

第六节课作业
2.LK光流
2.1 光流文献综述
问题:
2.1按此文的分类,光流法可分为哪几类?
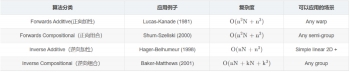
注:看了高博视频课里的内容,感觉这里的Additive理解为平移比较好一点。
在compositional 中,为什么有时候需要做原始图像的wrap?该wrap 有何物理意义?
首先来理解算法的目标,再理解为什么需要做原始图的wrap。算法的目标是有一个模板图像T(x)和一个原始图像I(x),要求给原始图像做一个wrap变换,并求这个变换函数W(x:p),使得经过变换候的图像I(W(x:p))与模板图像T之间的差异最小。用数学表达式来描述上边的过程就是:

相同的图像块在不同的图像中可能发生了一些变化,带wrap变化会使得算法更鲁棒。这里的wrap就可以理解为一个不断迭代,不断优化的一个框图,并且这个框图最终的目标是跟模板图相匹配。如下图所示,其中绿色框图为模板图像T。

3.forward 和inverse 有何差别?
如果模板中有很多噪声,则应该使用正向算法。如果输入图像中噪声更多,那就采用逆向算法。逆向算法只用计算一次Hessian矩阵,而正向算法需要在每次迭代过程中都计算一遍Hessian矩阵。因此,逆向算法更高效,计算量较小。
正向法在第二个图像I2处求梯度,而逆向法直接用第一个图像I1处的梯度来代替。正向法和逆向法的目标函数也不一样:
正向组合算法:
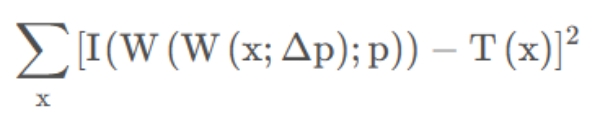
逆向组合算法:
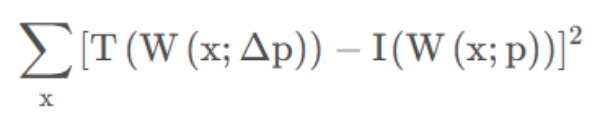
如下两图所示,
正向组合算法的计算过程:

逆向组合算法的计算过程:

2.2 forward-addtive Gauss-Newton 光流的实现
1.从最小二乘角度来看,每个像素的误差怎么定义?
2.误差相对于自变量的导数如何定义?

因为图像中每个点之间的像素值是离散的,不能直接用微分来求导,这里我们用差分来代替微分求导,下边用中心差分方式来进行求导计算。

根据提示和上边的公式推导来编程实现forward-addtive Gauss-Newton 光流方法,关键代码如下所示:
double error = error = GetPixelValue(img1, kp.pt.x + x, kp.pt.y+y) - GetPixelValue(img2, kp.pt.x + x + dx, kp.pt.y + y + dy);
Eigen::Vector2d J; // Jacobian
if (inverse == false) {
// Forward Jacobian
J = -1.0 * Eigen::Vector2d(
0.5*( GetPixelValue(img2, kp.pt.x + x+ dx + 1, kp.pt.y+y+dy) - GetPixelValue(img2, kp.pt.x + x + dx-1 , kp.pt.y + y + dy) ),
0.5*( GetPixelValue(img2, kp.pt.x + x+dx, kp.pt.y+y+dy +1) - GetPixelValue(img2, kp.pt.x + x + dx, kp.pt.y + y + dy-1) )
);
} else {
// Inverse Jacobian
// NOTE this J does not change when dx, dy is updated, so we can store it and only compute error
}
// compute H, b and set cost;
H += J * J.transpose();
b += -error * J;
cost += error * error;
正向单层光流法与OpenCV相比的效果图:
2.3 反向法
反向的光流法做了一个巧妙的技巧,即用I 1处的梯度,替换掉原本要计算的I2处的梯度。相应的导数为:
代码部分:

