

Named Entity Recognition as Dependency Parsing

Paper: https://aclanthology.org/2020.acl-main.577.pdf
Code : https://github.com/juntaoy/biaffine-ner
命名实体识别(name Entity Recognition, NER)是自然语言处理中的一项基本任务,它涉及到识别表示实体引用的文本范围。NER研究通常只关注平面实体(平面NER),忽略了实体引用可以嵌套的事实,比如: [Bank of [China]] 。在本文中,我们利用基于图的依赖解析的思想,通过一个biaffine模型来提供我们的模型对输入的全局视图。biaffine模型对句子的开始和结束标记进行评分,我们使用这些标记来探索所有的跨度,因此该模型能够准确地预测命名实体。通过对8个语料库的评估,我们表明该模型在嵌套和平面NER上都能很好地工作,并且在所有语料库上都实现了SoTA性能,准确率高达2.2个百分点。
介绍
嵌套实体是包含对其他命名实体的引用的命名实体,如 [Bank of [China]],其中 [China] 和 [Bank of China]这样的嵌套实体经常出现在ACE 2004、ACE 2005和GENIA等数据集中是命名实体。尽管更广泛使用的集合,如CONLL 2002、2003和ONTONOTES只包含所谓的平面命名实体,而嵌套实体被忽略。
目前的SoTA模型都采用了神经网络架构,没有手工制作的特征,这使得它们更能适应不同的任务、语言和领域。本文引入了一种在一个系统中同时处理两种类型网元的方法。对于依赖解析,系统预测每个标记的头,并分配一个关系给头-子对。在这项工作中,我们将晚期的NER重新定义为识别起始和结束索引的任务,以及为这些对定义的跨度分配一个类别。。我们的系统在多层BiLSTM的基础上使用biaffine模型来为句子中所有可能的跨度分配分数。之后,我们不再构建依赖树,而是根据分数对候选跨度进行排序,并返回符合平面或嵌套NER约束的排名最高的跨度。我们在三个嵌套网上基准(ACE 2004,ACE 2005,Genia)和五个Flat Ner Corpora(Conll 2002(荷兰语,西班牙语)Conll 2003(英文,GER-)和Onototes)上进行了评估。结果表明,我们的系统在所有三个嵌套的NER语料库上实现了SoTA结果,在所有五个扁平的NER语料库上,与之前的SoTA相比,有高达2.2%的绝对百分点的实质性收益。
相关工作
Flat Named Entity Recognition. 大多数平面NER模型是基于序列标记方法。Collobert等人(2011)引入了一种中性NER模型,该模型使用cnn对token进行编码,并结合CRF层进行分类。许多其他神经系统遵循这种方法,但使用lstm编码输入和CRF进行预测(Lample等人,2016;Ma and Hovy, 2016;Chiu and Nichols, 2016)。这些后一种模型后来被扩展到使用环境依赖的嵌入,如ELMo (Peters等人,2018),Clark等人(2018)非常成功地将交叉视角训练(CVT)与多任务学习相结合。此方法对包括NER的许多NLP应用产生令人印象深刻的收益。Devlin等人(2019)发明了Bert,用于预训练语言模型的双向变压器架构。BERT及其兄弟姐妹提供了更好的语言模型,可以再次转化为NER的更高分数。
Lample等人(2016)使用Stack-LSTM将NER转换为基于转换的依赖解析。他们与LSTM-CRF模型进行了比较,结果证明LSTM-CRF模型是一个非常强的基线。他们的基于转换的系统使用两个转换(shift和reduce)来标记命名实体并处理平面NER,而我们的系统被设计为处理嵌套和平面实体。
Nested Named Entity Recognition 嵌套NER的早期工作,特别是受到GENIA语料库的推动,包括(Shen等人,2003;击败-米亚历克斯和格罗弗,2007;芬克尔和曼宁,2009年)。Finkel和Manning(2009)也提出了一种基于选区分析的方法。在过去的几年里,我们看到越来越多的神经模型-靶向嵌套NER。Ju等人(2018)提出了一种LSTM-CRF模型来预测嵌套命名实体。他们的算法迭代地继续,直到没有其他实体被预测。 Lin等人(2019)分两步解决这个问题:他们首先检测实体头部,然后他们推断实体边界以及命名实体的类别。Strakov等人(2019)通过序列到序列的模型来标记嵌套的命名实体,探索基于上下文的嵌入组合,如ELMo、BERT和Flair。Zheng等人(2019)使用边界感知网络来求解嵌套的NER。与我们的工作类似,索拉博和Miwa(2018)通过连接LSTMs输出的起始和结束位置,详尽地枚举所有可能的跨度,直到一个定义的长度,然后使用它来计算每个跨度的得分。除了不同的网络和词嵌入配置之外,他们的模型和我们的模型的主要区别在于使用了双仿射模型。由于biaffine模型,我们得到了一个句子的全局视图,而索拉博和Miwa(2018)将可能开始和结束位置的lstm的输出连接到一个不同的长度。doza和Manning(2017)证明了biaffine映射比仅仅串联成对的LSTM输出表现得更好。
方法
我们的模型受到doza和Manning(2017)的依赖解析模型的启发。我们使用单词嵌入和字符嵌入作为输入,并将输出输入到BiLSTM中,最后输入到biaffine分类器。
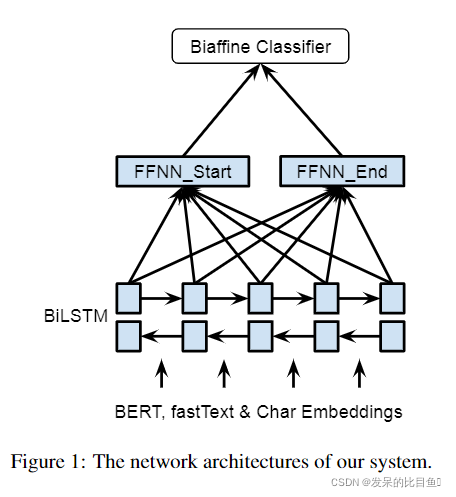
图1显示了该体系结构的概述。为了对单词进行编码,我们同时使用了BERTLarge和fast-Text embedding (Bojanowski等人,2016)。对于BERT,我们遵循(Kantor and Glober-
son, 2019) 的方法,以获取目标token的上下文依赖嵌入,每侧有64个周围的token。对于基于字符的单词嵌入,我们使用一个CNN来编码符号的字符。单词和基于字符的单词嵌入的连接被输入到BiLSTM中,以获得单词表示形式(x)。
从BILSTM获取单词表示后,我们将两个单独的FFNNS应用于跨度的开始/结束创建不同的表示(HS / HS)。使用不同表示的跨度的开始/结尾允许系统学会单独识别西班牙语的开始/结尾。与直接使用LSTM输出的模型相比,这提高了准确性,因为实体的开始和结束的上下文是不同的。最后,我们在句子中使用双重内模型来创建一个L×L×C评分张量(RM),其中L是句子的长度,C是NER类别+ 1(非实体)的数量。我们计算span i的分数:
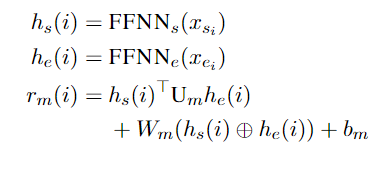
其中si和ei是span i的起始和结束指标。Um是一个d×c×d张量,Wm是2d×c矩阵和bm是偏置。
张量rm在si≤ei(实体的起始点在其结束点之前)约束下,为所有可能构成命名实体的空间提供分数。我们给每个span空间分配一个NER类别
y:
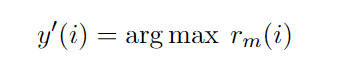
然后,我们按照类别分数(rm(iy′))降序对所有具有类别而非非实体的跨度进行排序,并应用后续处理约束:对于嵌套的NER,只要一个实体不与排名更高的实体的边界冲突,它就会被选中。我们表示实体与另一个实体边界冲突j如果si<sj≤ei<ej或sj<si≤ej<ei,如中国银行,银行实体边界冲突与实体的中国银行,所以只有跨度类别选择得分就越高。对于平面NER,我们应用了另一个约束,其中任何包含或位于排序前的实体的实体将不会被选中。我们的命名实体识别器的学习目标是将一个正确的类别(包括非实体)标记到每个有效区间。因此,它是一个多类分类问题,我们用软最大交叉熵优化我们的模型:

实验
Data Set.
我们在嵌套和平面NER上评估我们的系统,对于嵌套NER任务,我们使用ACE 20042, ACE 20053和GENIA (Kim et al, 2003)语料库;对于平面NER,我们在CONLL 2002 (Tjong Kim Sang, 2002)、CONLL 2003 (Tjong Kim Sang and De Meulder, 2003)和ONTONOTES4语料库上测试我们的系统。
对于ACE 2004和ACE 2005,我们遵循Lu和Roth(2015)和Muis和Lu(2017)的相同设置,将数据分别分割为80%、10%、10%用于训练、验证和测试集。为了进行公平的比较,我们也使用了与Lu和Roth(2015)中相同的文件。
对于Genia,我们使用Genia V3.0.2语料库。我们在Finkel和Manning(2009)和Lu和Roth(2015)的相同设置之后预处理数据集,并使用90%/ 10%训练和测试。对于此评估,由于我们没有开发集,我们训练我们的系统50epoch并评估最终模型。
对于2002年和2003年的Conll 2003,我们评估了所有四种语言(英语,德语,荷兰语和西班牙语)。
对于Ontonotes,我们评估英语语料库,并关注Strubell等。(2017)使用同样的训练,,如CORCREFATE解析(Pradhan等,2012)。
Evaluation Metric. 我们报告所有评估的召回率、准确性和F1得分。当边界和类别都被正确预测时,命名实体被认为是正确的。
Hyperparameters
我们对所有的实验使用了统一的设置,表1显示了我们系统的超参数

