

网上DSO基本上都是在TUM数据集上跑得,教程也比较多,写论文需要,使用DSO跑了一下Euroc数据集,踩了很多坑,花了一天的时间才调通,记录一下。
本机运行环境:Ubuntu16.04 其它环境只要安装过ORB-SALM2的应该不用做额外的配置
1.安装DSO,教程很多,不做赘述,不过ziplib这个包需要注意,如果图片数据集是以zip格式存储方式进行读取的话需要安装这个包,当然直接建一个文件夹放图片也行。
2.按照教程运行DSO,运行Euroc数据集的命令为
./dso_dataset files=/home/SLAM/DSO/dso-master/EuRoc/V203/mav0/cam0/data calib=./camera.txt mode=1
注意这里files后的路径是存放Euroc数据集的路径,另外有一个重要的问题在于需要在“data”文件夹下放置“times.txt”,此文件每行包含文件名、时间戳、曝光时间(Euroc没有),这个times.txt可以用Euroc/mav0/cam0下的data.csv来生成,写一个python四行就可以搞定了。最后times.txt的格式应该像这样,每行第一个是图片的名字,但是“.png”被去掉了,时间戳注意小数点格式转换否则最后无法用evo拿来与真值评估:
(python代码),
#!/usr/bin/python
# -*- coding: utf-8 -*-
import csv
# 输入文件路径和输出文件路径
input_csv_file = 'data.csv'
output_txt_file = 'times.txt'
# 打开CSV文件进行读取
with open(input_csv_file, 'r') as csv_file:
# 使用csv.reader读取CSV文件
csv_reader = csv.reader(csv_file)
# 打开输出文件进行写入
with open(output_txt_file, 'w') as txt_file:
# 使用csv.writer写入文本文件,以空格分隔
txt_writer = csv.writer(txt_file, delimiter=' ')
# 遍历CSV文件的每一行
for row in csv_reader:
# 获取时间戳和图片名
timestamp = row[0]
image_name = row[1]
# 提取图片名的前缀(去除.png后缀)
image_prefix = image_name.split('.')[0]
# 将数据写入times.txt文件
txt_writer.writerow([image_prefix, timestamp])
print("Conversion completed. Result written to {}".format(output_txt_file))
注意输出第一行非有用数据,可手动删除
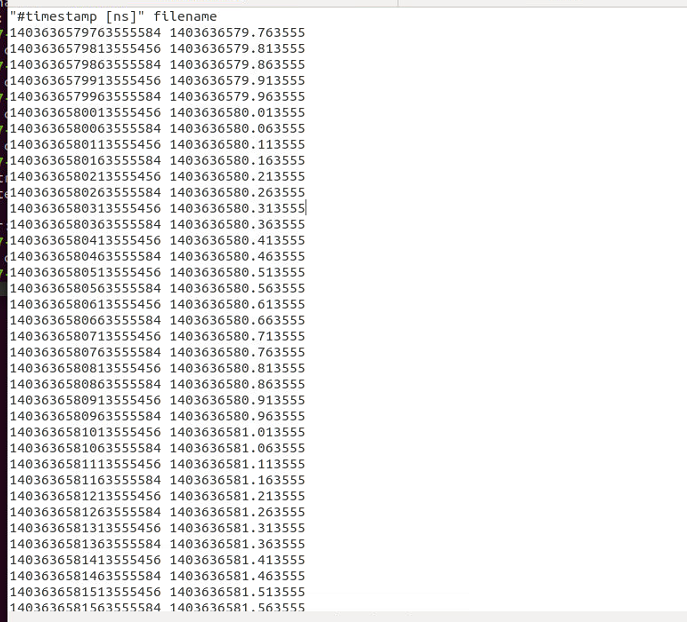
得到之后便可运行,成功读取times.txt的话在执行界面时会显示如下格式:

成功运行如下:

3.运行后会在./build/bin下生成result.txt,如果第二步没有成功读取times.txt的话时间戳会全是0。

典型的TUM格式,但是生成的多了空格,需要处理一下才能用evo工具评估:
cat result.txt | tr -s [:space:] > DSO.txt
4.DSO格式就是最终的轨迹文件,直接用evo工具与Euroc的真值作对比即可,网上教程颇多,不做赘述。



评论(0)
您还未登录,请登录后发表或查看评论