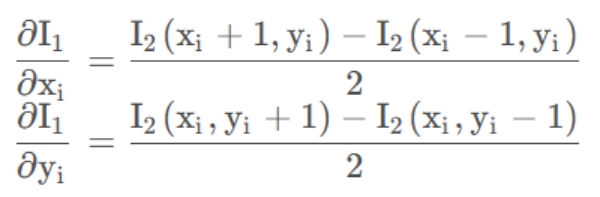
J = -1.0 * Eigen::Vector2d(
0.5*( GetPixelValue(img1, kp.pt.x + x + 1, kp.pt.y+y) - GetPixelValue(img1, kp.pt.x + x -1 , kp.pt.y + y) ),
0.5*( GetPixelValue(img1, kp.pt.x + x, kp.pt.y+y+1) - GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y-1) )
);
反向单层光流法与OpenCV相比的效果图:
注:根据课本上P213页,雅可比是带有负号的,但是我自己求得的梯度是不带负号的,经过实验也发现,带负号比不带符号效果好。而在课本P187中间部分有解释,“我们保留前面的负号,这是因为误差是由观测值减预测值定义的,反之去掉负号即可”。
2.4 推广至金字塔
1.所谓 coarse-to-fine 是指怎样的过程?
图像金字塔是指对一个图像进行缩放,得到不同分辨率下的图像,如下图所示。以原始图像作为金字塔底层,每往上一层,就对下一层图像进行一定倍率的缩放,就得到了一个金字塔。然后,在计算光流时,先从顶层的图像开始计算,然后把上一层的追踪结果,作为下一层光流的初始值。由于上层图像相对粗糙,所以这个过程也称为由粗至精(coarse-to-fine)的光流。
光流法中的金字塔用途和特征点法中的金字塔有何差别?
2.光流法中使用图像金字塔,可以使得优化过程更容易跳出,由于原始图像像素运动较大导致的优化结果困在极小值的情况。
而特征点法金子塔中,金字塔的作用是解决Fast角点,由于远处看着像角点的地方,近处就可能不是角点的尺度问题,给Fast角点增加尺度不变性。
代码:

for (int i = 0; i < pyramids; i++) {
Mat img1temp, img2temp;
resize(img1, img1temp, Size(img1.size().width*scales[pyramids-1-i], img1.size().height*scales[pyramids-1-i]));//Size_(_Tp _width, _Tp _height);
resize(img2, img2temp, Size(img2.size().width*scales[pyramids-1-i], img2.size().height*scales[pyramids-1-i]));//Size_(_Tp _width, _Tp _height);
OpticalFlowSingleLevel(img1temp, img2temp, kp1_pyr, kp2_pyr, success, inverse);
if (i < pyramids-1) {
for (auto &kp: kp1_pyr)
kp.pt /= pyramid_scale;
for (auto &kp: kp2_pyr)
kp.pt /= pyramid_scale;
}
}
正向多层光流法与OpenCV相比的效果图:
反向多层光流法与OpenCV相比的效果图:
2.5 并行化
代码思路:引入一个额外的vector用于存放下标i;


