

背景
使用的是一个简单的数据集fisheriris,该数据集数据类别分为3类,setosa,versicolor,virginica。每类植物有50个样本,共150个样本代表150朵花瓣。每个样本有4个属性,分别为花萼长,花萼宽,花瓣长,花瓣宽。其中meas是150*4的矩阵代表着有150个样本每个样本有4个属性描述,species代表着这150个样本的分类。
实验测试
原始的数据集中的标签格式如下所示:
setosa
setosa
versicolor
versicolor
virginica
virginica
为了能够进行在BP神经网络训练时更好的进行处理,首先使用MATLAB将以上字符串标签更改为数字标签,其中setosa对应于数字1,versicolor对应于数字2,virginica对应于数字3。
然后使用MATLAB建立的神经网络结构,其中神经网络的输入值个数为3个,隐含层的个数为4层。神经网络训练参数的设置分别为:最大迭代次数1000次,训练的目标为10-3,学习率设置为0.01。
如图所示为使用MATLAB进行神经网络进行训练之后的回归结果,可以看出预测出的结果大致分成了三个部分,大都距离45度斜线很近。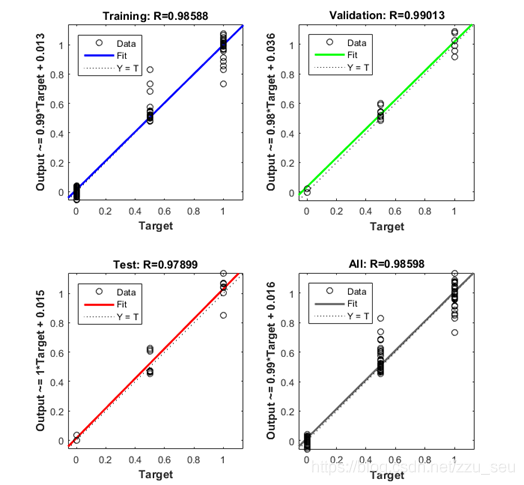
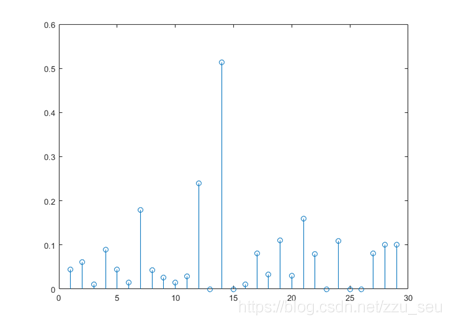
然后对训练后得到的30组结果进行反归一化后,再计算出的标签值与实际标签值的相对误差,画出30组测试集所得出的结果与测试集标签值相对误差的点线图如图所示。从图中我们可以看出,有一组数据结果的误差达到了50%以上,其余的误差大都在20%以下,由此结果是可以取得较高的准确率的。
下图中为对应的计算出的标签值与实际标签值的对比,其中橘色的点为标签的世纪值,蓝色的点为使用BP神经网络计算出的标签值,可以看出在大多数情况下,每组数据的两个点之间的距离是比较接近的。本例中使用计算出的标签值与真实标签值相差30%以内视为预测正确,则图中所示预测正确率为96.67%。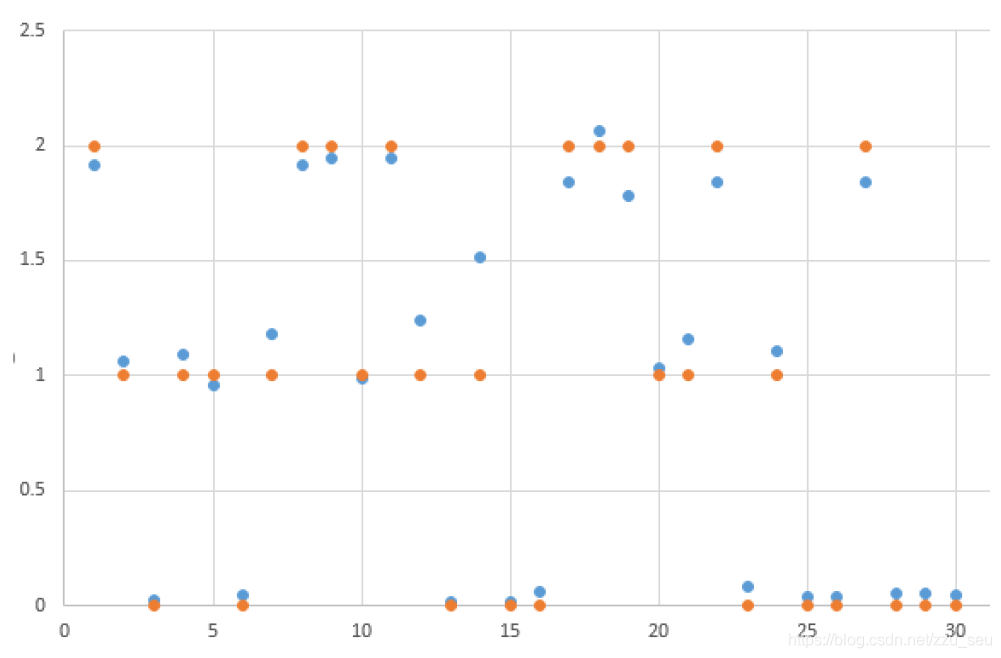
源码
clear all
clc
% 导入数据
load fisheriris.mat
%将标签从字符改变为数字
for i=1:150
temp1 = species(i,1);
if (strcmp(temp1,'setosa'))
label(i,1) = 0;
end
if (strcmp(temp1,'versicolor'))
label(i,1) = 1;
end
if (strcmp(temp1,'virginica'))
label(i,1) = 2;
end
end
% 随机产生训练集和测试集
temp = randperm(size(meas,1));
% 训练集——120个样本
P_train = meas(temp(1:120),:)';
T_train = label(temp(1:120),:)';
% 测试集——30个样本
P_test = meas(temp(121:end),:)';
T_test = label(temp(121:end),:)';
N = size(P_test,2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train,0,1);
p_test = mapminmax('apply',P_test,ps_input);
[t_train, ps_output] = mapminmax(T_train,0,1);
% 创建网络
net = newff(p_train,t_train,9);
%设置训练参数
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-3;
net.trainParam.lr = 0.01;
%训练网络
net = train(net,p_train,t_train);
%仿真测试
t_sim = sim(net,p_test);
% 数据反归一化
T_sim = mapminmax('reverse',t_sim,ps_output);
%相对误差error
error = abs(T_sim - T_test)./T_test;
%决定系数R^2
R2 = (N * sum(T_sim .* T_test) - sum(T_sim) * sum(T_test))^2 / ((N * sum((T_sim).^2) - (sum(T_sim))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
%结果对比
result = [T_test' T_sim' error']
%绘图
figure
plot(1:N,T_test,'b:*',1:N,T_sim,'r-o')
legend('真实标签值','预测结果')
xlabel('测试集')
ylabel('标签')
string = {'结果可视化对比';['R^2=' num2str(R2)]};
title(string)
j = 0;
for i=1:30
err=error(1,i)
if (err>0.3 && err~=Inf)
j=j+1;
end
end
rate = (30-j)/30注:最后一个图是把数据粘贴出去使用Excel画的,所以以上程序执行出的第三个图会和博文中有差异 。



评论(0)
您还未登录,请登录后发表或查看评论