

核心思想
本文提出一种基于3D关键点投票网络的姿态估计算法。通过投票的方式从RGBD图像中寻找3D关键点,并采用语义分割网络和中心点检测网络实现实例分割,最后根据实例中关键点和对应模型的关键点之间的匹配关系,利用最小二乘法计算得到图像实例与模型之间的位姿变换(旋转矩阵+平移矩阵),即得目标物体的6D位姿。特点在于本文不是直接从图像中提取关键点,而是利用网络预测每个点与关键之间的位置偏移,然后计算每个点经过偏移后的聚类中心来作为关键点。因为在3D空间中,对于一个刚性物体,无论其位姿如何变化,任意两个点之间的位置偏移是固定的。所以,可以利用物体表面的点来预测关键点的位置。
实现过程
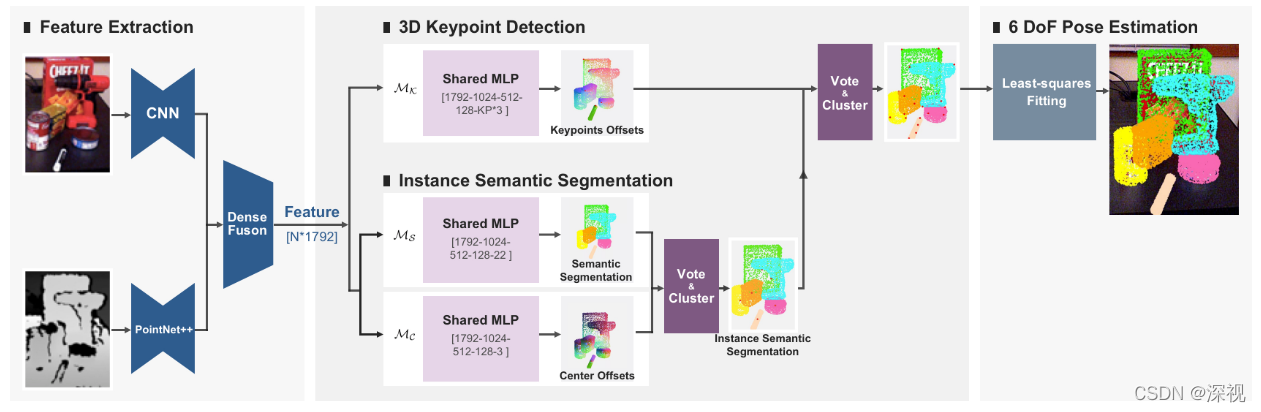
首先,利用PSPNet网络和PointNet++网络分别从RGB图像和深度点云图中提取特征信息,并利用DenseFusion网络将两种类型的特征信息融合起来得到
N
N
N个采样点对应的特征向量。特征向量分别会提供给两个任务:一个用于检测3D关键点,一个用于物体实例分割。
给定每个物体实例
I
I
I的可视采样点集合
{
p
i
}
i
=
1
N
{p_i}_{i=1}^N
{pi}i=1N (
p
i
p_i
pi包括采样点的特征向量
f
i
f_i
fi和3D坐标
x
i
x_i
xi),和物体实例
I
I
I上的关键点集合
{
k
p
j
}
j
=
1
M
{kp_j}_{j=1}^M
{kpj}j=1M(
k
p
j
kp_j
kpj包括关键点的3D坐标
y
i
y_i
yi)。 3D关键点检测网络
M
K
\mathcal{M}_{\mathcal{K}}
MK的根据每个采样点的特征向量
f
i
f_i
fi,来预测每个采样点与每个关键点之间的3D位置偏差
{
o
f
i
j
}
j
=
1
M
{of_i^j}_{j=1}^M
{ofij}j=1M,
o
f
i
j
of_i^j
ofij表示第
i
i
i个采样点和第
j
j
j个关键点之间的位置偏差。物体实例
I
I
I上的关键点集合
{
k
p
j
}
j
=
1
M
{kp_j}_{j=1}^M
{kpj}j=1M是从物体的3D模型中采用最远点采样算法(farthest point sampling ,FPS)提取的,具体而言就是先选择物体的中心点作为一个关键点,添加到一个空的关键点集合中,然后寻找距离当前所有关键点最远的采样点作为新的关键点补充进去,重复该过程直到得到
M
M
M个关键点。关键点提取网络的损失函数如下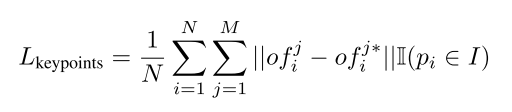
其中
o
f
i
j
∗
{of_i^j}^*
ofij∗表示真实的偏差值,
I
\mathbb{I}
I表示判断
p
i
p_i
pi是否属于实例
I
I
I,若是则为1,若不是则为0。在测试过程中,得到预测的偏差值
o
f
i
j
of_i^j
ofij,可以根据采样点的坐标
x
i
x_i
xi来计算投票关键点的坐标
v
k
p
i
j
=
x
i
+
o
f
i
j
vkp_i^j=x_i + of_i^j
vkpij=xi+ofij,然后对
v
k
p
i
j
vkp_i^j
vkpij进行聚类得到聚类中心点坐标,即为预测的关键点坐标
k
p
j
kp_j
kpj.