vector<int> indexs;
for (int i = 0; i < kp1.size(); i++) {
indexs.push_back(i);
}
std::lock_guard<std::mutex> guard(m);//代替m.lock; m.unlock();
for_each(execution::par_unseq, indexs.begin(), indexs.end(),
[&] (auto &i){
代码与单层光流一样
});
单层光流法并行化运行结果:
这里如果不加锁的话会报内存溢出的错误:
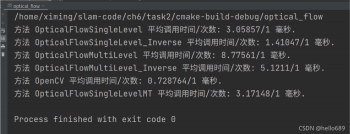
std::lock_guard<std::mutex> guard(m);//代替m.lock; m.unlock();
错误如下图所示:
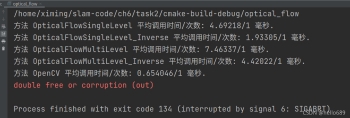
2.6 讨论
1.我们优化两个图像块的灰度之差真的合理吗?哪些时候不够合理?你有解决办法吗?
优化两个图像块的灰度值之差是在两图灰度值不会变的强前提之下的,如果两张图片中,色彩变化剧烈,那么光流发可能效果就不会那么合理。高博课中提到,可以使用图像灰度相对变化来进行光流法,对图像中每个像素值减去均值,得到相对变化来做光流法。
2.图像块大小是否有明显差异?取 16x16 和 8x8 的图像块会让结果发生变化吗?
如下图所示,分别为8×8与16×16的图像块时,利用opencv处理所的的结果。本实验中,8×8与16×16的图像块并无太大差异。推测可能是由于本题的两张图片中像素变化范围并不大,如果运动范围很大,那么可能调整图像块会有一定影响。
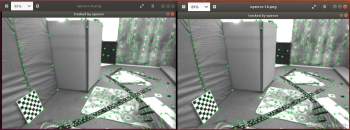
3.金字塔层数对结果有怎样的影响?缩放倍率呢?
如下图所示,当缩放倍率为0.5,金字塔的层数分别为3、4、5时,逆向多层光流法的结果为:

可以看出,层数越多,光流法得到的点就越少,并且越往中间聚集,边缘的点就会被忽略掉。
如下图所示,当金字塔的层数为4,缩放倍率为0.25、0.5、0.75时,逆向多层光流法的结果为:

可以看出,肯定是倍率越小,光流法得到的点就越少,但是倍率的影响要比金字塔的影响更快,在倍率为0.25时,直接没能找到相应的点。
3. 直接法
注:本题编程中使用了boost库中的方法,需要安装boost库
sudo apt-get install libboost-all-dev
3.1 单层直接法
1.该问题中的误差项是什么?
2.误差相对于自变量的雅克比维度是多少?如何求解?
本小题答案参照助教的课后分享:
3.窗口可以取多大?是否可以取单个点?
代码中默认的窗口大小为8×8,可以取单点,但是精确度会有所下降。
单层测试结果图如下所示:
直接法不取角点也能工作,主要是因为该方法不去要做特征点匹配,该方法需要优化的是一个点的光度误差,而不是某个特定点的光度误差。
3.2 多层直接法
类似于光流法中的方法,使用coarse-to-fine的过程来跳过优化过程中的极小点。这部分代码跟光流法也非常相似。
代码:



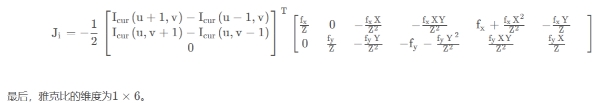

for (int i = 0; i < pyramids; i++) {
if (i == 0) {
pyr1.push_back(img1);
pyr2.push_back(img2);
} else {
cv::Mat img1_pyr, img2_pyr;
cv::resize(pyr1[i - 1], img1_pyr,
cv::Size(pyr1[i - 1].cols * pyramid_scale, pyr1[i - 1].rows * pyramid_scale));
cv::resize(pyr2[i - 1], img2_pyr,
cv::Size(pyr2[i - 1].cols * pyramid_scale, pyr2[i - 1].rows * pyramid_scale));
pyr1.push_back(img1_pyr);
pyr2.push_back(img2_pyr);
}
}
fx = fxG * scales[level];
fy = fyG * scales[level];
cx = cxG * scales[level];
cy = cyG * scales[level];
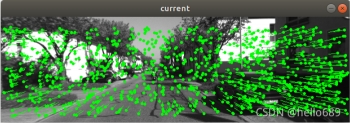
多层直接法效果图:
下面是t5的结果,与作业提供的结果有一定差异。
3.3 并行化
从计算第二张图像的重投影出开始进行多线程并行化处理
本题思路与上边的类似
代码部分:

