

竞赛任务
在C区放置若干仿真人物,通过模型识别戴眼镜和长头发(过肩)人物的数量,并达到终点进行语音播报:戴眼镜的人数为多少,长头发人物为多少;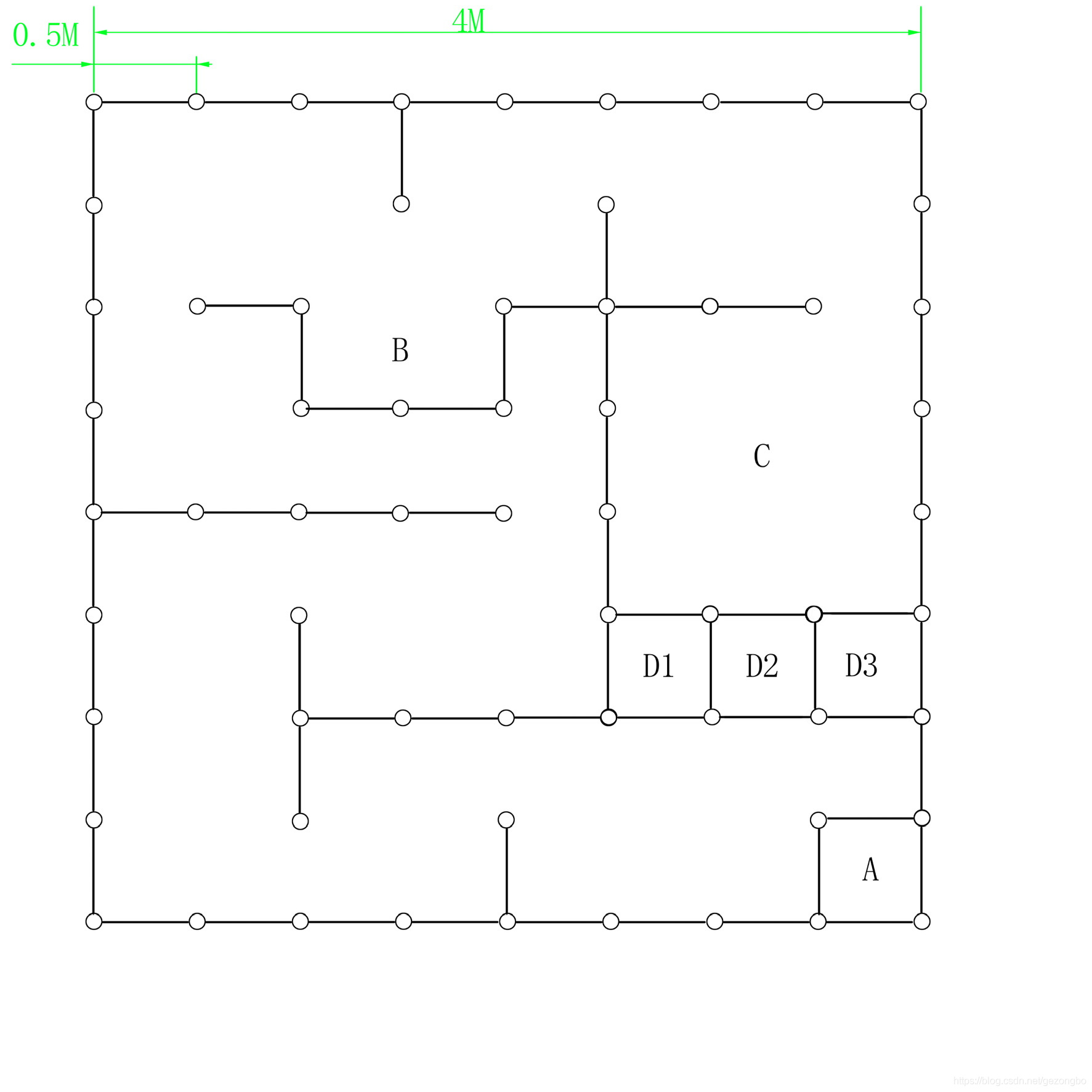

