

策略梯度方法-python车杆平衡实战
- 案例分析
- 同策策略梯度算法求解最优策略
- 异策策略梯度算法求解最优策略
- 对比结论
代码链接
案例分析
本文考虑Gym库里的车杆平衡问题(CartPole-v0)。如下图所示,一个小车(cart)可以在直线滑轨上移动。一个杆(pole)一头连着小车,另一头悬空,可以不完全直立。小车的初始位置和杆的初始角度都是在一定范围内随机选取的。智能体可以控制小车沿着滑轨左移1个单位或者右移1段固定的距离(移动的幅度是固定的,而且不可以不移动)。出现以下情形中的任一情形时,回合结束:
·杆的倾斜角度超过12度;
·小车移动超过2.4个单位长度;
·回合达到200步。
每进行1步得到1个单位的奖励。我们希望回合能够尽量地长。一般认为,如果在连续的100个回合中的平均奖励≥195,就认为问题解决了。

这个任务中,观察值有4个分量,分别表示小车位置、小车速度、木棒角度和木棒角速度,其取值范围如表7-1所示。动作则取自{0,1},分别表示向左施力和向右施力。

对于随机策略,其回合奖励大概在9~10之间。
同策策略梯度算法求解最优策略
先来使用同策算法求解最优策略。下面代码中的VPGAgent类是算法的智能体类,它同时支持不带基线的版本和带基线的版本。它用人工神经网络来近似策略函数。
class VPGAgent:
def __init__(self, env, policy_kwargs, baseline_kwargs=None,
gamma=0.99):
self.action_n = env.action_space.n
self.gamma = gamma
self.trajectory = [] # 轨迹存储
self.policy_net = self.build_network(output_size=self.action_n,
output_activation=tf.nn.softmax,
loss=keras.losses.categorical_crossentropy,
**policy_kwargs)
if baseline_kwargs: # 基线
self.baseline_net = self.build_network(output_size=1,
**baseline_kwargs)
def build_network(self, hidden_sizes, output_size,
activation=tf.nn.relu, output_activation=None,
loss=keras.losses.mse, learning_rate=0.01):
model = keras.Sequential()
for hidden_size in hidden_sizes:
model.add(keras.layers.Dense(units=hidden_size,
activation=activation))
model.add(keras.layers.Dense(units=output_size,
activation=output_activation))
optimizer = keras.optimizers.Adam(learning_rate)
model.compile(optimizer=optimizer, loss=loss)
return model
def decide(self, observation):
probs = self.policy_net.predict(observation[np.newaxis])[0]
action = np.random.choice(self.action_n, p=probs)
return action
def learn(self, observation, action, reward, done):
self.trajectory.append((observation, action, reward))
if done:
df = pd.DataFrame(self.trajectory,
columns=['observation', 'action', 'reward'])
df['discount'] = self.gamma ** df.index.to_series()
df['discounted_reward'] = df['discount'] * df['reward']
df['discounted_return'] = df['discounted_reward'][::-1].cumsum()
df['psi'] = df['discounted_return']
x = np.stack(df['observation'])
if hasattr(self, 'baseline_net'): # 带基线的逻辑
df['baseline'] = self.baseline_net.predict(x)
df['psi'] -= (df['baseline'] * df['discount'])
df['return'] = df['discounted_return'] / df['discount']
y = df['return'].values[:, np.newaxis]
self.baseline_net.fit(x, y, verbose=0)
y = np.eye(self.action_n)[df['action']] * \
df['psi'].values[:, np.newaxis]
self.policy_net.fit(x, y, verbose=0)
self.trajectory = []当VPGAgent类的构造参数baseline_kwargs为默认值None时,构造的是不带基线的智能体。我们可以用下列代码构造不带基线的智能体:
policy_kwargs = {'hidden_sizes' : [10,], 'activation' : tf.nn.relu,
'learning_rate' : 0.01}
agent = VPGAgent(env, policy_kwargs=policy_kwargs)当VPGAgent类的构造参数baselines_kwargs是一个与基线有关的dict对象时,构造一个神经网络v(S;w)来做基线。我们可以用下列代码构造带基线的智能体:
policy_kwargs = {'hidden_sizes' : [10,], 'activation':tf.nn.relu,
'learning_rate':0.01}
baseline_kwargs = {'hidden_sizes' : [10,], 'activation':tf.nn.relu,
'learning_rate':0.01}
agent = VPGAgent(env, policy_kwargs=policy_kwargs,
baseline_kwargs=baseline_kwargs)智能体和环境交互的代码如下,利用这个函数,我们就可以训练和测试回合更新策略梯度函数算法。
def play_montecarlo(env, agent, render=False, train=False):
observation = env.reset()
episode_reward = 0.