// Define Hessian and bias
Matrix6d H = Matrix6d::Zero(); // 6x6 Hessian
Vector6d b = Vector6d::Zero(); // 6x1 bias
vector<int> indexs;
for (size_t i = 0; i < px_ref.size(); i++)
indexs.push_back(i);
std::for_each(std::execution::par_unseq, indexs.begin(),indexs.end(),
[&] (auto &i){
std::lock_guard<std::mutex> guard(m);//代替m.lock; m.unlock();
....省略
});
...
需要加锁,可以正确运行,这里我就省了输出运行时间的程序。
3.4 * 延伸讨论
1.直接法是否可以类似光流,提出 inverse, compositional 的概念?它们有意义吗?
直接法可以类似光流,提出inverse,compositional,但是没有意义,因为直接法是直接对两个图的光度误差做优化。
2.请思考上面算法哪些地方可以缓存或加速?
在for循环计算每个点时,可以进行代码并行加速。另外并不是块选择越大越好,选择一个合适的,较小的,效率也会提高。
3.在上述过程中,我们实际假设了哪两个 patch 不变?
灰度值不变,同一个窗口内的深度信息不变
4.为何可以随机取点?而不用取角点或线上的点?那些不是角点的地方,投影算对了吗?
因为是直接对光度误差做优化,不需要做特征匹配,是不是角点无所谓。
5.请总结直接法相对于特征点法的异同与优缺点。
优点:
可以省去计算特征点、描述子的时间。
只要求有像素梯度即可,不需要特征点。
可以构建半稠密乃至稠密的地图,这点是特征点无法做到的。
缺点:
非凸性
单个像素没有区分度
灰度值不变是很强的假设
具体描述在第二版书本P230-231。
4. *使用光流计算视差
视差计算的核心代码:
vector<double > disp;
vector<double > cost;
for(int i = 0 ;i<pixels_ref.size();i++)
{
double dis = pixels_ref[i].x()-goodProjection[i].x(); //两点之间的水平视差
disp.push_back(dis);
// cout<<"dis: "<<dis<<" "<<GetPixelValue(disparity_img,pixels_ref[i].x(),pixels_ref[i].y())<<endl;
cost.push_back(dis-GetPixelValue(disparity_img,pixels_ref[i].x(),pixels_ref[i].y()));
}
//计算视差的平均误差
double sum = accumulate(cost.begin(),cost.end(),0.0);
cout<<"平均误差:"<<sum/cost.size()<<endl;
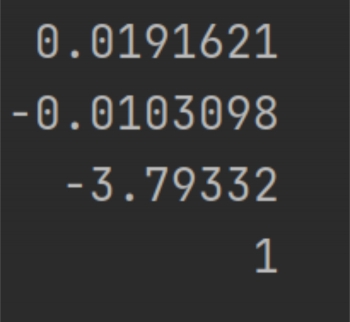
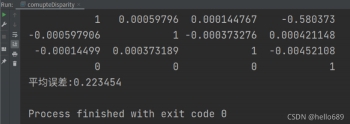
其中,单层直接法最后得到的平均误差为-7.027,多层直接法的平均误差为0.223。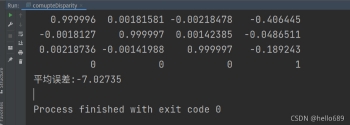
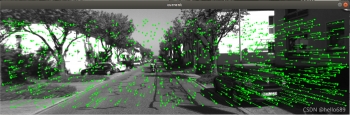
视差效果如下图所示: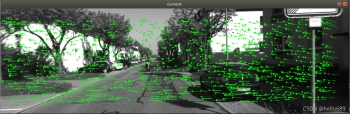
github地址: https://github.com/ximing1998/slam-learning.git
国内gitee地址:https://gitee.com/ximing689/slam-learning.git
")


评论(0)
您还未登录,请登录后发表或查看评论