态,以此达到训练模型的目的。
- 梯度的前向与反向计算:
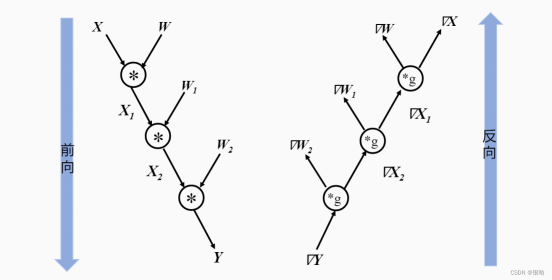
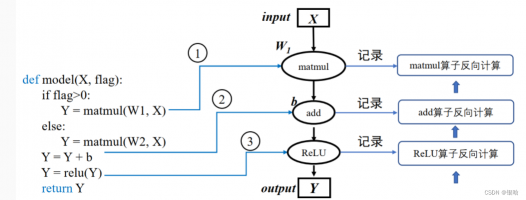
- 动态图则需要在每一次执行神经网络模型依据前端语言描述动态生成一份临时的计算图。
- PyTorch则可以通过工具将构建的动态图神经网络模型转化为静态结构,以获得高效的计算执行效率。
静态图:

动态图: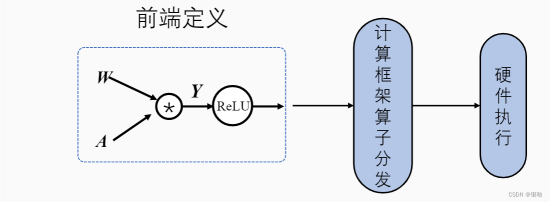
按照前端语言描述模型结构,按照计算依赖关系进行调度执行,动态生成临时的图拓扑结构。
- 模型训练的调度
模型训练就是计算图调度图中算子的执行过程。
宏观来看训练任务是由设定好的训练迭代次数来循环执行计算图,此时我们需要优化迭代训练计算图过程中数据流载入和模型训练(推理)等多个任务之间的调度执行。
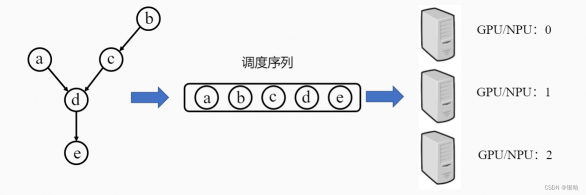
计算图中依赖边和算子构成了一张有向无环图(Directed Acyclic Graph),计算框架后端需要将包含这种依赖关系的算子准确地发送到计算资源,比如GPU、NPU上执行。
- 因此,就要求算子需要按照一定的顺序排列好再发送给GPU/NPU执行。
针对有向无环图,我们通常使用拓扑排序来得到一串线性的序列。
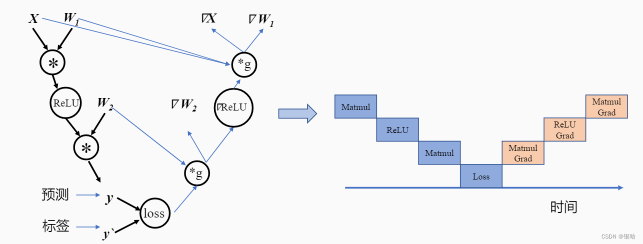
并行:
如果op1和op2之间相互独立,此时可以将两个算子分配到两个硬件上进行并行计算。对比串行执行,并行计算可以同时利用更多的计算资源来缩短执行时间。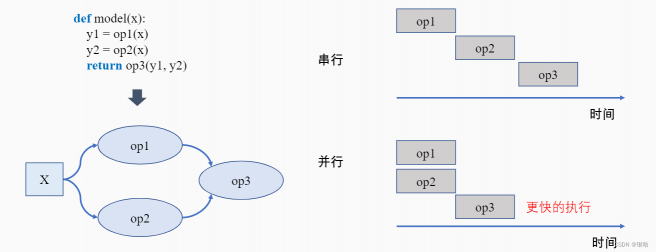
参考链接:链接
")


评论(0)
您还未登录,请登录后发表或查看评论