

RNN & Seq2Seq
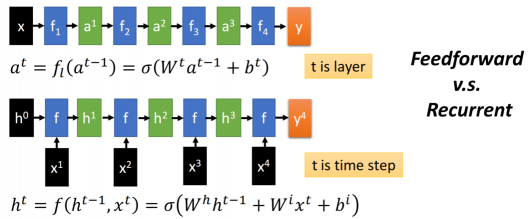
Feedforward v.s. Recurrent
- Feedforward network does not have input at each step
- Feedforward network has different parameters for each layer
双向RNN
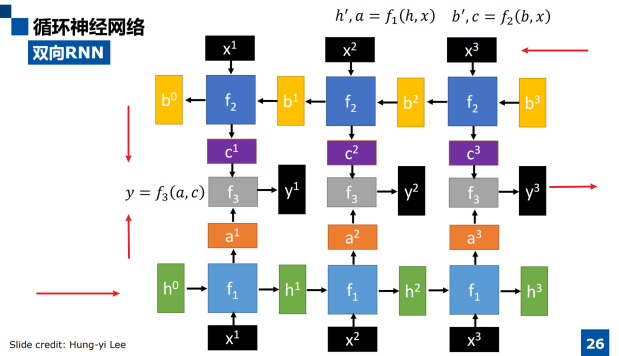
双向递归层可以提供更好的识别预测效果,但却不能实时预测,由于反向递归的计算需要从最末时刻开始,网络不得不等待着完整序列都产生后才可以开始预测。在对于实时识别有要求的线上语音识别,其应用受限
RNN如何训练

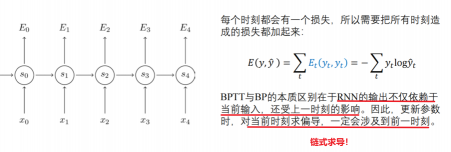
RNN的训练现象
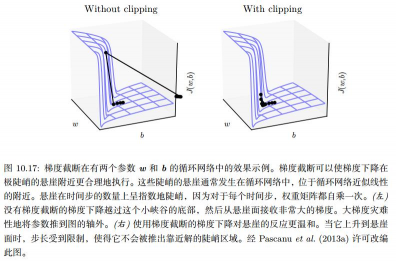
- 梯度截断
梯度截断(Gradient Clipping)是一种用于解决梯度爆炸问题的技术。在深度学习中,由于网络层数的增加和反向传播算法的存在,梯度可能会变得非常大,导致网络无法收敛。 -
为了解决这个问题,可以采用梯度截断技术,即限制梯度的大小,使其不超过一个指定的阈值。
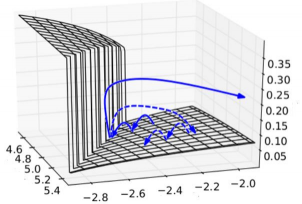
-
举例子说明,0.99 和 1.01 的1000次方 ,因为时间t每更新一次,权重矩阵就要自乘一次

RNN的问题
在实践中,如果序列过长会导致优化时出现梯度消散或梯度爆炸的问题,从而丧失学
习到连接如此远的信息的能力
-
为了有效的利用梯度下降法学习,我们希望使不断相乘的梯度的积保持在接近1的数
值。目前最有效的方式gated RNNs,通过gates的调控,允许线性自连接的权重在
每一步都可以自我变化调节。LSTM就是gated RNNs中的一个实现
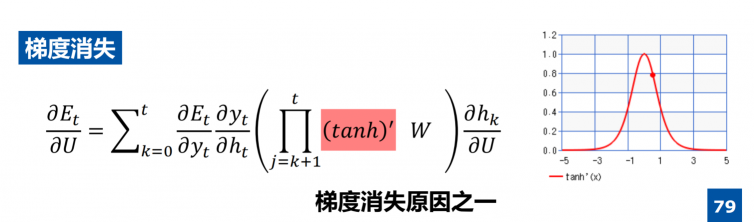
梯度消失的原因之一:tanh激活函数求导后的连乘 -
前向计算不可能保证都是1
- 反向传播可能趋近于0或者正无穷
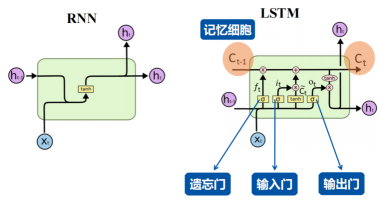
LSTM
- LSTM 能解决梯度消失的问题,遗忘门
- LSTM的遗忘门可以控制信息的流动,从而避免了梯度消失的问题。在传统的RNN中,每个时间步的输入和前一时刻的隐藏状态都会被直接传递到下一时刻,这样会导致信息在时间序列中不断累积,从而导致梯度消失或梯度爆炸的问题。而LSTM的遗忘门可以选择性地遗忘前一时刻的隐藏状态,从而控制信息的流动,避免了信息在时间序列中的累积。同时,LSTM的门控机制也可以控制信息的输入和输出,从而进一步避免了梯度消失或梯度爆炸的问题。因此,LSTM的遗忘门能够有效地解决梯度消失的问题。

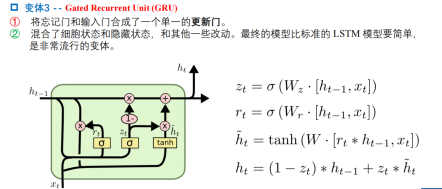
GRU模型如下,它只有两个门了,分别为更新门和重置门,即图中的



评论(0)
您还未登录,请登录后发表或查看评论