嵌套NER结果
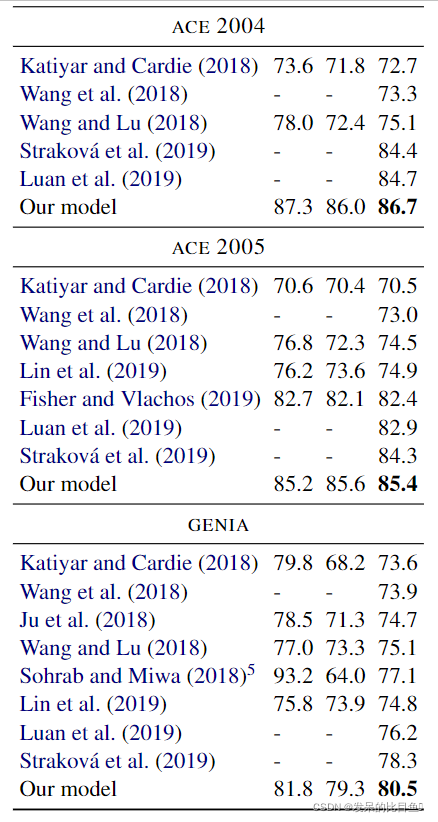
使用嵌套网的约束,我们首先在嵌套命名实体语料库上进行评估:ACE 2004,ACE 2005和Genia。表2显示了结果。ACE 2004和ACE 2005都包含7个ner类别,并且具有相对高的嵌套实体比率(大约1/3的命名实体嵌套)。我们的结果分别优于前面的SOTA系统2%(ACE 2004)和1.1%(ACE 2005)。Genia与ACE 2004和ACE 2005的不同,并使用五种医学类别,如DNA或RNA。对于Genia Corpus,我们的系统达到了80.5%的F1得分,并使SOTA提升了2.2%。我们的假设是,对于GENIA来说,较高的准确性是由于我们的结构预测方法,以及序列到序列模型更多地依赖于语言模型嵌入,而语言模型嵌入对于DNA、RNA等类别的信息较少。我们的系统在嵌套NER的三个语料库上都取得了SoTA结果,并很好地证明了结构预测比序列标记方法的优势。
平面NER结果

我们在Flat Ner的五层(Conll 2002(荷兰语,西班牙语),2003年(En-Glish,德语)和Onototes上评估我们的系统。与大多数将平坦的系统视为序列La-Belling任务,我们的系统通过考虑所有可能的跨度和排列它们来预测命名实体。ONTONOTES语料库由来自7个不同领域的文档组成,并用18个按粒度命名的实体类别进行了注释。在这个语料库中预测命名实体比在CONLL 2002和CONLL 2003中更难。这些语料库使用粗粒度的命名实体类别(只有4个类别)。序列到序列模型通常在Conll 2003英语语料库上执行更好(见表3),例如,参见表3)。相比之下,我们的系统对类别的领域和粒度不太敏感。如表3所示,我们的系统在ONTONOTES语料库上的F1得分为91.3%,与我们在CONLL 2003语料库上的性能(93.5%)非常接近。在多语言数据上,我们的系统为德国的F1分数为86.4%,西班牙语的90.3%,荷兰语93.5%。我们的系统优于以前的SOTA,在牛顿,西班牙语,GER-MAN和荷兰语料库中,较大的余量较高的2.1%,1.5%,1.3%和1%,略高于英语数据集的SOTA。此外,我们还在修改后的德国数据上测试了我们的系统,并与Akbik等人(2018)的模型进行了比较。与他们的系统相比,我们的系统再次获得了2%的实质性收益。
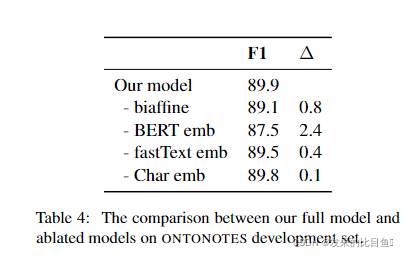
结论
在本文中,我们将NER重新定义为结构化预测任务,并对嵌套和平面NER采用了SoTA依赖解析方法。我们的系统使用上下文嵌入作为输入到一个多层BiLSTM。我们采用了一种biaffine模型来分配一个句子中所有跨度的分数。进一步的约束用于预测嵌套或平面命名实体。我们用8个命名实体语料库对系统进行了评测。结果表明,该系统对8个语料库均实现了SoTA检索。我们证明了先进的结构化预测技术对嵌套和平面NER都有实质性的改进。
")


评论(0)
您还未登录,请登录后发表或查看评论