

9. Zero-shot Image-to-Image Translation
该文提出一种无需训练,即可对图像进行文本驱动编辑的方法。在准确修改目标对象的同时,保证原图的背景和布局等内容不受太多的影响。下图展示了几种文本驱动图像编辑的效果,如将猫变成狗,将马变成斑马等。

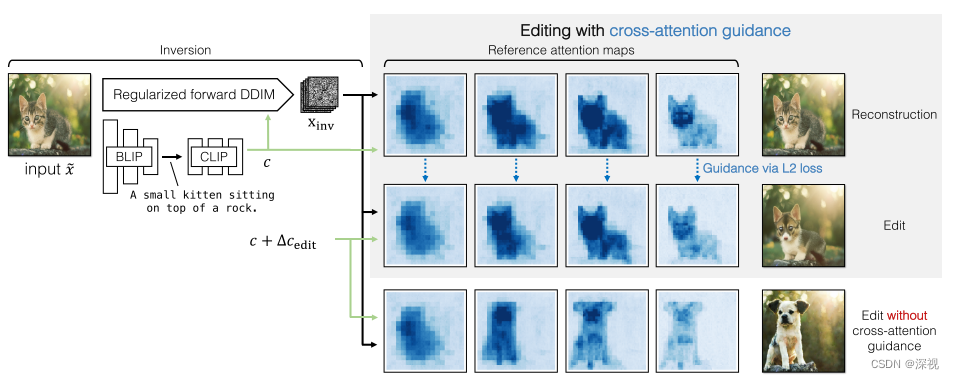
该文主要做了以下几点工作,首先将输入的图像\tilde{x}利用Stable Diffusion编码到潜在空间得到x_0,并按照DDIM中的确定性过程将其扩散为噪声编码x_{inv}。然后,利用BLIP模型得到输入图像对应的文本描述c,并计算其与目标文本提示t之间的均值差异\Delta c_{edit},将其作为图像编辑的方向引入到生成过程中。最后,为了保持图像的背景和布局保持不变,作者引入了交叉注意力机制进行引导。该方法的流程如下图所示
1. 逆转真实图像
首先得到真实图像\tilde{x}对应的潜在特征x_0后,作者利用DDIM中的确定性过程将其扩散为纯噪声,过程如下
x_{t+1}=\sqrt{\bar{\alpha}_{t+1}} f_{\theta}\left(x_{t}, t, c\right)+\sqrt{1-\bar{\alpha}_{t+1}} \epsilon_{\theta}\left(x_{t}, t, c\right)
其中,\epsilon_{\theta}是基于UNet模型的噪声估计器,f_{\theta}是根据当前的噪声图像x_t ,时刻t和文本描述特征c来估计得到的\hat{x}_0过程如下
f_{\theta}\left(x_{t}, t, c\right)=\frac{x_{t}-\sqrt{1-\bar{\alpha}_{t}} \epsilon_{\theta}\left(x_{t}, t, c\right)}{\sqrt{\bar{\alpha}_{t}}}
这里很有意思,作者并不是直接使用DDIM中的扩散过程来增加噪声的,而是将原本已知的x_0换成了估计得到的\hat{x}_0 ,把可以随机采样的噪声\epsilon变成了预测得到的\epsilon_{\theta} ,我认为这样做的目的是为了在扩散过程中就把文字描述特征c引入进去。
但是估计得到的噪声\epsilon_{\theta}存在一个问题,他不一定满足统计学上的不相关性,也就是说它不是一个完全的高斯白噪声,这将导致由最终的扩散结果x_{inv} 生成的图像效果不好。为了解决这个问题,作者引入了两个正则化条件,\mathcal{L}_{pair}和\mathcal{L}_{KL}。为了计算\mathcal{L}_{pair},作者将\epsilon_{\theta}输出的噪声图\eta^0\in\mathbb{R}^{64\times64\times4}
利用2*2的全局池化层将其逐步下采样到尺寸为8\times8的噪声图,构建一个4层的噪声图金字塔{\eta^0,\eta^1,\eta^2,\eta^3},然后,利用下式来计算\mathcal{L}_{pair}
\mathcal{L}_{\text {pair }}=\sum_{p} \frac{1}{S_{p}^{2}} \sum_{\delta=1}^{S_{p}-1} \sum_{x, y, c} \eta_{x, y, c}^{p}\left(\eta_{x-\delta, y, c}^{p}+\eta_{x, y-\delta, c}^{p}\right)
其中,下标x,y表示位置,c表示通道号,\delta表示位置偏移量,S_p表示噪声图的尺寸。另一方面,使用变分自动编码器中的KL散度损失\mathcal{L}_{KL},来约束生成的噪声满足零均值单位方差的要求。最后,两个损失函数通过加权求和作为最终的自动互相关(auto-correlation)正则化项\mathcal{L}_{auto}=\mathcal{L}_{pair}+\lambda\mathcal{L}_{KL}。
2. 计算编辑方向
作者把原本的文本描述c作为源提示s,把编辑后的文本描述作为目标提示t,并利用GPT-3语言模型,根据这两个提示分别生成一系列的句子,然后利用CLIP的文本编码器得到这些句子的嵌入式特征,并计算二者之间的均值差异\Delta c_{edit},如下图所示。这个差异将作为图像编辑的方向引入到生成过程中。

