

8. BBDM: Image-to-Image Translation with Brownian Bridge Diffusion Models
本文提出一种基于布朗桥(Brownian Bridge)的扩散模型用于图像到图像的转换。图像到图像转换的目标是将源域A中的图像I_A,映射到目标域B中得到图像I_B。在一般的扩散模型中(如DDPM),是从目标域B中采集样本作为起点x_0对其进行扩散,得到纯噪声x_T;然后,再从纯噪声中采样进行反向去噪,生成目标图像{x}_0。为了实现图像到图像的转换,一般会将参考图像作为条件y,引入到生成过程中,噪声估计网络\epsilon_{\theta}同时根据前一步的结果x_t,时刻t和条件y来估计噪声,进而得到新的去噪结果x_{t-1},如下图A所示。
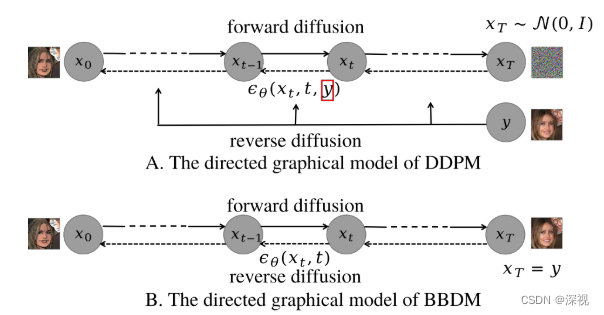
不同于一般的扩散模型,其扩散过程只依赖于起始点x_0,布朗桥扩散过程同时依赖起点x_0和终点x_T,其数学表达如下
p\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{0}, \boldsymbol{x}_{T}\right)=\mathcal{N}\left(\left(1-\frac{t}{T}\right) \boldsymbol{x}_{0}+\frac{t}{T} \boldsymbol{x}_{T}, \frac{t(T-t)}{T} \boldsymbol{I}\right)
基于此,作者将条件y取代纯噪声作为终点x_T
,然后从条件y开始进行反向去噪得到目标图像{x}_0。值得注意的是,在生成过程中,条件y只作为起点,而不作为噪声估计网络\epsilon_{\theta}的条件,如上图B所示。
为了提升学习的效率和泛化能力,作者在浅层空间中完成扩散和重建过程,而不是在图像空间中,作者先利用VQGAN的编码器将图像I_A
映射到潜在空间中L_A,经过扩散和重建后得到目标域的潜在特征L_{A\rightarrow B} ,最后再利用VQGAN的解码器恢复得到图像I_{A\rightarrow B} 。