另一个任务分支是对3D采样点进行实例分割,作者先用语义分割网络
M
S
\mathcal{M}_{\mathcal{S}}
MS根据采样点的特征向量来预测采样点的语义标签,损失函数采用Focal Loss如下: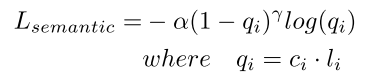
其中
α
\alpha
α是平衡参数,
γ
\gamma
γ是聚焦参数,
c
i
c_i
ci表示点
i
i
i属于每个类别的预测置信度,
l
i
l_i
li真实的语义标签。
然后用中心点检测网络
M
C
\mathcal{M}_{\mathcal{C}}
MC来预测每个采样点与对应实例中心点之间的3D位置偏移
Δ
x
i
\Delta x_i
Δxi,通过投票的方式来预测每个物体中心点的位置,来区分不同的实例。这个过程与关键点检测网络类似,损失函数同样采用
L
1
L1
L1损失: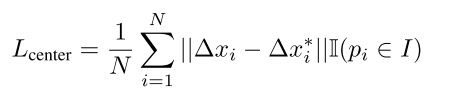
三个网络均采用共享权重的MLP结构,作者认为这样可以提升每个任务的效果。一方面语义分割网络能够提取全局和局部特征,而这有助于定位物体上的一个点进而帮助关键点偏移预测的过程;另一方面,关键点偏移预测过程中获得的物体尺寸信息也能够帮助区分拥有相似外观但是不同尺寸的物体。
最后,根据每个物体实例预测的3D关键点坐标
k
p
j
kp_j
kpj和对应3D模型实例中的3D关键点坐标
k
p
j
′
kp_j’
kpj′,采用最小二乘法来计算物体实例和3D模型实例之间的位姿变换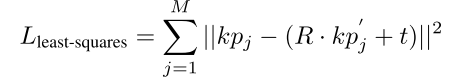
位姿估计效果如下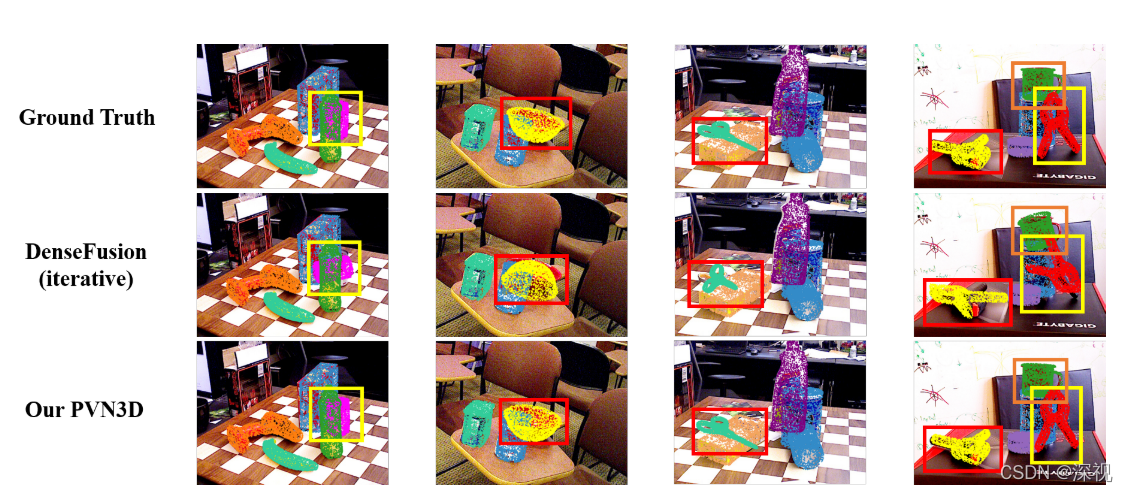
创新点
- 提出一种3D关键点投票网络来预测关键点的3D坐标
- 结合语义分割和中心点检测网络来实现图像的实例分割
算法评价
本文本质上还是利用图像关键点和模型关键点之间的匹配关系,求解二者之间的位姿变换过程。只不过本文将常见的2D关键检测转换为3D关键点检测,这样能够避免由于视角的变换和遮挡等问题带来的影响。并且不是直接根据特征信息通过回归的方式来预测关键点,而是间接的预测每个采样点和关键点之间的位置偏移来检测3D关键点,这样隐含一种优势就是充分利用物体的刚性约束,而且可以聚合整个物体上所有采样点的信息来选择预测关键点位置。但本文其实需要的条件很多比如要有RGBD输入,物体的3D模型以及模型和图像之间的真实匹配关系来进行网络的训练。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论