

一、基本概念
关联规则挖掘:在交易数据、关系数据或其他信息载体中,查找
存在于项目集合或对象集合之间的频繁模式、关
联、相关性、或因果结构。
频繁模式:频繁地出现在数据集中的模式。
假定某超时销售的商品包括:bread,beer,cake,cream,milk,tea。

项目与项集:设I = {i1,i2,i3,… ,im}是m个不同项目的集合,其中每个ik(k = 1,2,3,…,m)都是一个项目(item),项目的集合称为项集(itemset),项集中项目的个数称为项集的长度,长度为k的项集称为k-项集。例如,{bread,cream,milk,tea}是一个4项集。
交易:每一笔交易T都是项目全集的子集。每一笔交易都有一个交易号,TID。交易的全体构成D,交易数据库。
支持度:给定一个项集A,支持度表示在交易数据库D中,同时出现A的概率: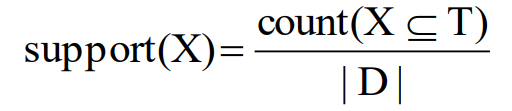
例如:设A = {bread,tea},则support(A) = 5 / 10 = 0.5
支持度描述了项集A的重要性
项集的最小支持度与频繁集:
有用户或者领域专家定义最小支持度,当项集A的支持度不小于最小支持度,则称A为频繁项集。
关联规则:有关联的规则,描述成一种蕴含式。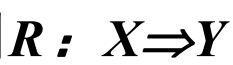
其中X称为前件,Y称为后件,支持度和置信度是伴随着关联规则出现的。关联规则的置信度是交易数据库D中同时包含X和Y的交易数的频率。
置信度:表示关联规则前件出现时,后件出现的概率。 关联规则的最小支持度和最小可信度:关联规则的最小支持度就是衡量频繁项集的最小支持度,关联规则的最小置信度表示关联规则需要满足的最低可靠性。
关联规则的最小支持度和最小可信度:关联规则的最小支持度就是衡量频繁项集的最小支持度,关联规则的最小置信度表示关联规则需要满足的最低可靠性。
如果某个关联规则同时满足最小支持度阈值和最小置信度阈值,则认为这个关联规则是有趣的。同时也称这个规则是强关联规则。
二、关联规则挖掘步骤
1.两个关键步骤:
(1)从数据集中找出所有频繁项集。通常先找频繁1项集,再找频繁2项集,依次类推。
(2)从找到所有长度大于2的频繁k项集中产生关联规则。如果产生的规则的置信度和支持度满足最小支持度和最小置信度,则称此规则为强关联规则。
2.如何减少产生的关联规则数量:
因为从数据集中产生频繁项集经常出现的问题是会产生大量满足最小支持度阈值的频繁项集。(因为当一个项集是频繁时,其子集也是频繁的。)所以分析关联规则会花费大量的时间资源和空间资源。实际运用中不需要分析所有满足条件的频繁项集和关联规则。
超项集:若一个集合S2的每一个元素,S1中都有,而且S1中可能含有S2中不存在的元素,则称S1是S2的超项集。所以S2是S1的子集。
闭频繁集:对于一个项集X,如果不存在X的超项集Y,使得X和Y的支持度相等,而且X是频繁的,则称X是闭频繁集
极大频繁集:对于一个频繁集X,如果X的任意一个超项集都是非频繁的,则称X是极大频繁集。即X再扩充就不是频繁集。
一个实例:
最小支持度设置为3。
所以A,B,C,AB,BC都是频繁集,AC,ABC是非频繁集。
极大频繁集:A的超项集AB是频繁的,所以A不是极大频繁集。B的超项集AB是频繁的,所以B不是极大频繁集。C的超项集BC是频繁的,所以C不是极大频繁集。AB只有一个超项集–ABC,ABC是非频繁的,所以AB是极大频繁集。AC是非频繁集,也不是极大频繁集。BC只有一个超项集–ABC,ABC是非频繁的,所以BC是极大频繁集。ABC是非频繁的,所以也不是极大频繁集。
闭频繁集:A的超项集AB的支持度和A的支持度相等,所以A不是闭频繁集。B的所有超项集的支持度和B的支持度都不相等,所以B是闭频繁集。C的超项集BC的支持度和C的支持度相等,所以C不是闭频繁集。
依次类推…。可以得到上图结果。
三、Aprior算法
该算法采用广度优先的搜索策略,自底向上的遍历,遵循首先产生候选集进而获得频繁项集的思路。该算法适用于数据集稀疏,事物宽度较小,频繁模式较短,最小支持度较高的环境中。而对于稠密数据和长频繁模式,由于候选集占据大量内存,计算成本增加,数据集的遍历次数增大,因为该算法的性能下降。