while True:
if render:
env.render()
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action)
episode_reward += reward
if train:
agent.learn(observation, action, reward, done)
if done:
break
observation = next_observation
return episode_reward
episodes = 500
episode_rewards = []
for episode in range(episodes):
episode_reward = play_montecarlo(env, agent, train=True)
episode_rewards.append(episode_reward)
plt.plot(episode_rewards);不带基线的简单策略梯度算法效果如下
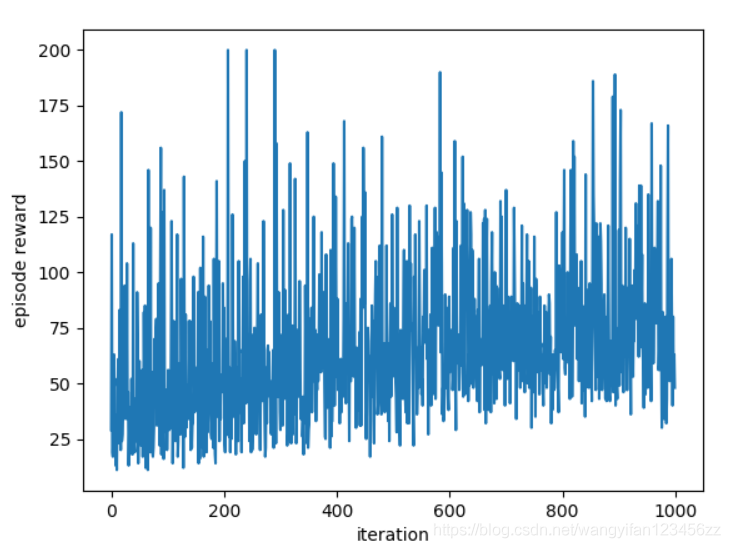
带基线的简单策略梯度算法
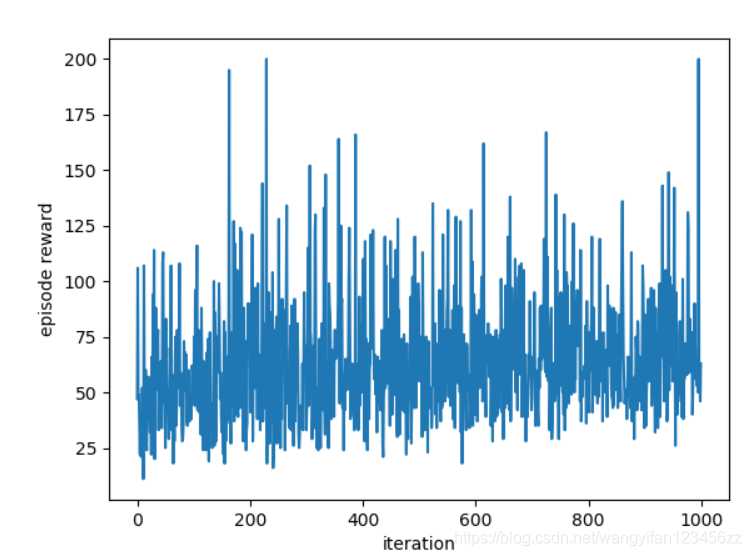
可以看出方差会比不带基线的方法小一些。
异策策略梯度算法求解最优策略
接下来我们来分析基于重要性采样的异策算法求解最优策略。下面给出了相应算法的智能体,这个智能体同样也是同时支持不带基线的版本和带基线的版本。
class OffPolicyVPGAgent(VPGAgent):
def __init__(self, env, policy_kwargs, baseline_kwargs=None,
gamma=0.99):
self.action_n = env.action_space.n
self.gamma = gamma
self.trajectory = []
def dot(y_true, y_pred):
return -tf.reduce_sum(y_true * y_pred, axis=-1)
self.policy_net = self.build_network(output_size=self.action_n,
output_activation=tf.nn.softmax, loss=dot, **policy_kwargs)
if baseline_kwargs:
self.baseline_net = self.build_network(output_size=1,
**baseline_kwargs)
def learn(self, observation, action, behavior, reward, done):
self.trajectory.append((observation, action, behavior, reward))
if done:
df = pd.DataFrame(self.trajectory, columns=
['observation', 'action', 'behavior', 'reward'])
df['discount'] = self.gamma ** df.index.to_series()
df['discounted_reward'] = df['discount'] * df['reward']
df['discounted_return'] = \
df['discounted_reward'][::-1].cumsum()
df['psi'] = df['discounted_return']
x = np.stack(df['observation'])
if hasattr(self, 'baseline_net'):
df['baseline'] = self.baseline_net.predict(x)
df['psi'] -= df['baseline'] * df['discount']
df['return'] = df['discounted_return'] / df['discount']
y = df['return'].values[:, np.newaxis]
self.baseline_net.fit(x, y, verbose=0)
y = np.eye(self.action_n)[df['action']] * \
(df['psi'] / df['behavior']).values[:, np.newaxis]
self.policy_net.fit(x, y, verbose=0)
self.trajectory = [] # 为下一回合初始化经验列表对于异策算法,不仅要有评估的策略,还要有行为策略,最简单的行为策略是随机策略。
class RandomAgent:
def __init__(self, env):
self.action_n = env.action_space.n
def decide(self, observation):
action = np.random.choice(self.action_n)
behavior = 1. / self.action_n
return action, behavior利用异策学习智能体和随机策略,可以训练和测试基于重要性采样的回合更新策略梯度算法。训练代码如下
episodes = 1500
episode_rewards = []
for episode in range(episodes):
observation = env.reset()
episode_reward = 0.