3. 基于交叉注意力引导的图像编辑
此时我们已经得到了扩散后的噪声图像x_{inv}和原本的图像描述c,以及图像编辑的方向\Delta c_{edit}。最直接的方法就是将图像描述和编辑方向相加后c_{edit}=c+\Delta c_{edit}作为条件,引入噪声估计网络\epsilon_{\theta}(x_t,t,c_{edit}),并按照一般的反向去噪过程得到生成图像,如本文中第二幅图的最后一行表示的过程。但这样带来一个问题,就是虽然目标对象按照编辑的内容发生了改变,但由于缺少约束和引导,图像的背景布局以及目标的结构和姿态都发生了变化,这是我们不希望看到的。因此为了解决这个问题,作者引入了基于交叉注意力机制的引导方法。
其实在Prompt-to-prompt这篇文章中,我们就已经揭示了交叉注意力图和图像内容以及文字描述之间的对应关系,如下所示
\begin{aligned} \operatorname{Attention}(Q, K, V) & =M \cdot V \\ \text { where } M & =\operatorname{Softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right) \end{aligned}
其中Q=W_Q\psi(x_t),K=W_Kc,V=W_Vc,\psi(x_t)表示经过UNet编码的图像特征。得到的交叉注意力图M其中的每个元素M_{ij}表示了第j个文本提示对于图像中第i个位置处的作用。因此为了保证图像的整体背景和布局不会随着文本编辑发生较大的改变,作者提出了一种基于交叉注意力机制的引导。
第一步,直接使用原本的图像描述c获得交叉注意力图M_t^{ref};第二步,使用编辑后的描述c_{edit}获得交叉注意力图M_t^{edit},计算两者差异的L2范数关于x_t的梯度\Delta x_{t}=\nabla_{x_{t}}\left(\left|M_{t}^{\text {edit }}-M_{t}^{\text {ref }}\right|_{2}\right),并将其作用于x_t,得到\tilde{x}_t=x_t-\lambda_{xa}\Delta x_{t}后,再次计算噪声\epsilon^{\hat {edit }} \leftarrow \epsilon_{\theta}\left(x_{t}-\lambda_{\text {xa }} \Delta x_{t}, t, c_{\text {edit }}\right)。最后,根据\epsilon^{\hat {edit }}进行反向去噪,得到x_{t-1}。完整的算法流程如下图所示




评论(0)
您还未登录,请登录后发表或查看评论