思路
使用目标检测算法,通过收集全身人物照片数据集,并训练模型,进行测试;
数据集采集
每张照片都包括两种特征,有以下四种情况:戴眼镜_长头发;戴眼镜_短头发;不戴眼镜_长头发;不戴眼镜_短头发;
收集满足以上条件的数据各1500张;
数据集标注
标签分为四类:g,ng,l,s;分别表示:戴眼镜,不戴眼镜,长头发,短头发;并对每张图片标注两种类型;标注格式:yolo
模型训练
使用darknet深度学习框架训练模型,使用yolov3-tiny算法训练模型
下载预训练权重:
wget https://pjreddie.com/media/files/yolov3_tiny.weights
./darknet partial ./cfg/yolov3-tiny.cfg ./yolov3-tiny.weights ./yolov3-tiny.conv.15 15
训练模型:
sudo ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15
在yolov3-tiny_10000.weights基础上继续训练:
sudo ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_10000.weights -map
模型会自动保存;
模型测试
./darknet detector test cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_10000.weights data/11.png
测试结果
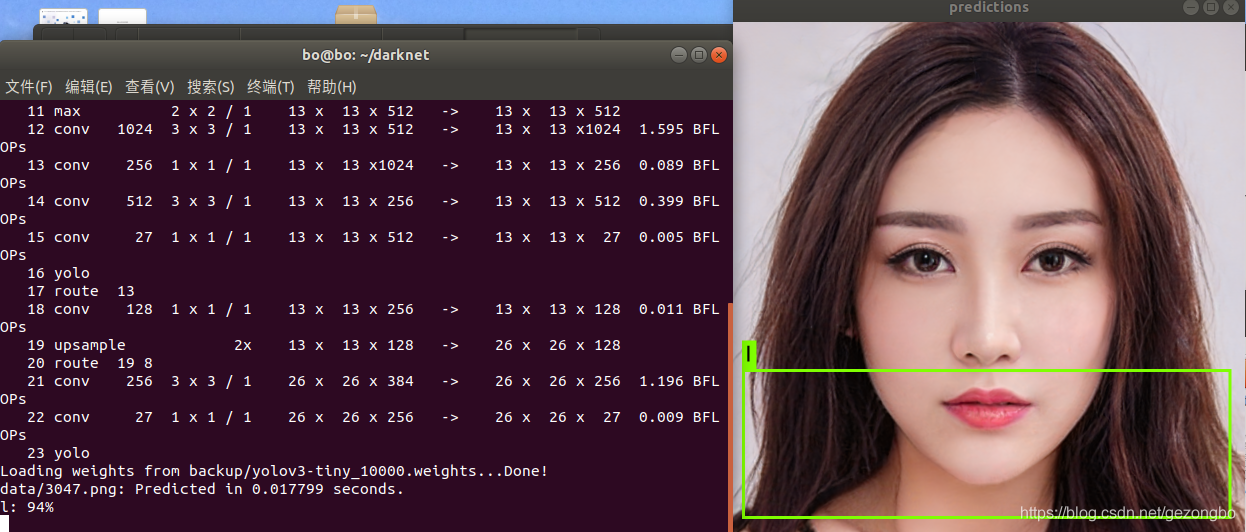
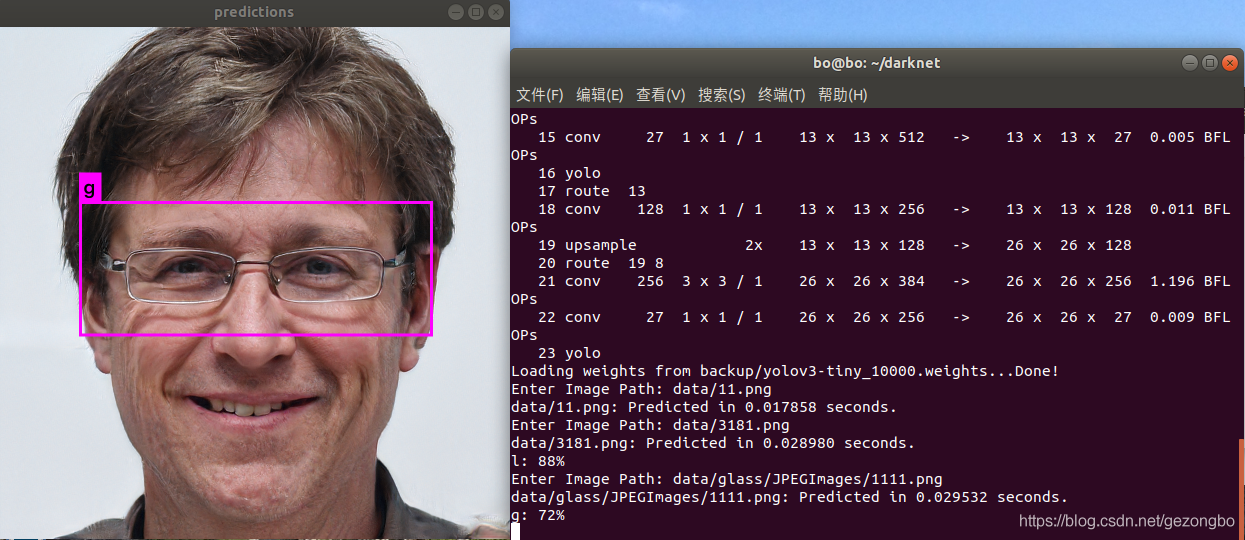
数量统计
分别统计识别戴眼镜和长头发标签的数量,并发送到topic;
语音播报
通过订阅topic,获得戴眼镜和长头发人物数量,通过语音合成进行播报;



评论(1)
您还未登录,请登录后发表或查看评论