while True:
action, behavior = behavior_agent.decide(observation)
next_observation, reward, done, _ = env.step(action)
episode_reward += reward
agent.learn(observation, action, behavior, reward, done)
if done:
break
observation = next_observation
# 跟踪监控
episode_reward = play_montecarlo(env, agent)
episode_rewards.append(episode_reward)
plt.plot(episode_rewards);
不带基线的重要性采样策略梯度算法效果如下
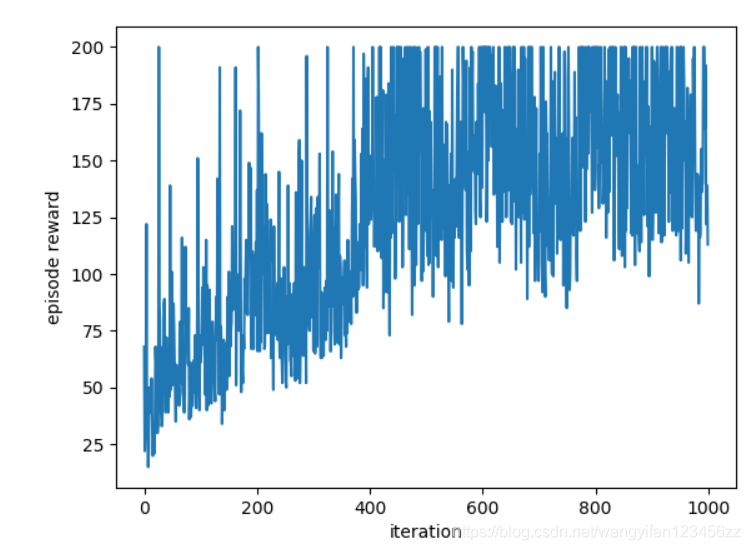
带基线的重要性采样策略梯度算法效果如下
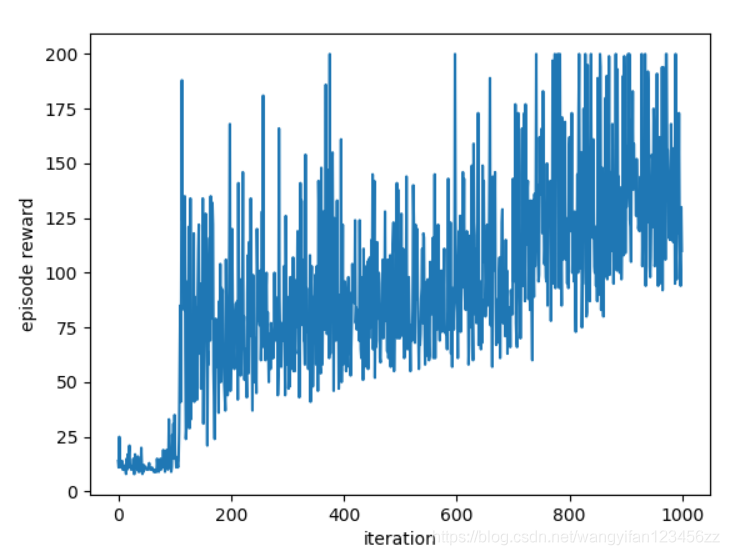
对比结论
策略梯度算法可以分为回合更新和时序差分更新两大类,本文介绍回合更新方法。回合更新方法只能用于回合制任务。回合更新方法没有用到自益,不会引入偏差。但是,这样的回合更新策略梯度方法往往有非常大的方差。



评论(0)
您还未登录,请登录后发表或查看评论