

本系列讲述的方法均是Linux实现方法。
说CUDA是人工智能算法行业的重要基石一点也不为过。老黄在图灵架构发布的时候说,图灵架构是英伟达历史上自2006年以来最伟大的飞跃。而2006年,正是CUDA发布的时间。
利用CUDA,开发者可以拿N家的GPU进行各种自定义的任务,挖矿、炼丹等等。今天咱们通过第一个CUDA程序,了解一下CUDA程序的构造。看CUDA界的Hello World程序:
#include<stdio.h>
__global__ void hello_world(void)
{
printf("GPU: Hello world!\n");
}
int main(int argc,char **argv)
{
printf("CPU: Hello world!\n");
hello_world<<<1,10>>>();
cudaDeviceReset();//if no this line ,it can not output hello world from gpu
return 0;
}
代码来自谭老师的cuda教学repo。将上述代码保存为helloworld.cu,运行方法:
nvcc -o helloworld helloworld.cu
./helloworld
上述代码讲述了如何利用GPU把hello world打印10遍。用__global__修饰的函数为核函数,可直接被GPU上的thread调用运行。本程序的入口是main函数,由CPU进入程序,然后用CPU再调用GPU。
<<<1,10>>>表示分配的block数量和thread数量,即用10个线程并行去跑helloworld()函数。
这里的block和thread表示GPU的阵列粒度,一个block是一组thread集合,而一组block是一个grid。CUDA中的grid/block/thread既是逻辑概念也是硬件概念。而thread就是CUDA运行核函数的最小单位。
可以用一张图来展示:
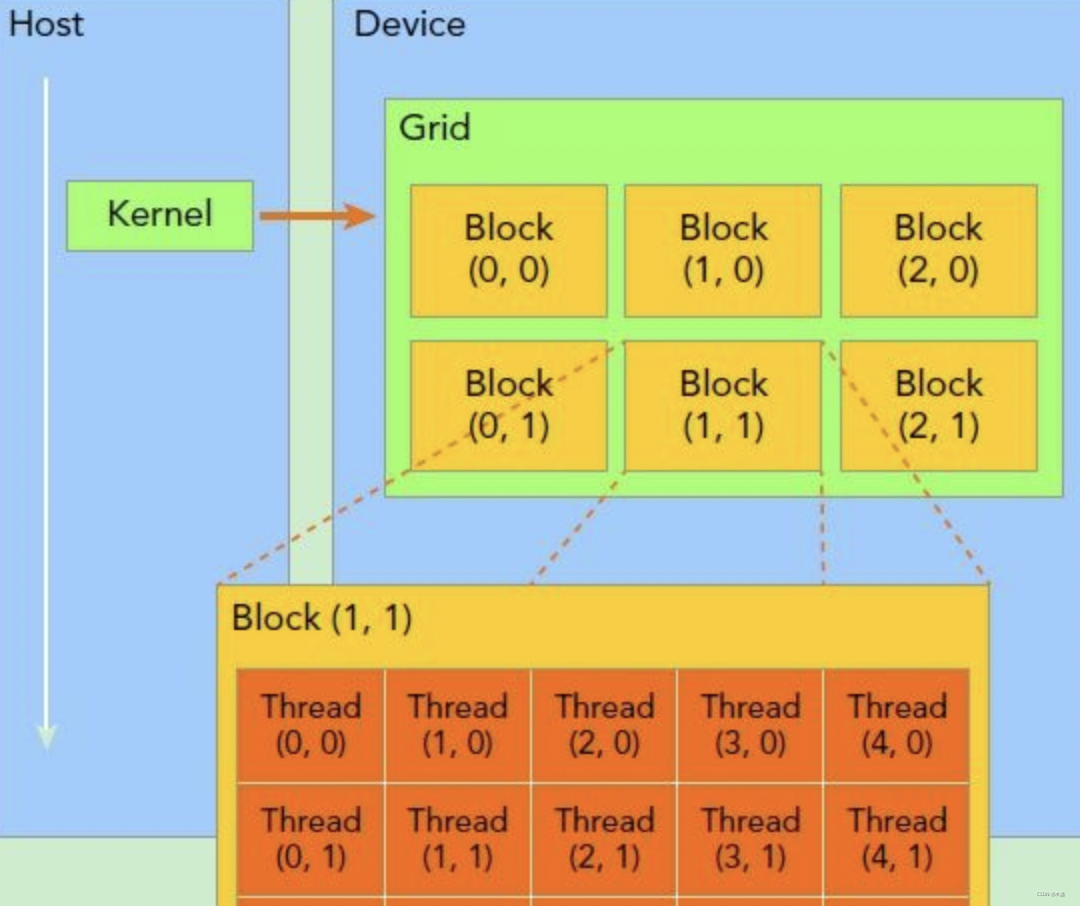
用10个GPU线程启用print,跟用for循环print10遍的结果看起来一样,实则运算逻辑是并行和串行的区别。思考:为什么GPU被用来做挖矿? 答:因为简单重复的哈希运算可以并行做。挖矿算法就是用穷举法来试答案,CPU一次只能试1次答案,而GPU理论上一次可以使线程数个答案。这立马就高下立判了。最后,如果想在GPU上用printf,则必须加一个cudaDeviceReset()。
总结
GPU有大量的计算阵列,每个阵列单元可以独立运行函数。这也是CUDA能够比CPU计算呈指数倍快速的原因。CUDA最常见的用法就是矩阵运算,你想想如果你用C语言写两个矩阵的乘法,是不是需要写2个for循环来嵌套。直接就是O ( n 2 ) O(n^2)O(n
2
)的复杂度了。如果用CUDA去做,计算就会指数级降低。
所以,但凡涉及到多个for循环嵌套的大规模计算,都可以用CUDA来减少for循环。
")


评论(0)
您还未登录,请登录后发表或查看评论