
第四节课作业
2.图像去畸变
本题主要内容是根据提供的公式和参数来实现图像的去畸变。
畸变前后坐标变化公式:

其中给定的参数为:

去畸变核心部分代码:
// start your code here
//计算归一化坐标
double x = (u - cx)/fx;
double y = (v - cy)/fy;
double r = sqrt(x*x + y*y);
//计算径向和切向畸变后的坐标
double x_distorted = x * (1 + k1 * r * r + k2 * r * r * r * r) + 2 * p1 * x * y + p2 * (r * r + 2 * x * x);
double y_distorted = y * (1 + k1 * r * r + k2 * r * r * r * r) + p1 * (r * r + 2 * y * y) + 2 * p2 * x * y;
//计算像素
u_distorted = fx * x_distorted + cx;
v_distorted = fy * y_distorted + cy;
// end your code here
去畸变效果图:
3.鱼眼模型与去畸变
1.请说明鱼眼相机相比于普通针孔相机在SLAM 方面的优势。
鱼眼相机最重要的一个优势就是相比于普通针孔相机拥有更宽阔的视野。因此可以确保在一段时间里,尽可能多的视觉特征进入相机视野,从而提高对周围环境的感知能力。
2.请整理并描述OpenCV 中使用的鱼眼畸变模型(等距投影)是如何定义的,它与上题的畸变模型有何不同。
参考资料:
OpenCV: Fisheye camera model
https://blog.csdn.net/KYJL888/article/details/117423950
https://blog.csdn.net/weixin_43304707/article/details/113261307
模型定义(也叫kannala-brandt模型,有多种鱼眼畸变模型):
设在世界坐标系中有一点P,该点坐标用矩阵X表示。在相机坐标系中向量坐标P为:
Xc=RX+T
其中,R是旋转矩阵,旋转向量om经过罗德里格斯变换所得。Xc的三个量分别是x,y,z;
P的针孔投影坐标为[a,b]:
注:在OpenCV的文档中,如下图所示,θ=atan(r),表示反正切,也可以描述成θ=arctan(r)。
鱼眼畸变:
与上一题的畸变模型的不同点:上题的畸变模型包括了径向和切向两种畸变。本题的鱼眼相机只给出了θd一种畸变类型。我注意到,在求解最终的像素坐标u时,鱼眼相机转换时加入了一个αy′与y有关的变量,跟上一题的模型不同。
3.完成fisheye.cpp 文件中的内容。针对给定的图像,实现它的畸变校正。要求:通过手写方式实现,不允许调用OpenCV 的API。
通过上述公式,实现去畸变的核心代码如下所示:

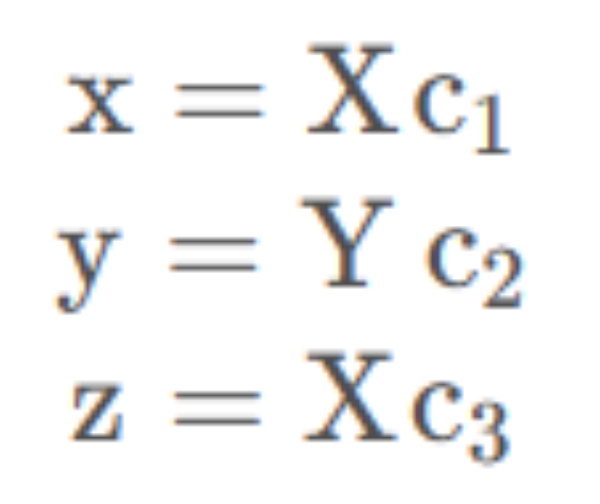
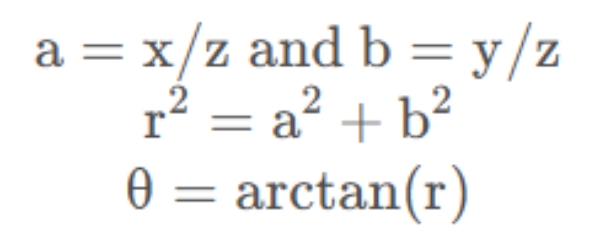