反单调性原理:如果一个项集是频繁的,那么它的所有子集也是频繁的,即是如果一个项集是非频繁的,那么它的所有超集也一定是非频繁的。
核心思想:首先扫描数据集,统计数据集中交易的数量和各个不同1项集出现的次数,然后根据最小支持度获得所有的频繁1项集L1,然后利用L1查找频繁2项集L2,如此继续,直到不再有新的频繁项集被找到。生成候选集归纳起来两个步骤
(1)连接步,为找Lk(频繁k项集),通过将Lk-1与自身连接产生k项集,该k项集记作Ck,但是两两自连接时,只能对只差最后一个项目不同的项集进行连接。
(2)剪枝步,根据反单调性原理,对于一个候选k项集Ck,如果它的一个子集是非频繁的,那么Ck也是非频繁的,将其剪枝掉,然后对生成的候选集进行计数,判断其是否不下雨最小支持度阈值。
一个实例:假设已经找到的频繁3项集L3 = {abc,abd,acd,ace,bcd},现在要求找频繁4项集。
首先连接步:
L3与L3自连接,{abc}_{abd}得到{abcd},{acd}_{ace}得到{acde},候选集为{abcd,acde}。
然后剪枝步:
由于{acde}的子集{ade}不在频繁3项集中,所以{ade}是不频繁的,所以{acde}也是不频繁的,将其剪枝。然后扫描数据库,对候选集进行计数,判断其是否不小于最小支持度阈值,然后找出频繁4项集。
由频繁项集产生关联规则:
(1)对于每个频繁项集I,产生I的所有非空子集
(2)对于I的每个非空子集s和其补集(l-s),如果条件概率大于最小置信度阈值,则输出规则。
缺陷:
(1)产生大量的候选集。
(2)需要重复扫描数据库多次。
四、 关联规则有效性评估:
强关联规则不一定是有趣的,因为如果一条规则的后件支持度本来就很高(大于最小置信度阈值),那么即使计算出来规则的置信度大于最小最小置信度阈值,也并不能说明这条规则的可用性。
正关联规则兴趣度:
规则的兴趣度 = 规则的置信度 - 后件事物数据库中的支持度
如果前件对后件没有任何影响,那么包含前件的交易中同时包含后件的比例就应该等于后件在事物数据库中的比例,即该规则的置信度为0。
如果兴趣度很高,说明前件的存在会促进后件发生的概率。
如果兴趣度是一个绝对值很大的负数,说明前件会抑制后件发生的概率。
关联规则相关度评估:
真正强关联规则的方法:
correlation是指项集A和项集C的相关度指标。
简单的使用支持度-置信度框架进行评估关联规则模式是不够的,要根据不同的问题,数据本身的特点选择引入其他度量。
相关度指标有以下几种:
1.提升度度量: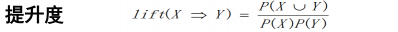
表示含有X的条件下同时含有Y的概率与Y概率的比值。
如果lift的值小于1,说明X的出现和Y的出现是负相关。
如果lift的值大于1,说明X的出现和Y的出现是正相关。
如果lift的值等于1,说明X和Y是独立的。
2.卡方度量
3.全置信度度量: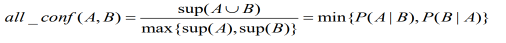
4.最大置信度度量:
5.Kluc度量: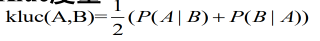
6.余弦度量: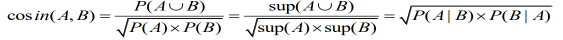
3,4,5,6这四种度量方式,范围都是【0,1】,值越大,关系越紧密。
不平衡比: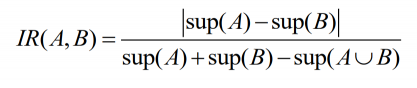
指的是关联规则的前件和后件所包含的项集A和B在交易数据库中被包含的不平衡程度。
分子是项集A和B的支持度绝对值之差,分母是包含A或B的事物数。
如果A和B在数据集中被包含的程度基本相同,不平衡之比为0,否则两者之差越大,不平衡比就越大。
零事物:不包含所考察规则的前件和后件项集的事物。
零不变性:指规则的度量独立于零事物之外,即不受零事物的影响。
后面四种度量方式都具有零不变性。



评论(0)
您还未登录,请登录后发表或查看评论