这篇文章我读着很迷惑,从源域转换到目标域,那么根据上图的表示源域应该是真实图片,目标域是漫画图像,那么所谓的条件也就是参考图像y应该是来自于源域啊。为什么文章中又说从目标域B中采样得到y呢?而且前文一直在讲,把y作为前向扩散过程的终点和反向去噪过程的起点,那为什么上图灰色区域中前向扩散的终点是目标域的图像呢?不知道是我自己的理解问题,还是作者本身的写作有误。下文会按照我自己的理解来写,可能会与原文有一点点微弱的出入。
分别从源域A和目标域B中采集成对的样本(y,x),经过VQGAN的编码器处理后得到对应的特征向量\boldsymbol{y,x},则布朗桥前向扩散过程可写为
q_{B B}\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{0}, \boldsymbol{y}\right)=\mathcal{N}\left(\boldsymbol{x}_{t} ;\left(1-m_{t}\right) \boldsymbol{x}_{0}+m_{t} \boldsymbol{y}, \delta_{t} \boldsymbol{I}\right)
其中
\boldsymbol{x}_{0}=\boldsymbol{x}, \quad m_{t}=\frac{t}{T}
T表示扩散过程的总步数,方差\delta_t定义为
\delta_{t}=2 s\left(m_{t}-m_{t}^{2}\right)
其中s作为一个放缩系数,用于控制采样的多样性,默认值为1。这样的设置,保证了当t=0和t=T时,\delta_t都为0,而x_t分别为x_0和y ,满足了前文所述的扩散的起点和终点。扩散过程中单步的转移公式如下
_{B B}\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{t-1}, \boldsymbol{y}\right)=\mathcal{N}\left(\boldsymbol{x}_{t} ; \frac{1-m_{t}}{1-m_{t-1}} \boldsymbol{x}_{t-1}+\left(m_{t}-\frac{1-m_{t}}{1-m_{t-1}} m_{t-1}\right) \boldsymbol{y}, \delta_{t \mid t-1} \boldsymbol{I}\right)
其中
\delta_{t \mid t-1}=\delta_{t}-\delta_{t-1} \frac{\left(1-m_{t}\right)^{2}}{\left(1-m_{t-1}\right)^{2}}
经过前向扩散过程,我们将目标域的图像x_0映射到源域中的x_T=y,在接下来的反向去噪过程中,我们将从y出发逐步去噪生成一个新的目标域图像{x}_0,单步的去噪过程如下
p_{\theta}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{y}\right)=\mathcal{N}\left(\boldsymbol{x}_{t-1} ; \boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right), \tilde{\delta}_{t} \boldsymbol{I}\right)
其中均值\boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right)是由一个神经网络根据\boldsymbol{x}_{t},t估计得到的,而方差\tilde{\delta}_{t}则是一个无需学习的仅与t有关的变量。那么下面的任务就是如何训练一个网络来估计均值\boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right)了。与DDPM类似,作者也是给出一个了可变分下界的目标函数
E L B O = − E q ( D K L ( q B B ( x T ∣ x 0 , y ) ∥ p ( x T ∣ y ) ) + ∑ t = 2 T D K L ( q B B ( x t − 1 ∣ x t , x 0 , y ) ∥ p θ ( x t − 1 ∣ x t , y ) ) − log p θ ( x 0 ∣ x 1 , y ) )
其中第一项为常数,可以忽略。重点看第二项,q_{B B}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right)根据贝叶斯理论可得
q B B ( x t − 1 ∣ x t , x 0 , y ) = q B B ( x t ∣ x t − 1 , y ) q B B ( x t − 1 ∣ x 0 , y ) q B B ( x t ∣ x 0 , y ) = N ( x t − 1 ; μ ~ t ( x t , x 0 , y ) , δ ~ t I )
其中均值\tilde{\boldsymbol{\mu}}_{t}\left(\boldsymbol{x}_{t}, \boldsymbol{x}_{0}, \boldsymbol{y}\right)为
μ ~ t ( x t , x 0 , y ) = δ t − 1 δ t 1 − m t 1 − m t − 1 x t + ( 1 − m t − 1 ) δ t ∣ t − 1 δ t x 0 + ( m t − 1 − m t 1 − m t 1 − m t − 1 δ t − 1 δ t ) y
方差\tilde{\delta}_{t}为
\tilde{\delta}_{t}=\frac{\delta_{t \mid t-1} \cdot \delta_{t-1}}{\delta_{t}}
由于在推理过程中x_0是未知的,因此可以根据公式8-2由当前的x_t反向估计一个\hat{x}_0,将其带入公式8-9中可得
\tilde{\delta}_{t}=\frac{\delta_{t \mid t-1} \cdot \delta_{t-1}}{\delta_{t}}\tilde{\boldsymbol{\mu}}_{t}\left(\boldsymbol{x}_{t}, \boldsymbol{y}\right)=c_{x t} \boldsymbol{x}_{t}+c_{y t} \boldsymbol{y}+c_{\epsilon t}\left(m_{t}\left(\boldsymbol{y}-\boldsymbol{x}_{0}\right)+\sqrt{\delta_{t}} \boldsymbol{\epsilon}\right)
其中
c x t = δ t − 1 δ t 1 − m t 1 − m t − 1 + δ t ∣ t − 1 δ t ( 1 − m t − 1 ) c y t = m t − 1 − m t 1 − m t 1 − m t − 1 δ t − 1 δ t c ϵ t = ( 1 − m t − 1 ) δ t ∣ t − 1 δ t
与DDPM中一样,作者不直接预测均值\tilde{\mu}_t ,而是对其中的噪声\epsilon进行预测。p_{\theta}\left(\boldsymbol{x}_{t-1} \mid \boldsymbol{x}_{t}, \boldsymbol{y}\right)中的均值项\boldsymbol{\mu}_{\theta}\left(\boldsymbol{x}_{t}, t\right)可以重写为\boldsymbol{x}_{t},\boldsymbol{y},y和估计噪声\epsilon_{\theta}的线性组合
\boldsymbol{\mu}_{\boldsymbol{\theta}}\left(\boldsymbol{x}_{t}, \boldsymbol{y}, t\right)=c_{x t} \boldsymbol{x}_{t}+c_{y t} \boldsymbol{y}+c_{\epsilon t} \boldsymbol{\epsilon}_{\theta}\left(\boldsymbol{x}_{t}, t\right)
则目标函数ELBO可以简化为
\mathbb{E}_{\boldsymbol{x}_{0}, \boldsymbol{y}, \boldsymbol{\epsilon}}\left[c_{\epsilon t}\left\|m_{t}\left(\boldsymbol{y}-\boldsymbol{x}_{0}\right)+\sqrt{\delta_{t}} \boldsymbol{\epsilon}-\boldsymbol{\epsilon}_{\theta}\left(\boldsymbol{x}_{t}, t\right)\right\|^{2}\right]
完整的训练流程如下

经过训练得到噪声估计网络\boldsymbol{\epsilon}_{\theta}\left(\boldsymbol{x}_{t}, t\right),就可以从源域中任意采样一个条件输入\boldsymbol{y}作为生成的起点\boldsymbol{x}_T,经过反向去噪得到生成结果x_0 ,如下所示

上述的采样过程也可以利用DDIM提出的加速技巧进行加速。整体上而言,BBDM就是将原本扩散过程从图像到噪声的变换,改成了从目标图像到源图像的变换。然后,在反向去噪时,只需给定一个源图像就能据此生成对应目标域中的样本。虽然不用像其他条件扩散模型那样,将条件引入模型中用于训练,但在BBDM的训练过程需要成对的样本,这限制了BBDM在许多情景中的应用。



评论(0)
您还未登录,请登录后发表或查看评论