

Tensorflow学习实战之多变量预测
用的不是波士顿的数据,8700+的数据,进行的训练,相关性不强,而且线性不明显,得出的效果不好
要进行打乱数据,使用Shuttle,打乱顺序的原因呢,就跟人一样,你按顺序来,可能是按照某种规律,你可能会规律的去计算下一值,防止机器跟人一样找到规律,所以每一次要打乱一下。
载入数据
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
#读取
df_data=pd.read_csv("5.csv")
#显示摘要
print(df_data.describe())
#筛选要训练的数据load1,temperature,rainfall,Wind speed,humidity
selected_cols=['load1','temperature','rainfall','Wind speed','humidity']
selected_df_data=df_data[selected_cols]
df=selected_df_data.values
df=np.array(df)
print(df)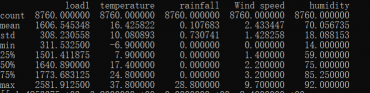
归一化处理
归一化处理,因为不同特征的取值范围不同,对结果有影响,为了消除影响,对特征数据进行归一化处理,最简单的就是x_data的最大值-最小值就行
for i in range(4):
df[:, i]=df[:, i]/(df[:, i].max()-df[:, i].min())
x_data=df[:,:4]
y_data=df[:,4]
print(x_data,'\n shape=', x_data.shape)
print(y_data,'\n shape=', y_data.shape)
建立模型
#占位符
x=tf.placeholder(tf.float32,[None,4],name='x')
y=tf.placeholder(tf.float32,[None,1],name='y')
with tf.name_scope('Model'):
w=tf.Variable(tf.random_normal([4,1],stddev=0.01),name='w')
b=tf.Variable(1.0,name='b')
print(w,b)
def model(x,w,b):
return tf.matmul(x,w)+b
pred=model(x,w,b)
#超参
learning_rate=0.02
train_epochs=10
#损失
with tf.name_scope('loss_Function'):
loss_function=tf.reduce_mean(tf.pow(y-pred,2))
#优化器
optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)初始化
#初始化
sess=tf.Session()
init=tf.global_variables_initializer()
sess.run(init)
loss_list=[]训练并显示结果
#迭代训练
for epoch in range(train_epochs):
loss_sum=0.0
for xs,ys in zip(x_data,y_data):
xs=xs.reshape(1,4)
ys=ys.reshape(1,1)
_,loss=sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys})
loss_sum=loss_sum+loss
xvalues,yvalues=shuffle(x_data,y_data)
btemp=b.eval(session=sess)
wtemp=w.eval(session=sess)
loss_average=loss_sum/len(y_data)
loss_list.append(loss_average)
print("epoch:",epoch+1,"loss: ",loss_average)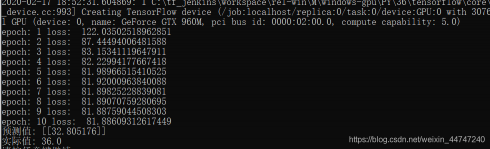
结果预测
plt.plot(loss_list)
plt.show()
#预测
n=np.random.randint(8700)
x_test=x_data[n]
x_test=x_test.reshape(1,4)
target=y_data[n]
predict=sess.run(pred,feed_dict={x:x_test})
print("预测值:",predict)
print("实际值:",target)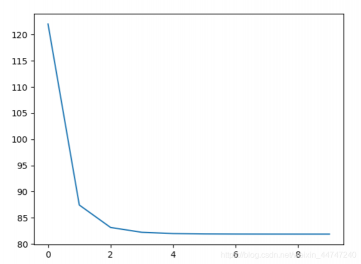



评论(0)
您还未登录,请登录后发表或查看评论