double a = (u-cx)/fx, b = (v-cy)/fy;
double r = sqrt(a*a + b*b);
double theta = atan(r);
double theta_2 = theta*theta;
double theta_4 = theta_2*theta_2;
double theta_6 = theta_4*theta_2;
double theta_8 = theta_4*theta_4;
double theta_d = theta*(1+k1*theta_2+k2*theta_4+k3*theta_6+k4*theta_8);
double x_distorted = (theta_d / r)*a;
double y_distorted = (theta_d / r)*b;
u_distorted = fx*(x_distorted + 0.01*y_distorted)+cx;
v_distorted = fy*y_distorted + cy;
去除鱼眼畸变效果图:
4.为什么在这张图像中,我们令畸变参数k1, . . . , k4 = 0,依然可以产生去畸变的效果?
5.在鱼眼模型中,去畸变是否带来了图像内容的损失?如何避免这种图像内容上的损失呢?
鱼眼图一般为圆形,边缘的信息被压缩的很密,经过去除畸变后原图中间的部分会被保留的很好,而边缘位置一般都会被拉伸的很严重、视觉效果差,所以通常会进行切除,因此肯定会带来图像内容的损失。增大去畸变时图像的尺寸,或者使用单目相机和鱼眼相机图像进行融合,补全丢失的信息。
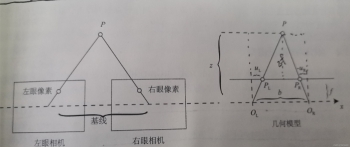
4.双目视差的使用
理论部分
1.推导双目相机模型下,视差与XYZ坐标的关系式。请给出由像素坐标加视差u,v,d推导XYZ与已知XYZ推导u,v,d两个关系。
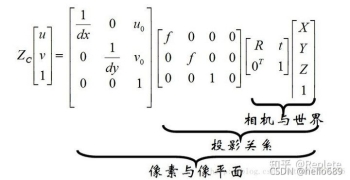
先给出世界坐标系、相机坐标系、图像坐标系、像素坐标系的关系:
img source:https://zhuanlan.zhihu.com/p/421453976
2.推导在右目相机下该模型将发生什么改变。
在视差这一块,使用右眼相机坐标减去左眼相机坐标,d = x_r - x_l。使用右眼相机的投影点,另外使用左眼相机的外参。
编程部分
核心部分代码:



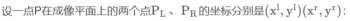

// start your code here (~6 lines)
// 根据双目模型计算 point 的位置
double x = (u - cx) / fx;
double y = (v - cy) / fy;
double depth = fx * d / (disparity.at<char>(v, u));
point[0] = x * depth;
point[1] = y * depth;
point[2] = depth;
pointcloud.push_back(point);
// end your code here

5.矩阵运算微分


6.高斯牛顿法的曲线拟合实验
定义误差为:

根据该公式,使用高斯牛顿法进行数据拟合,主要部分代码如下:
// start your code here
double error = 0; // 第i个数据点的计算误差
error = yi - exp(ae * xi * xi + be*xi + ce); // 填写计算error的表达式
Vector3d J; // 雅可比矩阵
J[0] = -xi*xi*exp(ae * xi * xi + be*xi + ce); // de/da
J[1] = -xi* exp(ae * xi * xi + be*xi + ce); // de/db
J[2] = -exp(ae * xi * xi + be*xi + ce); // de/dc
H += J * J.transpose(); // GN近似的H
b += -error * J;
// end your code here
// 求解线性方程 Hx=b,建议用ldlt
// start your code here
Vector3d dx = H.ldlt().solve(b);
// end your code here运行结果:

7.批量最大似然估计
1.可以定义矩阵H HH,使得批量误差为e=z−Hx。请给出此处H的具体形式。

所以H为:

github地址: https://github.com/ximing1998/slam-learning.git
国内gitee地址:https://gitee.com/ximing689/slam-learning.git
")


评论(0)
您还未登录,请登录后发表或查看评论